 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTyger: Task-Type-Generic Active Learning for Molecular Property Prediction
May 23, 2022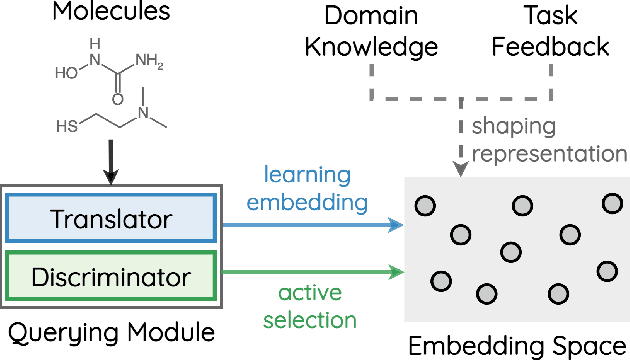
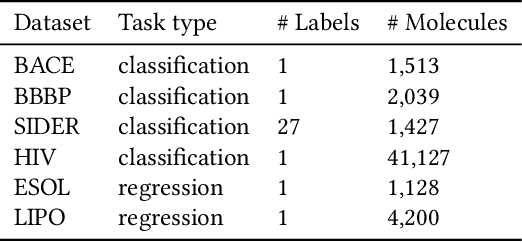
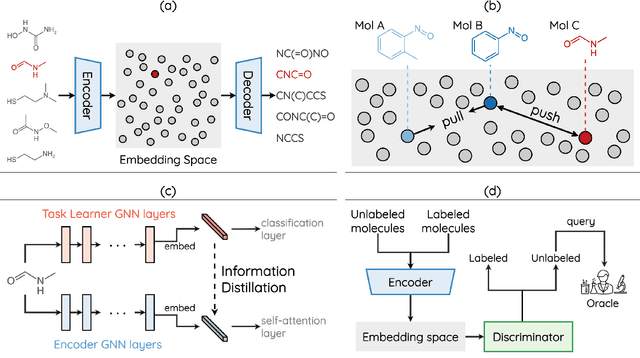
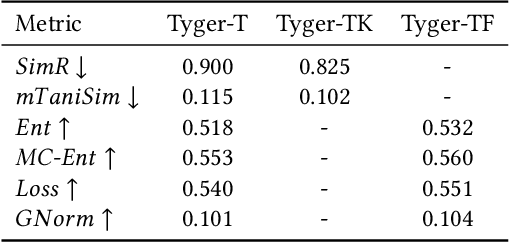
How to accurately predict the properties of molecules is an essential problem in AI-driven drug discovery, which generally requires a large amount of annotation for training deep learning models. Annotating molecules, however, is quite costly because it requires lab experiments conducted by experts. To reduce annotation cost, deep Active Learning (AL) methods are developed to select only the most representative and informative data for annotating. However, existing best deep AL methods are mostly developed for a single type of learning task (e.g., single-label classification), and hence may not perform well in molecular property prediction that involves various task types. In this paper, we propose a Task-type-generic active learning framework (termed Tyger) that is able to handle different types of learning tasks in a unified manner. The key is to learn a chemically-meaningful embedding space and perform active selection fully based on the embeddings, instead of relying on task-type-specific heuristics (e.g., class-wise prediction probability) as done in existing works. Specifically, for learning the embedding space, we instantiate a querying module that learns to translate molecule graphs into corresponding SMILES strings. Furthermore, to ensure that samples selected from the space are both representative and informative, we propose to shape the embedding space by two learning objectives, one based on domain knowledge and the other leveraging feedback from the task learner (i.e., model that performs the learning task at hand). We conduct extensive experiments on benchmark datasets of different task types. Experimental results show that Tyger consistently achieves high AL performance on molecular property prediction, outperforming baselines by a large margin. We also perform ablative experiments to verify the effectiveness of each component in Tyger.
