 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepViT: Towards Deeper Vision Transformer
Paper and Code
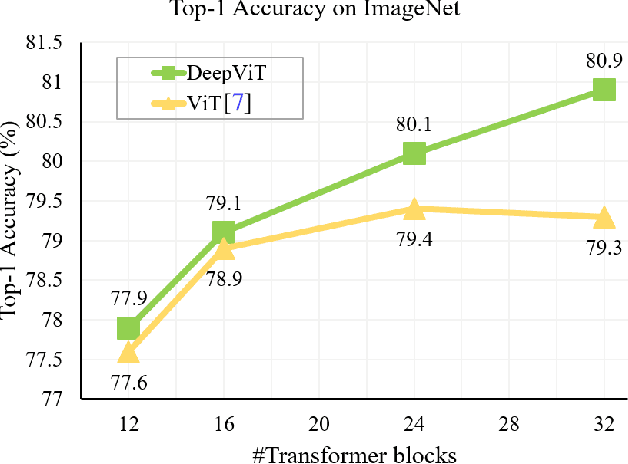
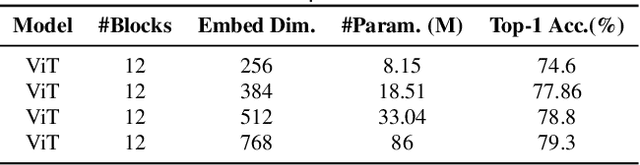
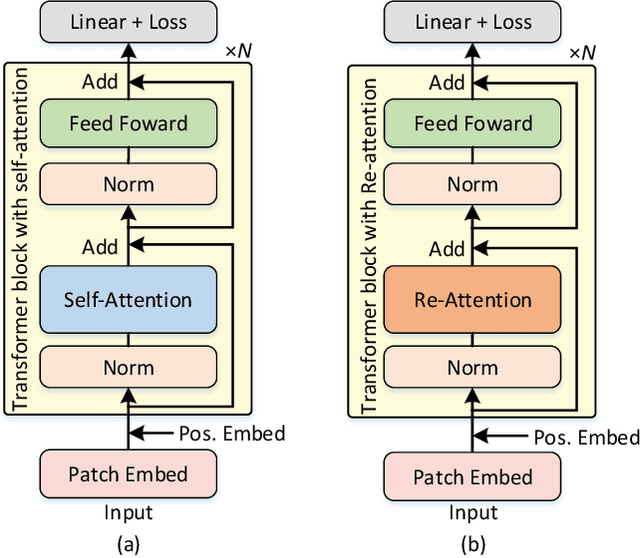

Vision transformers (ViTs) have been successfully applied in image classification tasks recently. In this paper, we show that, unlike convolution neural networks (CNNs)that can be improved by stacking more convolutional layers, the performance of ViTs saturate fast when scaled to be deeper. More specifically, we empirically observe that such scaling difficulty is caused by the attention collapse issue: as the transformer goes deeper, the attention maps gradually become similar and even much the same after certain layers. In other words, the feature maps tend to be identical in the top layers of deep ViT models. This fact demonstrates that in deeper layers of ViTs, the self-attention mechanism fails to learn effective concepts for representation learning and hinders the model from getting expected performance gain. Based on above observation, we propose a simple yet effective method, named Re-attention, to re-generate the attention maps to increase their diversity at different layers with negligible computation and memory cost. The pro-posed method makes it feasible to train deeper ViT models with consistent performance improvements via minor modification to existing ViT models. Notably, when training a deep ViT model with 32 transformer blocks, the Top-1 classification accuracy can be improved by 1.6% on ImageNet. Code is publicly available at https://github.com/zhoudaquan/dvit_repo.