 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRelaxing Anchor-Frame Dominance for Mitigating Hallucinations in Video Large Language Models
Apr 14, 2026Recent Video Large Language Models (Video-LLMs) have demonstrated strong capability in video understanding, yet they still suffer from hallucinations. Existing mitigation methods typically rely on training, input modification, auxiliary guidance, or additional decoding procedures, while largely overlooking a more fundamental challenge. During generation, Video-LLMs tend to over-rely on a limited portion of temporal evidence, leading to temporally imbalanced evidence aggregation across the video. To address this issue, we investigate a decoder-side phenomenon in which the model exhibits a temporally imbalanced concentration pattern. We term the frame with the highest aggregated frame-level attention mass the anchor frame. We find that this bias is largely independent of the input video and instead appears to reflect a persistent, model-specific structural or positional bias, whose over-dominance is closely associated with hallucination-prone generation. Motivated by this insight, we propose Decoder-side Temporal Rebalancing (DTR), a training-free, layer-selective inference method that rebalances temporal evidence allocation in middle-to-late decoder layers without altering visual encoding or requiring auxiliary models. DTR adaptively calibrates decoder-side visual attention to alleviate temporally imbalanced concentration and encourage under-attended frames to contribute more effectively to response generation. In this way, DTR guides the decoder to ground its outputs in temporally broader and more balanced video evidence. Extensive experiments on hallucination and video understanding benchmarks show that DTR consistently improves hallucination robustness across diverse Video-LLM families, while preserving competitive video understanding performance and high inference efficiency.
Lightweight LLM Agent Memory with Small Language Models
Apr 09, 2026Although LLM agents can leverage tools for complex tasks, they still need memory to maintain cross-turn consistency and accumulate reusable information in long-horizon interactions. However, retrieval-based external memory systems incur low online overhead but suffer from unstable accuracy due to limited query construction and candidate filtering. In contrast, many systems use repeated large-model calls for online memory operations, improving accuracy but accumulating latency over long interactions. We propose LightMem, a lightweight memory system for better agent memory driven by Small Language Models (SLMs). LightMem modularizes memory retrieval, writing, and long-term consolidation, and separates online processing from offline consolidation to enable efficient memory invocation under bounded compute. We organize memory into short-term memory (STM) for immediate conversational context, mid-term memory (MTM) for reusable interaction summaries, and long-term memory (LTM) for consolidated knowledge, and uses user identifiers to support independent retrieval and incremental maintenance in multi-user settings. Online, LightMem operates under a fixed retrieval budget and selects memories via a two-stage procedure: vector-based coarse retrieval followed by semantic consistency re-ranking. Offline, it abstracts reusable interaction evidence and incrementally integrates it into LTM. Experiments show gains across model scales, with an average F1 improvement of about 2.5 on LoCoMo, more effective and low median latency (83 ms retrieval; 581 ms end-to-end).
Immunizing 3D Gaussian Generative Models Against Unauthorized Fine-Tuning via Attribute-Space Traps
Apr 06, 2026Recent large-scale generative models enable high-quality 3D synthesis. However, the public accessibility of pre-trained weights introduces a critical vulnerability. Adversaries can fine-tune these models to steal specialized knowledge acquired during pre-training, leading to intellectual property infringement. Unlike defenses for 2D images and language models, 3D generators require specialized protection due to their explicit Gaussian representations, which expose fundamental structural parameters directly to gradient-based optimization. We propose GaussLock, the first approach designed to defend 3D generative models against fine-tuning attacks. GaussLock is a lightweight parameter-space immunization framework that integrates authorized distillation with attribute-aware trap losses targeting position, scale, rotation, opacity, and color. Specifically, these traps systematically collapse spatial distributions, distort geometric shapes, align rotational axes, and suppress primitive visibility to fundamentally destroy structural integrity. By jointly optimizing these dual objectives, the distillation process preserves fidelity on authorized tasks while the embedded traps actively disrupt unauthorized reconstructions. Experiments on large-scale Gaussian models demonstrate that GaussLock effectively neutralizes unauthorized fine-tuning attacks. It substantially degrades the quality of unauthorized reconstructions, evidenced by significantly higher LPIPS and lower PSNR, while effectively maintaining performance on authorized fine-tuning.
RCP: Representation Consistency Pruner for Mitigating Distribution Shift in Large Vision-Language Models
Apr 04, 2026Large Vision-Language Models (LVLMs) suffer from prohibitive inference costs due to the massive number of visual tokens processed by the language decoder. Existing pruning methods often lead to significant performance degradation because the irreversible removal of visual tokens causes a distribution shift in the hidden states that deviates from the pre-trained full-token regime. To address this, we propose Representation Consistency Pruner, which we refer to as RCP, as a novel framework that integrates cumulative visual token pruning with a delayed repair mechanism. Specifically, we introduce a cross-attention pruner that leverages the intrinsic attention of the LLM as a baseline to predict cumulative masks, ensuring consistent and monotonic token reduction across layers. To compensate for the resulting information loss, we design a delayed repair adapter denoted as DRA, which caches the essence of pruned tokens and applies FiLM-based modulation specifically to the answer generation tokens. We employ a repair loss to match the first and second-order statistics of the pruned representations with a full-token teacher. RCP is highly efficient because it trains only lightweight plug-in modules while allowing for physical token discarding at inference. Extensive experiments on LVLM benchmarks demonstrate that RCP removes up to 88.9\% of visual tokens and reduces FLOPs by up to 85.7\% with only a marginal average accuracy drop, and outperforms prior methods that avoid fine-tuning the original model on several widely used benchmarks.