Understanding The Robustness in Vision Transformers
Apr 27, 2022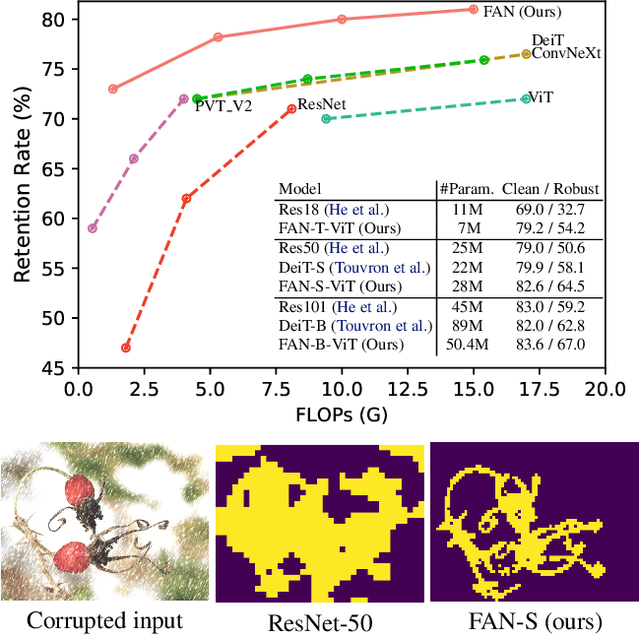

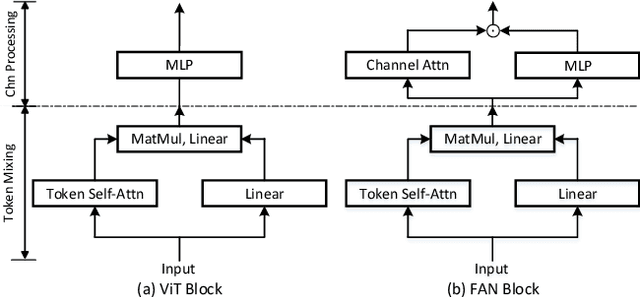
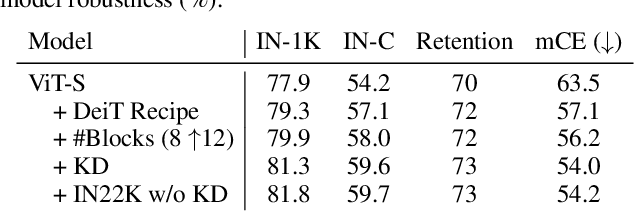
Recent studies show that Vision Transformers(ViTs) exhibit strong robustness against various corruptions. Although this property is partly attributed to the self-attention mechanism, there is still a lack of systematic understanding. In this paper, we examine the role of self-attention in learning robust representations. Our study is motivated by the intriguing properties of the emerging visual grouping in Vision Transformers, which indicates that self-attention may promote robustness through improved mid-level representations. We further propose a family of fully attentional networks (FANs) that strengthen this capability by incorporating an attentional channel processing design. We validate the design comprehensively on various hierarchical backbones. Our model achieves a state of-the-art 87.1% accuracy and 35.8% mCE on ImageNet-1k and ImageNet-C with 76.8M parameters. We also demonstrate state-of-the-art accuracy and robustness in two downstream tasks: semantic segmentation and object detection. Code will be available at https://github.com/NVlabs/FAN.
Generalizing Few-Shot NAS with Gradient Matching
Apr 05, 2022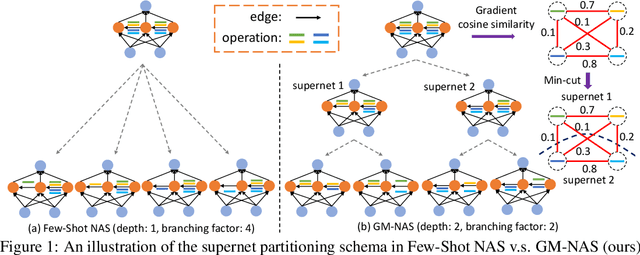
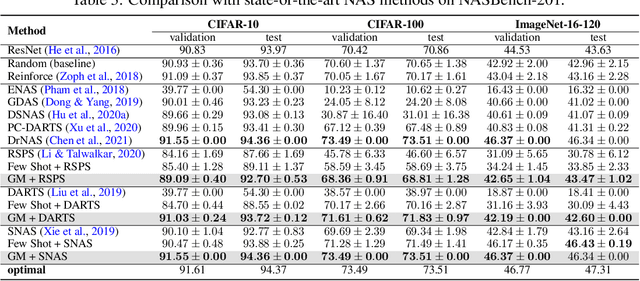
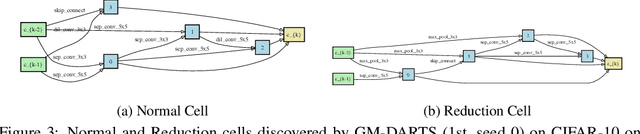
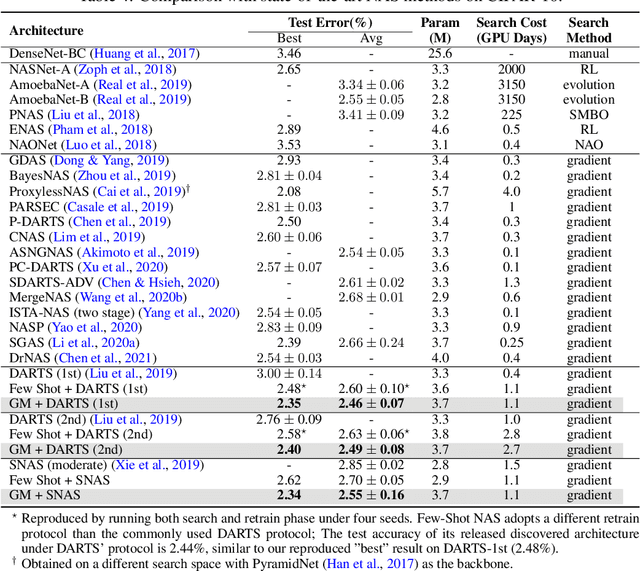
Efficient performance estimation of architectures drawn from large search spaces is essential to Neural Architecture Search. One-Shot methods tackle this challenge by training one supernet to approximate the performance of every architecture in the search space via weight-sharing, thereby drastically reducing the search cost. However, due to coupled optimization between child architectures caused by weight-sharing, One-Shot supernet's performance estimation could be inaccurate, leading to degraded search outcomes. To address this issue, Few-Shot NAS reduces the level of weight-sharing by splitting the One-Shot supernet into multiple separated sub-supernets via edge-wise (layer-wise) exhaustive partitioning. Since each partition of the supernet is not equally important, it necessitates the design of a more effective splitting criterion. In this work, we propose a gradient matching score (GM) that leverages