 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePLUM: Adapting Pre-trained Language Models for Industrial-scale Generative Recommendations
Oct 09, 2025Large Language Models (LLMs) pose a new paradigm of modeling and computation for information tasks. Recommendation systems are a critical application domain poised to benefit significantly from the sequence modeling capabilities and world knowledge inherent in these large models. In this paper, we introduce PLUM, a framework designed to adapt pre-trained LLMs for industry-scale recommendation tasks. PLUM consists of item tokenization using Semantic IDs, continued pre-training (CPT) on domain-specific data, and task-specific fine-tuning for recommendation objectives. For fine-tuning, we focus particularly on generative retrieval, where the model is directly trained to generate Semantic IDs of recommended items based on user context. We conduct comprehensive experiments on large-scale internal video recommendation datasets. Our results demonstrate that PLUM achieves substantial improvements for retrieval compared to a heavily-optimized production model built with large embedding tables. We also present a scaling study for the model's retrieval performance, our learnings about CPT, a few enhancements to Semantic IDs, along with an overview of the training and inference methods that enable launching this framework to billions of users in YouTube.
RoboMatch: A Mobile-Manipulation Teleoperation Platform with Auto-Matching Network Architecture for Long-Horizon Manipulation
Sep 10, 2025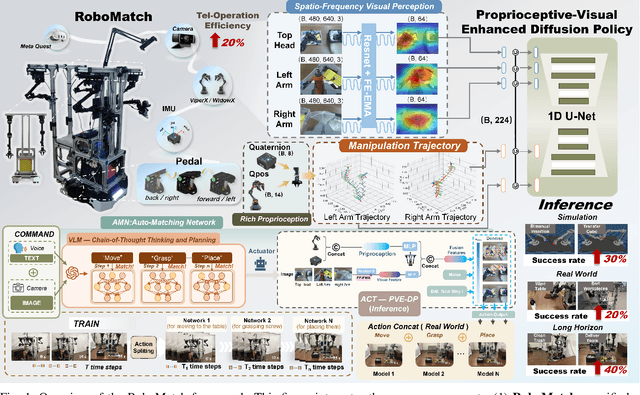

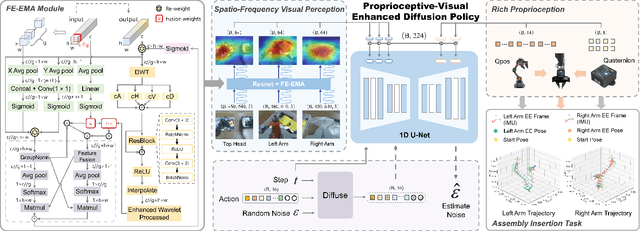
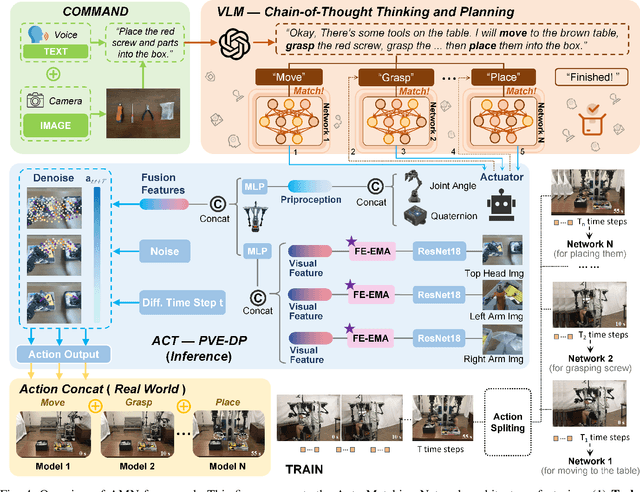
This paper presents RoboMatch, a novel unified teleoperation platform for mobile manipulation with an auto-matching network architecture, designed to tackle long-horizon tasks in dynamic environments. Our system enhances teleoperation performance, data collection efficiency, task accuracy, and operational stability. The core of RoboMatch is a cockpit-style control interface that enables synchronous operation of the mobile base and dual arms, significantly improving control precision and data collection. Moreover, we introduce the Proprioceptive-Visual Enhanced Diffusion Policy (PVE-DP), which leverages Discrete Wavelet Transform (DWT) for multi-scale visual feature extraction and integrates high-precision IMUs at the end-effector to enrich proprioceptive feedback, substantially boosting fine manipulation performance. Furthermore, we propose an Auto-Matching Network (AMN) architecture that decomposes long-horizon tasks into logical sequences and dynamically assigns lightweight pre-trained models for distributed inference. Experimental results demonstrate that our approach improves data collection efficiency by over 20%, increases task success rates by 20-30% with PVE-DP, and enhances long-horizon inference performance by approximately 40% with AMN, offering a robust solution for complex manipulation tasks.
