 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlow Along the K-Amplitude for Generative Modeling
Apr 27, 2025In this work, we propose a novel generative learning paradigm, K-Flow, an algorithm that flows along the $K$-amplitude. Here, $k$ is a scaling parameter that organizes frequency bands (or projected coefficients), and amplitude describes the norm of such projected coefficients. By incorporating the $K$-amplitude decomposition, K-Flow enables flow matching across the scaling parameter as time. We discuss three venues and six properties of K-Flow, from theoretical foundations, energy and temporal dynamics, and practical applications, respectively. Specifically, from the practical usage perspective, K-Flow allows steerable generation by controlling the information at different scales. To demonstrate the effectiveness of K-Flow, we conduct experiments on unconditional image generation, class-conditional image generation, and molecule assembly generation. Additionally, we conduct three ablation studies to demonstrate how K-Flow steers scaling parameter to effectively control the resolution of image generation.
FlexDiT: Dynamic Token Density Control for Diffusion Transformer
Dec 08, 2024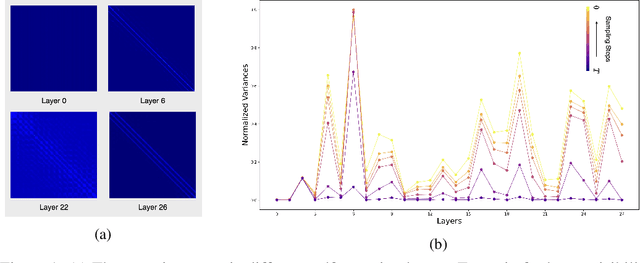
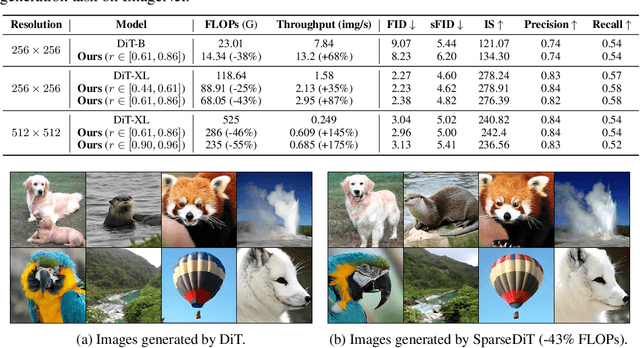
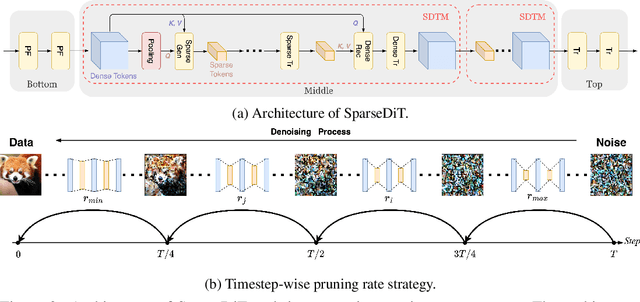

Diffusion Transformers (DiT) deliver impressive generative performance but face prohibitive computational demands due to both the quadratic complexity of token-based self-attention and the need for extensive sampling steps. While recent research has focused on accelerating sampling, the structural inefficiencies of DiT remain underexplored. We propose FlexDiT, a framework that dynamically adapts token density across both spatial and temporal dimensions to achieve computational efficiency without compromising generation quality. Spatially, FlexDiT employs a three-segment architecture that allocates token density based on feature requirements at each layer: Poolingformer in the bottom layers for efficient global feature extraction, Sparse-Dense Token Modules (SDTM) in the middle layers to balance global context with local detail, and dense tokens in the top layers to refine high-frequency details. Temporally, FlexDiT dynamically modulates token density across denoising stages, progressively increasing token count as finer details emerge in later timesteps. This synergy between FlexDiT's spatially adaptive architecture and its temporal pruning strategy enables a unified framework that balances efficiency and fidelity throughout the generation process. Our experiments demonstrate FlexDiT's effectiveness, achieving a 55% reduction in FLOPs and a 175% improvement in inference speed on DiT-XL with only a 0.09 increase in FID score on 512$\times$512 ImageNet images, a 56% reduction in FLOPs across video generation datasets including FaceForensics, SkyTimelapse, UCF101, and Taichi-HD, and a 69% improvement in inference speed on PixArt-$\alpha$ on text-to-image generation task with a 0.24 FID score decrease. FlexDiT provides a scalable solution for high-quality diffusion-based generation compatible with further sampling optimization techniques.