Language-Guided Token Compression with Reinforcement Learning in Large Vision-Language Models
Mar 11, 2026Large Vision-Language Models (LVLMs) incur substantial inference costs due to the processing of a vast number of visual tokens. Existing methods typically struggle to model progressive visual token reduction as a multi-step decision process with sequential dependencies and often rely on hand-engineered scoring rules that lack adaptive optimization for complex reasoning trajectories. To overcome these limitations, we propose TPRL, a reinforcement learning framework that learns adaptive pruning trajectories through language-guided sequential optimization tied directly to end-task performance. We formulate visual token pruning as a sequential decision process with explicit state transitions and employ a self-supervised autoencoder to compress visual tokens into a compact state representation for efficient policy learning. The pruning policy is initialized through learning from demonstrations and subsequently fine-tuned using Proximal Policy Optimization (PPO) to jointly optimize task accuracy and computational efficiency. Our experimental results demonstrate that TPRL removes up to 66.7\% of visual tokens and achieves up to a 54.2\% reduction in FLOPs during inference while maintaining a near-lossless average accuracy drop of only 0.7\%. Code is released at \href{https://github.com/MagicVicCoder/TPRL}{\textcolor{mypink}{https://github.com/MagicVicCoder/TPRL}}.
GHS-TDA: A Synergistic Reasoning Framework Integrating Global Hypothesis Space with Topological Data Analysis
Feb 10, 2026Chain-of-Thought (CoT) has been shown to significantly improve the reasoning accuracy of large language models (LLMs) on complex tasks. However, due to the autoregressive, step-by-step generation paradigm, existing CoT methods suffer from two fundamental limitations. First, the reasoning process is highly sensitive to early decisions: once an initial error is introduced, it tends to propagate and amplify through subsequent steps, while the lack of a global coordination and revision mechanism makes such errors difficult to correct, ultimately leading to distorted reasoning chains. Second, current CoT approaches lack structured analysis techniques for filtering redundant reasoning and extracting key reasoning features, resulting in unstable reasoning processes and limited interpretability. To address these issues, we propose GHS-TDA. GHS-TDA first constructs a semantically enriched global hypothesis graph to aggregate, align, and coordinate multiple candidate reasoning paths, thereby providing alternative global correction routes when local reasoning fails. It then applies topological data analysis based on persistent homology to capture stable multi-scale structures, remove redundancy and inconsistencies, and extract a more reliable reasoning skeleton. By jointly leveraging reasoning diversity and topological stability, GHS-TDA achieves self-adaptive convergence, produces high-confidence and interpretable reasoning paths, and consistently outperforms strong baselines in terms of both accuracy and robustness across multiple reasoning benchmarks.
A Consistency-Improved LiDAR-Inertial Bundle Adjustment
Feb 06, 2026Simultaneous Localization and Mapping (SLAM) using 3D LiDAR has emerged as a cornerstone for autonomous navigation in robotics. While feature-based SLAM systems have achieved impressive results by leveraging edge and planar structures, they often suffer from the inconsistent estimator associated with feature parameterization and estimated covariance. In this work, we present a consistency-improved LiDAR-inertial bundle adjustment (BA) with tailored parameterization and estimator. First, we propose a stereographic-projection representation parameterizing the planar and edge features, and conduct a comprehensive observability analysis to support its integrability with consistent estimator. Second, we implement a LiDAR-inertial BA with Maximum a Posteriori (MAP) formulation and First-Estimate Jacobians (FEJ) to preserve the accurate estimated covariance and observability properties of the system. Last, we apply our proposed BA method to a LiDAR-inertial odometry.
LLaVA-FA: Learning Fourier Approximation for Compressing Large Multimodal Models
Jan 28, 2026Large multimodal models (LMMs) have achieved impressive performance on various vision-language tasks, but their substantial computational and memory costs hinder their practical deployment. Existing compression methods often decouple low-rank decomposition and quantization, leading to compounded reconstruction errors, especially in multimodal architectures with cross-modal redundancy. To address this issue, we propose LLaVA-FA, a novel efficient LMM that performs joint low-rank plus quantization approximation in the frequency domain. By leveraging the de-correlation and conjugate symmetry properties of Fourier transform, LLaVA-FA achieves more compact and accurate weight representations. Furthermore, we introduce PolarQuant, a polar-coordinate quantization method tailored for complex matrices, and an optional diagonal calibration (ODC) scheme that eliminates the need for large-scale calibration data. Extensive experimental results demonstrate that our proposed LLaVA-FA outperforms existing efficient multimodal models across multiple benchmarks while maintaining minimal activated parameters and low computational costs, validating its effectiveness as a powerful solution for compressing LMMs.