Non-Federated Multi-Task Split Learning for Heterogeneous Sources
May 31, 2024With the development of edge networks and mobile computing, the need to serve heterogeneous data sources at the network edge requires the design of new distributed machine learning mechanisms. As a prevalent approach, Federated Learning (FL) employs parameter-sharing and gradient-averaging between clients and a server. Despite its many favorable qualities, such as convergence and data-privacy guarantees, it is well-known that classic FL fails to address the challenge of data heterogeneity and computation heterogeneity across clients. Most existing works that aim to accommodate such sources of heterogeneity stay within the FL operation paradigm, with modifications to overcome the negative effect of heterogeneous data. In this work, as an alternative paradigm, we propose a Multi-Task Split Learning (MTSL) framework, which combines the advantages of Split Learning (SL) with the flexibility of distributed network architectures. In contrast to the FL counterpart, in this paradigm, heterogeneity is not an obstacle to overcome, but a useful property to take advantage of. As such, this work aims to introduce a new architecture and methodology to perform multi-task learning for heterogeneous data sources efficiently, with the hope of encouraging the community to further explore the potential advantages we reveal. To support this promise, we first show through theoretical analysis that MTSL can achieve fast convergence by tuning the learning rate of the server and clients. Then, we compare the performance of MTSL with existing multi-task FL methods numerically on several image classification datasets to show that MTSL has advantages over FL in training speed, communication cost, and robustness to heterogeneous data.
Fractal Gripper: Adaptive manipulator with mode switching
Feb 25, 2024


Although the multi-jointed underactuated manipulator is highly dexterous, its grasping capacity does not match that of the parallel jaw gripper. This work introduces a fractal gripper to enhance the grasping capacity of multi-joint underactuated manipulators, preserving their passive clamping features. We describe in detail the working principle and manufacturing process of the fractal gripper. This work, inspired by the 'Fractal Vise' structure, resulted in the invention of a fractal gripper with mode switching capabilities. The fractal gripper inherits the inherent adaptive properties of the fractal structure and realizes the self-resetting function by integrating spring into the original design, thereby enhancing the efficiency of object grasping tasks. The fractal gripper prevents object damage by distributing pressure evenly and applying it at multiple points through its fractal structure during closure. Objects of various shapes are effectively grasped by the fractal gripper, which ensures a safe and secure grasp. The superior performance was provided by the force distribution characteristics of the fractal gripper. By applying the flexible polymer PDMS, which possesses superior elasticity, to the fractal structure's wrapping surface, potential scratching during grasping is effectively prevented, thus protecting the object's geometric surface. Grab experiments with objects of diverse shapes and sizes confirm fractal gripper multi-scale adaptability and superior grasping stability.