gradient information at the shared weight for making informed splitting decisions. Intuitively, gradients from different child models can be used to identify whether they agree on how to update the shared modules, and subsequently to decide if they should share the same weight. Compared with exhaustive partitioning, the proposed criterion significantly reduces the branching factor per edge. This allows us to split more edges (layers) for a given budget, resulting in substantially improved performance as NAS search spaces usually include dozens of edges (layers). Extensive empirical evaluations of the proposed method on a wide range of search spaces (NASBench-201, DARTS, MobileNet Space), datasets (cifar10, cifar100, ImageNet) and search algorithms (DARTS, SNAS, RSPS, ProxylessNAS, OFA) demonstrate that it significantly outperforms its Few-Shot counterparts while surpassing previous comparable methods in terms of the accuracy of derived architectures.
PoseTriplet: Co-evolving 3D Human Pose Estimation, Imitation, and Hallucination under Self-supervision
Mar 29, 2022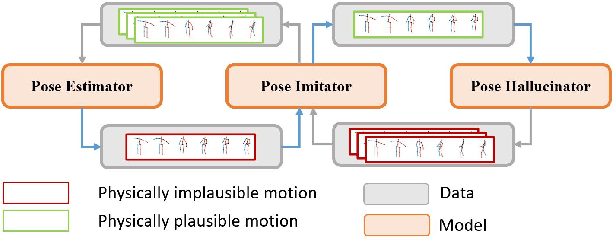
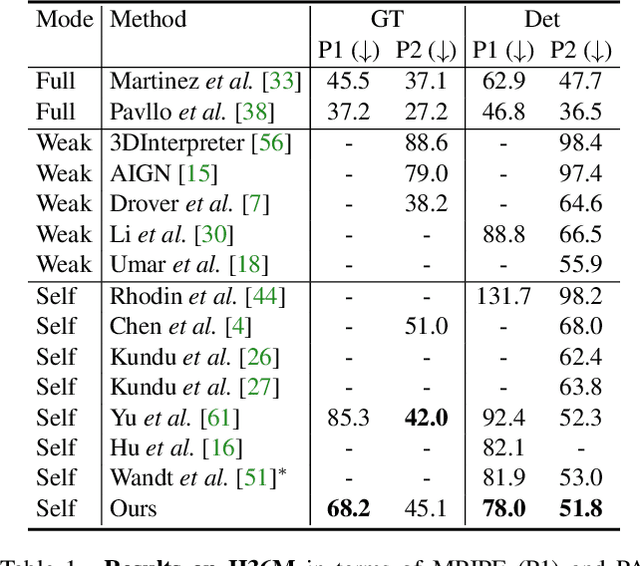
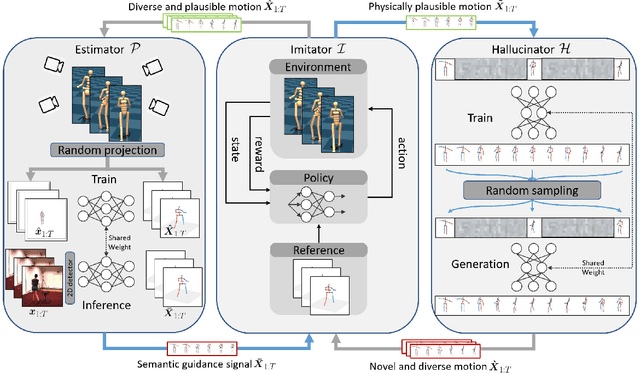
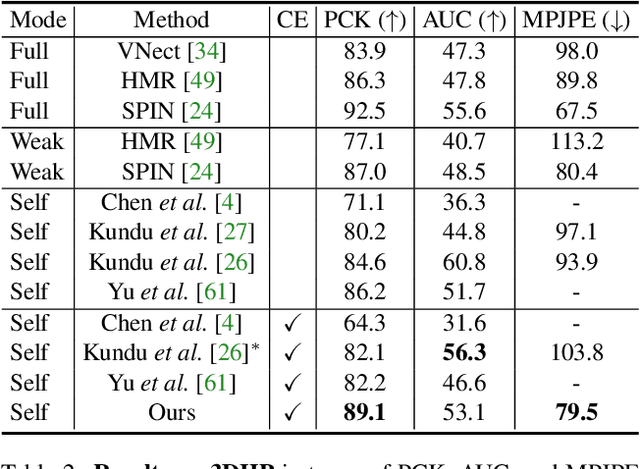
Existing self-supervised 3D human pose estimation schemes have largely relied on weak supervisions like consistency loss to guide the learning, which, inevitably, leads to inferior results in real-world scenarios with unseen poses. In this paper, we propose a novel self-supervised approach that allows us to explicitly generate 2D-3D pose pairs for augmenting supervision, through a self-enhancing dual-loop learning framework. This is made possible via introducing a reinforcement-learning-based imitator, which is learned jointly with a pose estimator alongside a pose hallucinator; the three components form two loops during the training process, complementing and strengthening one another. Specifically, the pose estimator transforms an input 2D pose sequence to a low-fidelity 3D output, which is then enhanced by the imitator that enforces physical constraints. The refined 3D poses are subsequently fed to the hallucinator for producing even more diverse data, which are, in turn, strengthened by the imitator and further utilized to train the pose estimator. Such a co-evolution scheme, in practice, enables training a pose estimator on