Revisiting Vision Transformer from the View of Path Ensemble
Aug 12, 2023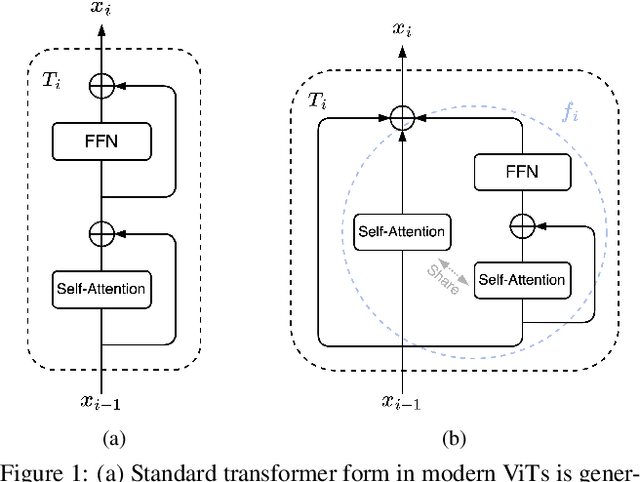
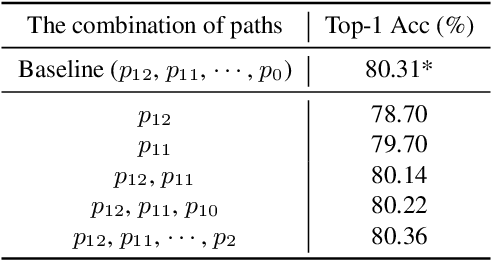
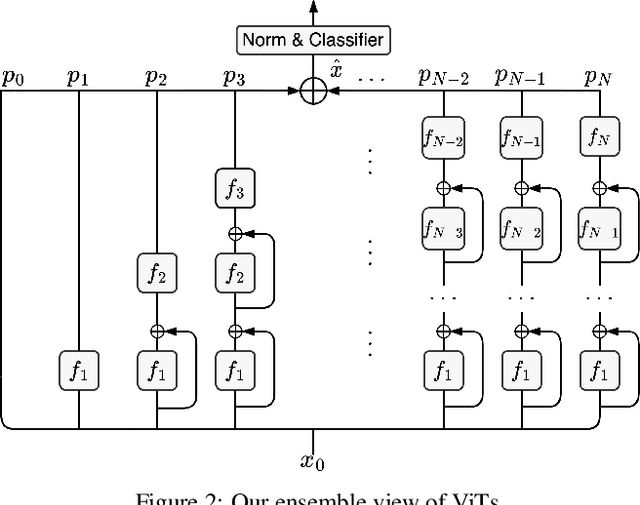
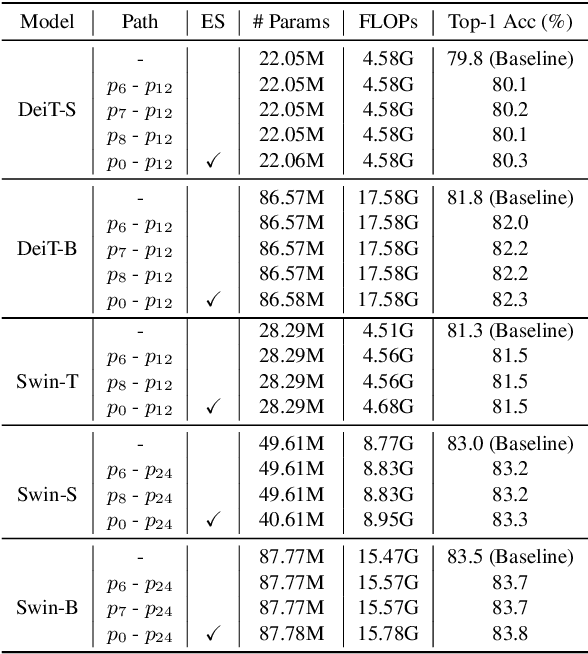
Vision Transformers (ViTs) are normally regarded as a stack of transformer layers. In this work, we propose a novel view of ViTs showing that they can be seen as ensemble networks containing multiple parallel paths with different lengths. Specifically, we equivalently transform the traditional cascade of multi-head self-attention (MSA) and feed-forward network (FFN) into three parallel paths in each transformer layer. Then, we utilize the identity connection in our new transformer form and further transform the ViT into an explicit multi-path ensemble network. From the new perspective, these paths perform two functions: the first is to provide the feature for the classifier directly, and the second is to provide the lower-level feature representation for subsequent longer paths. We investigate the influence of each path for the final prediction and discover that some paths even pull down the performance. Therefore, we propose the path pruning and EnsembleScale skills for improvement, which cut out the underperforming paths and re-weight the ensemble components, respectively, to optimize the path combination and make the short paths focus on providing high-quality representation for subsequent paths. We also demonstrate that our path combination strategies can help ViTs go deeper and act as high-pass filters to filter out partial low-frequency signals. To further enhance the representation of paths served for subsequent paths, self-distillation is applied to transfer knowledge from the long paths to the short paths. This work calls for more future research to explain and design ViTs from new perspectives.