A Generative Machine Learning Model for Material Microstructure 3D Reconstruction and Performance Evaluation
Feb 24, 2024



The reconstruction of 3D microstructures from 2D slices is considered to hold significant value in predicting the spatial structure and physical properties of materials.The dimensional extension from 2D to 3D is viewed as a highly challenging inverse problem from the current technological perspective.Recently,methods based on generative adversarial networks have garnered widespread attention.However,they are still hampered by numerous limitations,including oversimplified models,a requirement for a substantial number of training samples,and difficulties in achieving model convergence during training.In light of this,a novel generative model that integrates the multiscale properties of U-net with and the generative capabilities of GAN has been proposed.Based on this,the innovative construction of a multi-scale channel aggregation module,a multi-scale hierarchical feature aggregation module and a convolutional block attention mechanism can better capture the properties of the material microstructure and extract the image information.The model's accuracy is further improved by combining the image regularization loss with the Wasserstein distance loss.In addition,this study utilizes the anisotropy index to accurately distinguish the nature of the image,which can clearly determine the isotropy and anisotropy of the image.It is also the first time that the generation quality of material samples from different domains is evaluated and the performance of the model itself is compared.The experimental results demonstrate that the present model not only shows a very high similarity between the generated 3D structures and real samples but is also highly consistent with real data in terms of statistical data analysis.
A Lyapunov-Based Methodology for Constrained Optimization with Bandit Feedback
Jun 09, 2021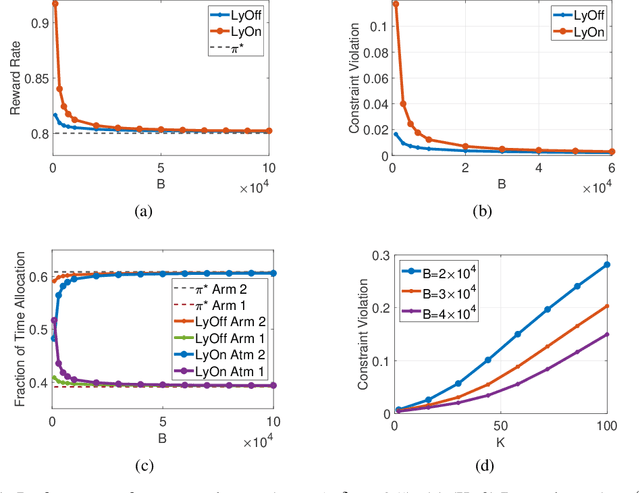
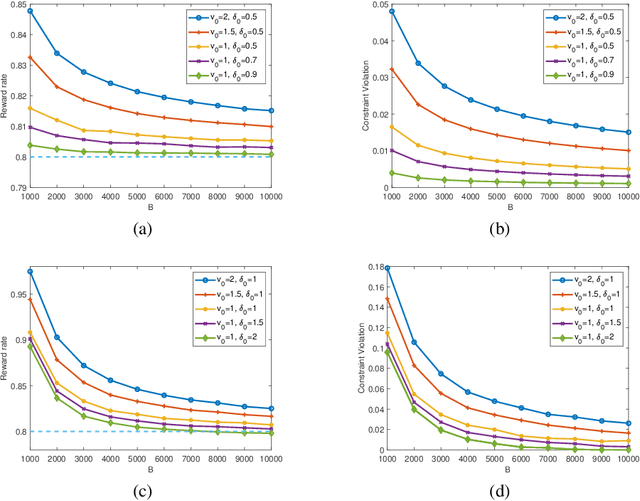
In a wide variety of applications including online advertising, contractual hiring, and wireless scheduling, the controller is constrained by a stringent budget constraint on the available resources, which are consumed in a random amount by each action, and a stochastic feasibility constraint that may impose important operational limitations on decision-making. In this work, we consider a general model to address such problems, where each action returns a random reward, cost, and penalty from an unknown joint distribution, and the decision-maker aims to maximize the total reward under a budget constraint $B$ on the total cost and a stochastic constraint on the time-average penalty. We propose a novel low-complexity algorithm based on Lyapunov optimization methodology, named ${\tt LyOn}$, and prove that it achieves $O(\sqrt{B\log B})$ regret and $O(\log B/B)$ constraint-violation. The low computational cost and sharp performance bounds of ${\tt LyOn}$ suggest that Lyapunov-based algorithm design methodology can be effective in solving constrained bandit optimization problems.