self-generated motion data without relying on any given 3D data. Extensive experiments across various benchmarks demonstrate that our approach yields encouraging results significantly outperforming the state of the art and, in some cases, even on par with results of fully-supervised methods. Notably, it achieves 89.1% 3D PCK on MPI-INF-3DHP under self-supervised cross-dataset evaluation setup, improving upon the previous best self-supervised methods by 8.6%. Code can be found at: https://github.com/Garfield-kh/PoseTriplet
SODAR: Segmenting Objects by DynamicallyAggregating Neighboring Mask Representations
Feb 15, 2022Recent state-of-the-art one-stage instance segmentation model SOLO divides the input image into a grid and directly predicts per grid cell object masks with fully-convolutional networks, yielding comparably good performance as traditional two-stage Mask R-CNN yet enjoying much simpler architecture and higher efficiency. We observe SOLO generates similar masks for an object at nearby grid cells, and these neighboring predictions can complement each other as some may better segment certain object part, most of which are however directly discarded by non-maximum-suppression. Motivated by the observed gap, we develop a novel learning-based aggregation method that improves upon SOLO by leveraging the rich neighboring information while maintaining the architectural efficiency. The resulting model is named SODAR. Unlike the original per grid cell object masks, SODAR is implicitly supervised to learn mask representations that encode geometric structure of nearby objects and complement adjacent representations with context. The aggregation method further includes two novel designs: 1) a mask interpolation mechanism that enables the model to generate much fewer mask representations by sharing neighboring representations among nearby grid cells, and thus saves computation and memory; 2) a deformable neighbour sampling mechanism that allows the model to adaptively adjust neighbor sampling locations thus gathering mask representations with more relevant context and achieving higher performance. SODAR significantly improves the instance segmentation performance, e.g., it outperforms a SOLO model with ResNet-101 backbone by 2.2 AP on COCO \texttt{test} set, with only about 3\% additional computation. We further show consistent performance gain with the SOLOv2 model.