GRASP: Guided Region-Aware Sparse Prompting for Adapting MLLMs to Remote Sensing
Jan 23, 2026In recent years, Multimodal Large Language Models (MLLMs) have made significant progress in visual question answering tasks. However, directly applying existing fine-tuning methods to remote sensing (RS) images often leads to issues such as overfitting on background noise or neglecting target details. This is primarily due to the large-scale variations, sparse target distributions, and complex regional semantic features inherent in RS images. These challenges limit the effectiveness of MLLMs in RS tasks. To address these challenges, we propose a parameter-efficient fine-tuning (PEFT) strategy called Guided Region-Aware Sparse Prompting (GRASP). GRASP introduces spatially structured soft prompts associated with spatial blocks extracted from a frozen visual token grid. Through a question-guided sparse fusion mechanism, GRASP dynamically aggregates task-specific context into a compact global prompt, enabling the model to focus on relevant regions while filtering out background noise. Extensive experiments on multiple RSVQA benchmarks show that GRASP achieves competitive performance compared to existing fine-tuning and prompt-based methods while maintaining high parameter efficiency.
Efficient Medical Image Restoration via Reliability Guided Learning in Frequency Domain
Apr 15, 2025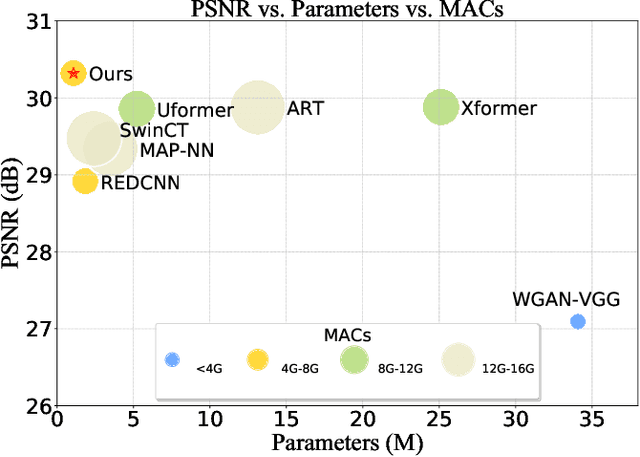
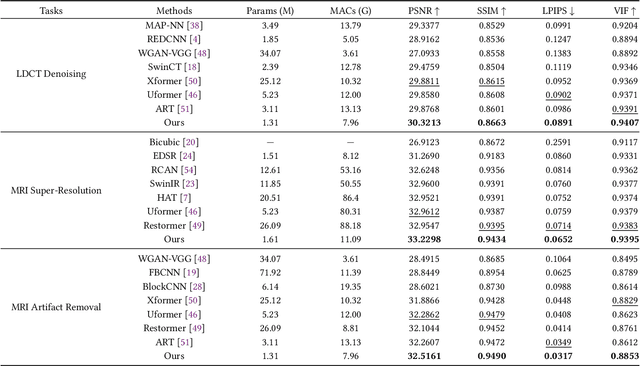
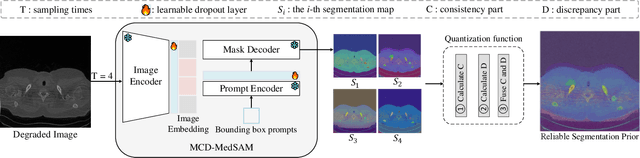
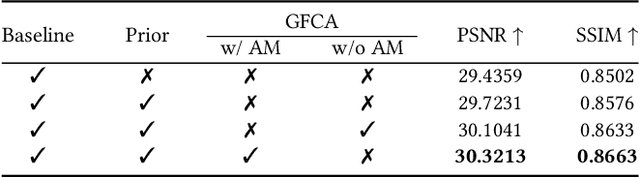
Medical image restoration tasks aim to recover high-quality images from degraded observations, exhibiting emergent desires in many clinical scenarios, such as low-dose CT image denoising, MRI super-resolution, and MRI artifact removal. Despite the success achieved by existing deep learning-based restoration methods with sophisticated modules, they struggle with rendering computationally-efficient reconstruction results. Moreover, they usually ignore the reliability of the restoration results, which is much more urgent in medical systems. To alleviate these issues, we present LRformer, a Lightweight Transformer-based method via Reliability-guided learning in the frequency domain. Specifically, inspired by the uncertainty quantification in Bayesian neural networks (BNNs), we develop a Reliable Lesion-Semantic Prior Producer (RLPP). RLPP leverages Monte Carlo (MC) estimators with stochastic sampling operations to generate sufficiently-reliable priors by performing multiple inferences on the foundational medical image segmentation model, MedSAM. Additionally, instead of directly incorporating the priors in the spatial domain, we decompose the cross-attention (CA) mechanism into real symmetric and imaginary anti-symmetric parts via fast Fourier transform (FFT), resulting in the design of the Guided Frequency Cross-Attention (GFCA) solver. By leveraging the conjugated symmetric property of FFT, GFCA reduces the computational complexity of naive CA by nearly half. Extensive experimental results in various tasks demonstrate the superiority of the proposed LRformer in both effectiveness and efficiency.