Support Union Recovery in Meta Learning of Gaussian Graphical Models
Jun 22, 2020



In this paper we study Meta learning of Gaussian graphical models. In our setup, each task has a different true precision matrix, each with a possibly different support (i.e., set of edges in the graph). We assume that the union of the supports of all the true precision matrices (i.e., the true support union) is small in size, which relates to sparse graphs. We propose to pool all the samples from different tasks, and estimate a single precision matrix by $\ell_1$-regularized maximum likelihood estimation. We show that with high probability, the support of the estimated single precision matrix is equal to the true support union, provided a sufficient number of samples per task $n \in O((\log N)/K)$, for $N$ nodes and $K$ tasks. That is, one requires less samples per task when more tasks are available. We prove a matching information-theoretic lower bound for the necessary number of samples, which is $n \in \Omega((\log N)/K)$, and thus, our algorithm is minimax optimal. Synthetic experiments validate our theory.
Outline Objects using Deep Reinforcement Learning
Apr 20, 2018
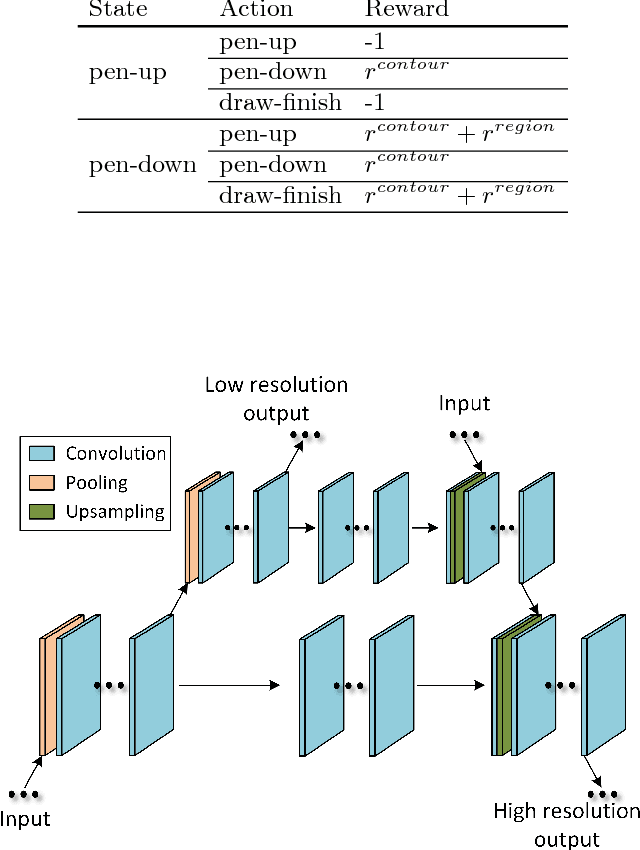
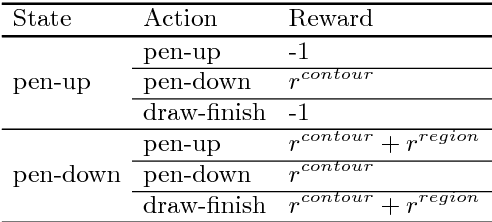
Image segmentation needs both local boundary position information and global object context information. The performance of the recent state-of-the-art method, fully convolutional networks, reaches a bottleneck due to the neural network limit after balancing between the two types of information simultaneously in an end-to-end training style. To overcome this problem, we divide the semantic image segmentation into temporal subtasks. First, we find a possible pixel position of some object boundary; then trace the boundary at steps within a limited length until the whole object is outlined. We present the first deep reinforcement learning approach to semantic image segmentation, called DeepOutline, which outperforms other algorithms in Coco detection leaderboard in the middle and large size person category in Coco val2017 dataset. Meanwhile, it provides an insight into a divide and conquer way by reinforcement learning on computer vision problems.