The Geometry of Robust Value Functions
Jan 30, 2022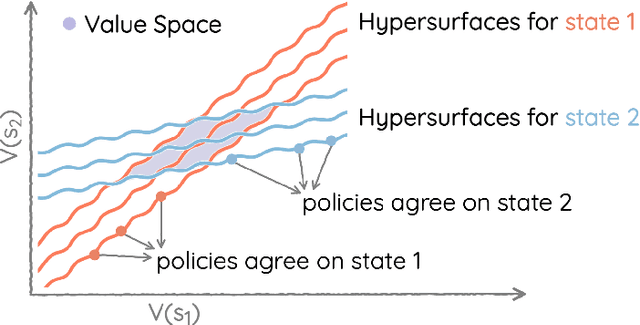
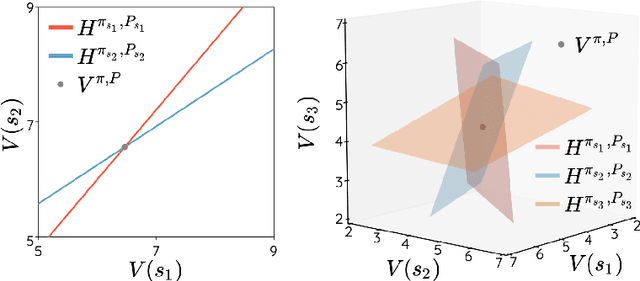
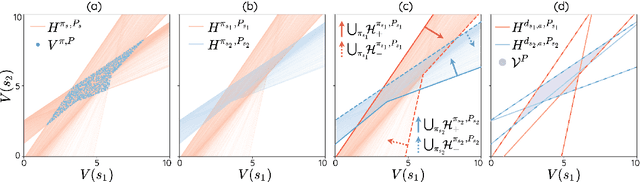
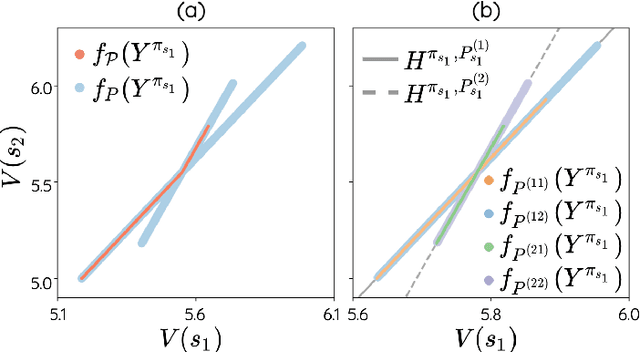
The space of value functions is a fundamental concept in reinforcement learning. Characterizing its geometric properties may provide insights for optimization and representation. Existing works mainly focus on the value space for Markov Decision Processes (MDPs). In this paper, we study the geometry of the robust value space for the more general Robust MDPs (RMDPs) setting, where transition uncertainties are considered. Specifically, since we find it hard to directly adapt prior approaches to RMDPs, we start with revisiting the non-robust case, and introduce a new perspective that enables us to characterize both the non-robust and robust value space in a similar fashion. The key of this perspective is to decompose the value space, in a state-wise manner, into unions of hypersurfaces. Through our analysis, we show that the robust value space is determined by a set of conic hypersurfaces, each of which contains the robust values of all policies that agree on one state. Furthermore, we find that taking only extreme points in the uncertainty set is sufficient to determine the robust value space. Finally, we discuss some other aspects about the robust value space, including its non-convexity and policy agreement on multiple states.
Towards Adversarially Robust Deep Image Denoising
Jan 13, 2022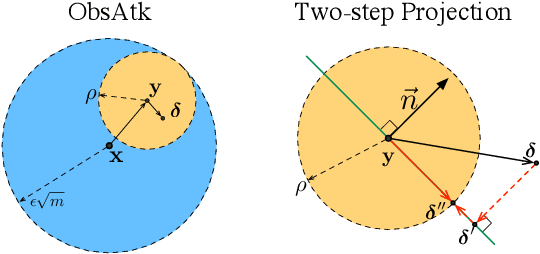
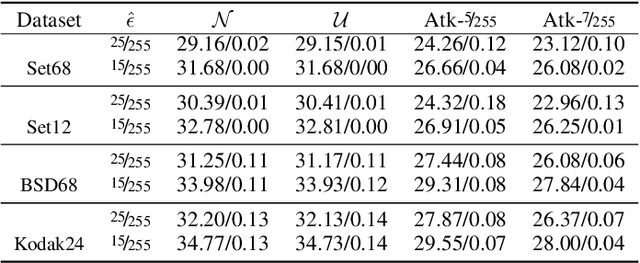

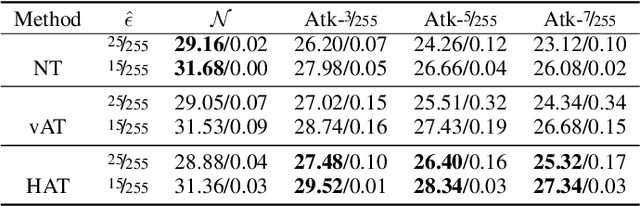
This work systematically investigates the adversarial robustness of deep image denoisers (DIDs), i.e, how well DIDs can recover the ground truth from noisy observations degraded by adversarial perturbations. Firstly, to evaluate DIDs' robustness, we propose a novel adversarial attack, namely Observation-based Zero-mean Attack ({\sc ObsAtk}), to craft adversarial zero-mean perturbations on given noisy images. We find that existing DIDs are vulnerable to the adversarial noise generated by {\sc ObsAtk}. Secondly, to robustify DIDs, we propose an adversarial training strategy, hybrid adversarial training ({\sc HAT}), that jointly trains DIDs with adversarial and non-adversarial noisy data to ensure that the reconstruction quality is high and the denoisers around non-adversarial data are locally smooth. The resultant DIDs can effectively remove various types of synthetic and adversarial noise. We also uncover that the robustness of DIDs benefits their generalization capability on unseen real-world noise. Indeed, {\sc HAT}-trained DIDs can recover high-quality clean images from real-world noise even without training on real noisy data. Extensive experiments on benchmark datasets, including Set68, PolyU, and SIDD, corroborate the effectiveness of {\sc ObsAtk} and {\sc HAT}.