Mix-of-Show: Decentralized Low-Rank Adaptation for Multi-Concept Customization of Diffusion Models
May 29, 2023Public large-scale text-to-image diffusion models, such as Stable Diffusion, have gained significant attention from the community. These models can be easily customized for new concepts using low-rank adaptations (LoRAs). However, the utilization of multiple concept LoRAs to jointly support multiple customized concepts presents a challenge. We refer to this scenario as decentralized multi-concept customization, which involves single-client concept tuning and center-node concept fusion. In this paper, we propose a new framework called Mix-of-Show that addresses the challenges of decentralized multi-concept customization, including concept conflicts resulting from existing single-client LoRA tuning and identity loss during model fusion. Mix-of-Show adopts an embedding-decomposed LoRA (ED-LoRA) for single-client tuning and gradient fusion for the center node to preserve the in-domain essence of single concepts and support theoretically limitless concept fusion. Additionally, we introduce regionally controllable sampling, which extends spatially controllable sampling (e.g., ControlNet and T2I-Adaptor) to address attribute binding and missing object problems in multi-concept sampling. Extensive experiments demonstrate that Mix-of-Show is capable of composing multiple customized concepts with high fidelity, including characters, objects, and scenes.
DOAD: Decoupled One Stage Action Detection Network
Apr 04, 2023



Localizing people and recognizing their actions from videos is a challenging task towards high-level video understanding. Existing methods are mostly two-stage based, with one stage for person bounding box generation and the other stage for action recognition. However, such two-stage methods are generally with low efficiency. We observe that directly unifying detection and action recognition normally suffers from (i) inferior learning due to different desired properties of context representation for detection and action recognition; (ii) optimization difficulty with insufficient training data. In this work, we present a decoupled one-stage network dubbed DOAD, to mitigate above issues and improve the efficiency for spatio-temporal action detection. To achieve it, we decouple detection and action recognition into two branches. Specifically, one branch focuses on detection representation for actor detection, and the other one for action recognition. For the action branch, we design a transformer-based module (TransPC) to model pairwise relationships between people and context. Different from commonly used vector-based dot product in self-attention, it is built upon a novel matrix-based key and value for Hadamard attention to model person-context information. It not only exploits relationships between person pairs but also takes into account context and relative position information. The results on AVA and UCF101-24 datasets show that our method is competitive with two-stage state-of-the-art methods with significant efficiency improvement.
