 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStatistical Scouting Finds Debate-Safe but Not Debate-Useful Cases: A Matched-Ceiling Study of Open-Weight LLM Reasoning Protocols
May 10, 2026When should a language model answer directly, sample and vote, or engage in multi-agent debate? Recent work shows voting often explains much of the gain attributed to debate, while selective-debate systems activate deliberation only on uncertain examples. We ask: under a matched ceiling on generated tokens (960 per example), how much per-example routing headroom exists, and how much is recoverable from cheap pre-deliberation signals? We evaluate greedy decoding, three-sample voting, and a two-agent critique-revise debate on MuSiQue and GSM8K using Llama 3.1 8B Instruct and Ministral 3 8B Instruct. On MuSiQue, an oracle selecting the correct protocol per example gains +14.0 and +13.7 pp over the best fixed one. The best fixed protocol is model- and dataset-dependent: each (model, dataset) cell has a different winner. This headroom is hard to recover from cheap ex-ante signals. A vote-entropy threshold is the only controller that directionally beats the best fixed protocol on both models (+1.3 and +1.7 pp), though individual paired-bootstrap CIs include zero. A joint analysis (meta-analysis +1.6 pp, p=0.125; Bayesian P(both>0)=0.59) is directionally consistent but not significant. Learned controllers (LR, GBT) do not outperform the threshold. The key finding is structural: vote entropy predicts where debate is safe, not where debate is needed. High entropy sharply reduces debate backfire, but 66% of debate-helpful examples (31/47) occur when voting is unanimous but wrong. A single-prompt self-critique probe on Llama flips the answer in 127/127 unanimous cases, yielding zero mutual information with the debate-helpful label; we cannot rule out a prompt-compliance artifact, but either interpretation disqualifies the probe as a router. Recovering the remaining headroom requires behavioral probes that avoid format-compliance confounds at the 8B scale.
STEM Agent: A Self-Adapting, Tool-Enabled, Extensible Architecture for Multi-Protocol AI Agent Systems
Mar 22, 2026Current AI agent frameworks commit early to a single interaction protocol, a fixed tool integration strategy, and static user models, limiting their deployment across diverse interaction paradigms. To address these constraints, we introduce STEM Agent (Self-adapting, Tool-enabled, Extensible, Multi-agent), a modular architecture inspired by biological pluripotency in which an undifferentiated agent core differentiates into specialized protocol handlers, tool bindings, and memory subsystems that compose into a fully functioning AI system. The framework unifies five interoperability protocols (A2A, AG-UI, A2UI, UCP, and AP2) behind a single gateway, introduces a Caller Profiler that continuously learns user preferences across more than twenty behavioral dimensions, externalizes all domain capabilities through the Model Context Protocol (MCP), and implements a biologically inspired skills acquisition system in which recurring interaction patterns crystallize into reusable agent skills through a maturation lifecycle analogous to cell differentiation. Complementing these capabilities, the memory system incorporates consolidation mechanisms, including episodic pruning, semantic deduplication, and pattern extraction, designed for sub-linear growth under sustained interaction. A comprehensive 413-test suite validates protocol handler behavior and component integration across all five architectural layers, completing in under three seconds.
Gated Sparse Attention: Combining Computational Efficiency with Training Stability for Long-Context Language Models
Jan 12, 2026The computational burden of attention in long-context language models has motivated two largely independent lines of work: sparse attention mechanisms that reduce complexity by attending to selected tokens, and gated attention variants that improve training sta-bility while mitigating the attention sink phenomenon. We observe that these approaches address complementary weaknesses and propose Gated Sparse Attention (GSA), an architecture that realizes the benefits of both. GSA incorporates a gated lightning indexer with sigmoid activations that produce bounded, interpretable selection scores, an adaptive sparsity controller that modulates the number of attended tokens based on local uncertainty, and dual gating at the value and output stages. We establish theoretical foundations for the approach, including complexity analysis, expressiveness results, and convergence guarantees. In experiments with 1.7B parameter models trained on 400B tokens, GSA matches the efficiency of sparse-only baselines (12-16x speedup at 128K context) while achieving the quality gains associated with gated attention: perplexity improves from 6.03 to 5.70, RULER scores at 128K context nearly double, and attention to the first token, a proxy for attention sinks, drops from 47% to under 4%. Training stability improves markedly, with loss spikes reduced by 98%.