Mimicking the Oracle: An Initial Phase Decorrelation Approach for Class Incremental Learning
Jan 03, 2022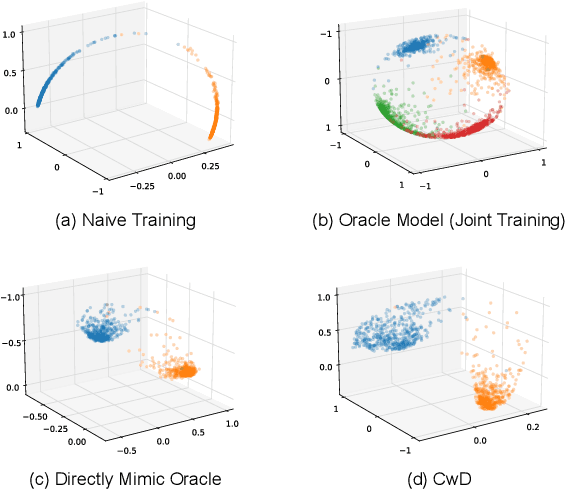
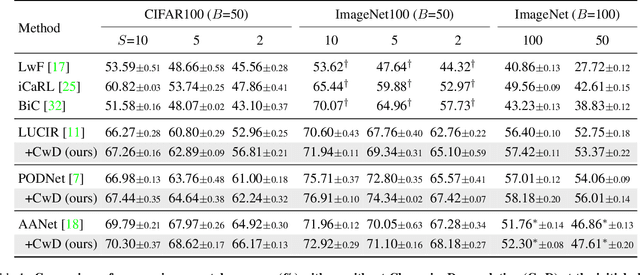
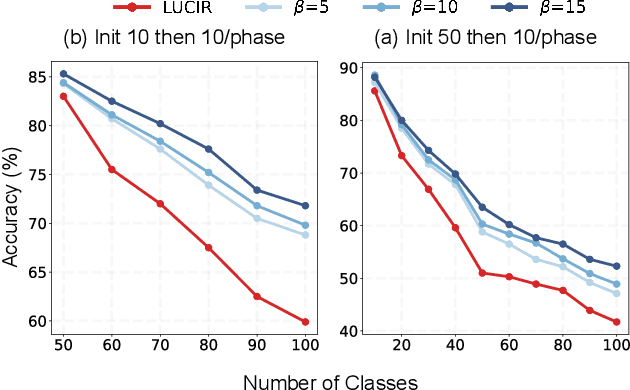
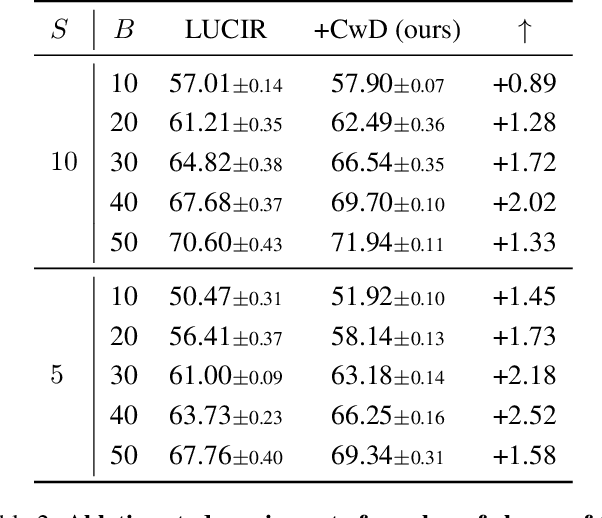
Class Incremental Learning (CIL) aims at learning a multi-class classifier in a phase-by-phase manner, in which only data of a subset of the classes are provided at each phase. Previous works mainly focus on mitigating forgetting in phases after the initial one. However, we find that improving CIL at its initial phase is also a promising direction. Specifically, we experimentally show that directly encouraging CIL Learner at the initial phase to output similar representations as the model jointly trained on all classes can greatly boost the CIL performance. Motivated by this, we study the difference between a na\"ively-trained initial-phase model and the oracle model. Specifically, since one major difference between these two models is the number of training classes, we investigate how such difference affects the model representations. We find that, with fewer training classes, the data representations of each class lie in a long and narrow region; with more training classes, the representations of each class scatter more uniformly. Inspired by this observation, we propose Class-wise Decorrelation (CwD) that effectively regularizes representations of each class to scatter more uniformly, thus mimicking the model jointly trained with all classes (i.e., the oracle model). Our CwD is simple to implement and easy to plug into existing methods. Extensive experiments on various benchmark datasets show that CwD consistently and significantly improves the performance of existing state-of-the-art methods by around 1\% to 3\%. Code will be released.
UMAD: Universal Model Adaptation under Domain and Category Shift
Dec 16, 2021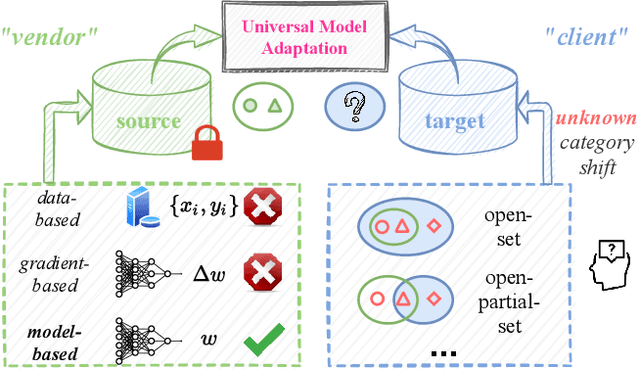
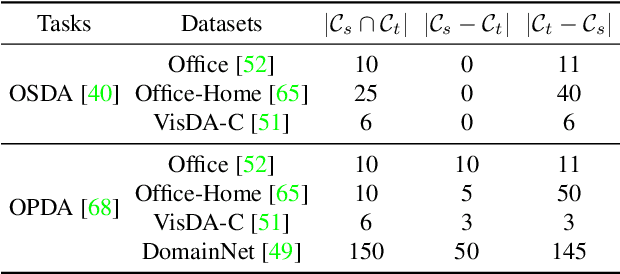
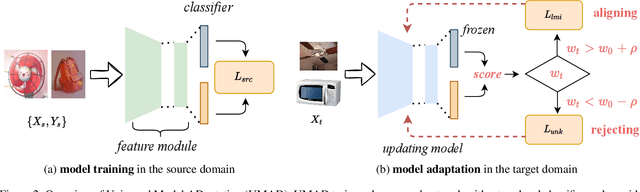
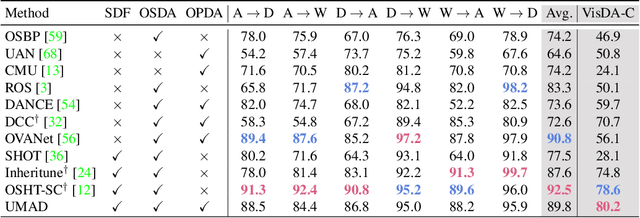
Learning to reject unknown samples (not present in the source classes) in the target domain is fairly important for unsupervised domain adaptation (UDA). There exist two typical UDA scenarios, i.e., open-set, and open-partial-set, and the latter assumes that not all source classes appear in the target domain. However, most prior methods are designed for one UDA scenario and always perform badly on the other UDA scenario. Moreover, they also require the labeled source data during adaptation, limiting their usability in data privacy-sensitive applications. To address these issues, this paper proposes a Universal Model ADaptation (UMAD) framework which handles both UDA scenarios without access to the source data nor prior knowledge about the category shift between domains. Specifically, we aim to learn a source model with an elegantly designed two-head classifier and provide it to the target domain. During adaptation, we develop an informative consistency score to help distinguish unknown samples from known samples. To achieve bilateral adaptation in the target domain, we further maximize localized mutual information to align known samples with the source classifier and employ an entropic loss to push unknown samples far away from the source classification boundary, respectively. Experiments on open-set and open-partial-set UDA scenarios demonstrate that UMAD, as a unified approach without access to source data, exhibits comparable, if not superior, performance to state-of-the-art data-dependent methods.