How Well Self-Supervised Pre-Training Performs with Streaming Data?
Apr 25, 2021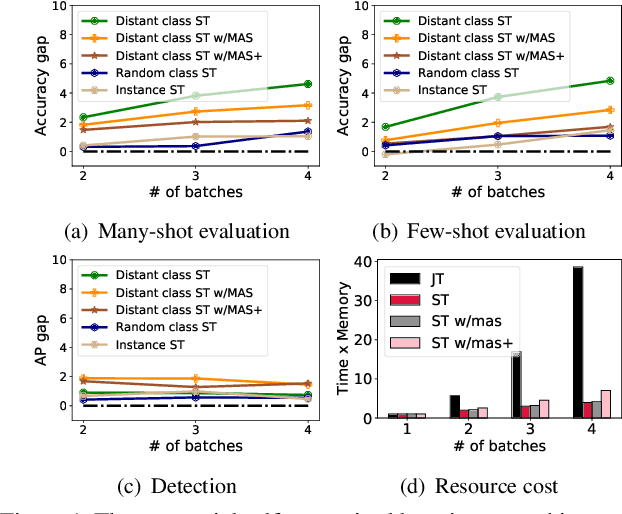
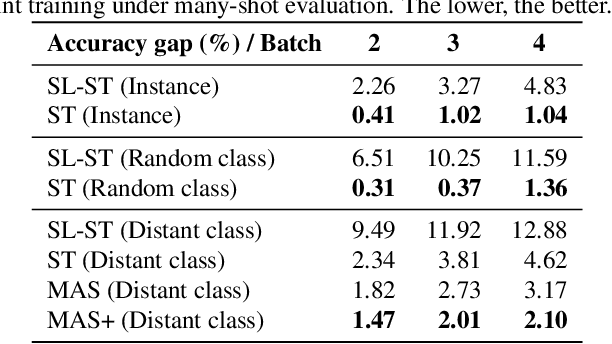
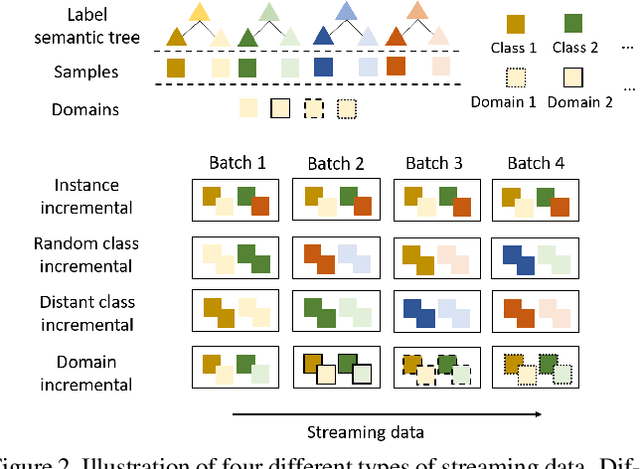
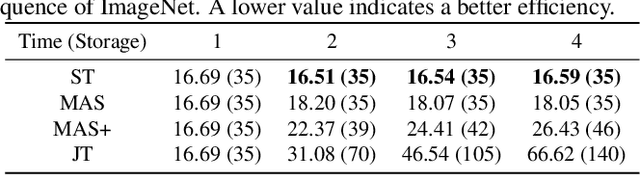
The common self-supervised pre-training practice requires collecting massive unlabeled data together and then trains a representation model, dubbed \textbf{joint training}. However, in real-world scenarios where data are collected in a streaming fashion, the joint training scheme is usually storage-heavy and time-consuming. A more efficient alternative is to train a model continually with streaming data, dubbed \textbf{sequential training}. Nevertheless, it is unclear how well sequential self-supervised pre-training performs with streaming data. In this paper, we conduct thorough experiments to investigate self-supervised pre-training with streaming data. Specifically, we evaluate the transfer performance of sequential self-supervised pre-training with four different data sequences on three different downstream tasks and make comparisons with joint self-supervised pre-training. Surprisingly, we find sequential self-supervised learning exhibits almost the same performance as the joint training when the distribution shifts within streaming data are mild. Even for data sequences with large distribution shifts, sequential self-supervised training with simple techniques, e.g., parameter regularization or data replay, still performs comparably to joint training. Based on our findings, we recommend using sequential self-supervised training as a \textbf{more efficient yet performance-competitive} representation learning practice for real-world applications.