Geometry-Guided Progressive NeRF for Generalizable and Efficient Neural Human Rendering
Dec 08, 2021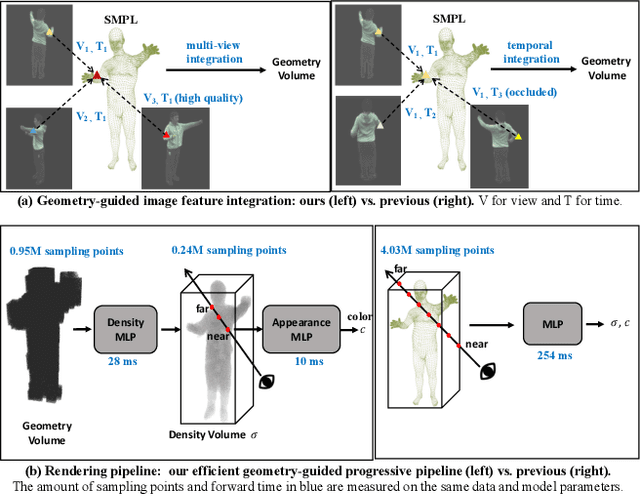
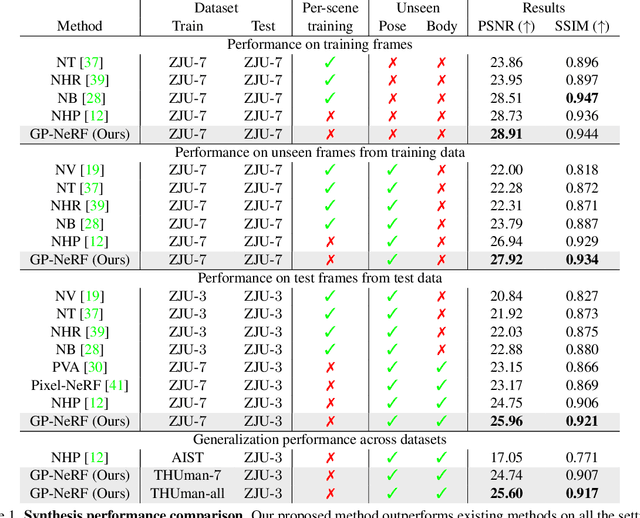
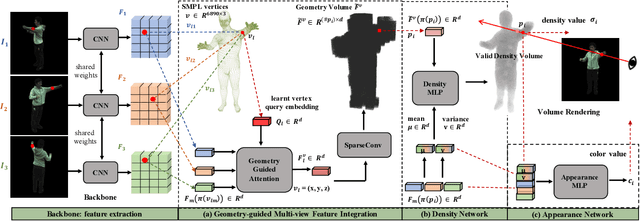
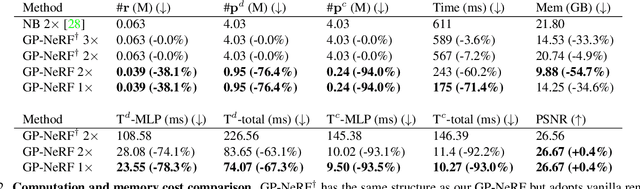
In this work we develop a generalizable and efficient Neural Radiance Field (NeRF) pipeline for high-fidelity free-viewpoint human body synthesis under settings with sparse camera views. Though existing NeRF-based methods can synthesize rather realistic details for human body, they tend to produce poor results when the input has self-occlusion, especially for unseen humans under sparse views. Moreover, these methods often require a large number of sampling points for rendering, which leads to low efficiency and limits their real-world applicability. To address these challenges, we propose a Geometry-guided Progressive NeRF~(GP-NeRF). In particular, to better tackle self-occlusion, we devise a geometry-guided multi-view feature integration approach that utilizes the estimated geometry prior to integrate the incomplete information from input views and construct a complete geometry volume for the target human body. Meanwhile, for achieving higher rendering efficiency, we introduce a geometry-guided progressive rendering pipeline, which leverages the geometric feature volume and the predicted density values to progressively reduce the number of sampling points and speed up the rendering process. Experiments on the ZJU-MoCap and THUman datasets show that our method outperforms the state-of-the-arts significantly across multiple generalization settings, while the time cost is reduced >70% via applying our efficient progressive rendering pipeline.