Making Vision Transformers Efficient from A Token Sparsification View
Mar 30, 2023



The quadratic computational complexity to the number of tokens limits the practical applications of Vision Transformers (ViTs). Several works propose to prune redundant tokens to achieve efficient ViTs. However, these methods generally suffer from (i) dramatic accuracy drops, (ii) application difficulty in the local vision transformer, and (iii) non-general-purpose networks for downstream tasks. In this work, we propose a novel Semantic Token ViT (STViT), for efficient global and local vision transformers, which can also be revised to serve as backbone for downstream tasks. The semantic tokens represent cluster centers, and they are initialized by pooling image tokens in space and recovered by attention, which can adaptively represent global or local semantic information. Due to the cluster properties, a few semantic tokens can attain the same effect as vast image tokens, for both global and local vision transformers. For instance, only 16 semantic tokens on DeiT-(Tiny,Small,Base) can achieve the same accuracy with more than 100% inference speed improvement and nearly 60% FLOPs reduction; on Swin-(Tiny,Small,Base), we can employ 16 semantic tokens in each window to further speed it up by around 20% with slight accuracy increase. Besides great success in image classification, we also extend our method to video recognition. In addition, we design a STViT-R(ecover) network to restore the detailed spatial information based on the STViT, making it work for downstream tasks, which is powerless for previous token sparsification methods. Experiments demonstrate that our method can achieve competitive results compared to the original networks in object detection and instance segmentation, with over 30% FLOPs reduction for backbone. Code is available at http://github.com/changsn/STViT-R
KVT: k-NN Attention for Boosting Vision Transformers
May 28, 2021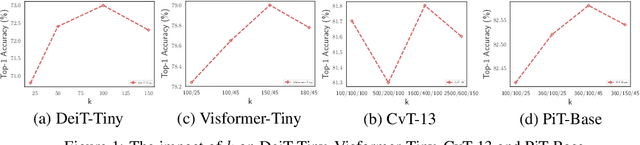
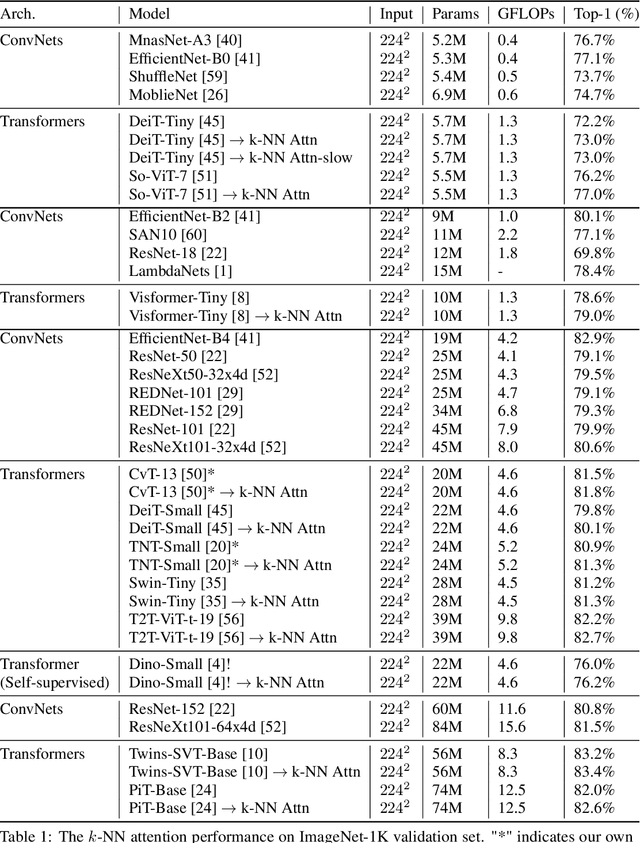
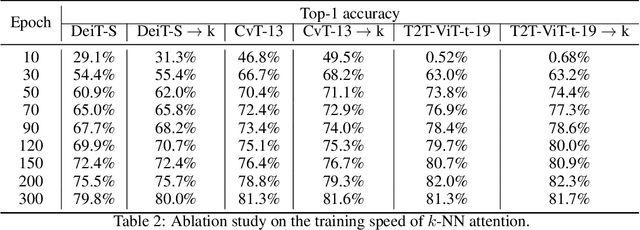
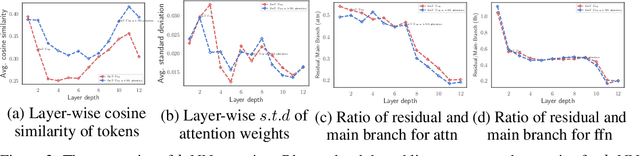
Convolutional Neural Networks (CNNs) have dominated computer vision for years, due to its ability in capturing locality and translation invariance. Recently, many vision transformer architectures have been proposed and they show promising performance. A key component in vision transformers is the fully-connected self-attention which is more powerful than CNNs in modelling long range dependencies. However, since the current dense self-attention uses all image patches (tokens) to compute attention matrix, it may neglect locality of images patches and involve noisy tokens (e.g., clutter background and occlusion), leading to a slow training process and potentially degradation of performance. To address these problems, we propose a sparse attention scheme, dubbed k-NN attention, for boosting vision transformers. Specifically, instead of involving all the tokens for attention matrix calculation, we only select the top-k similar tokens from the keys for each query to compute the attention map. The proposed k-NN attention naturally inherits the local bias of CNNs without introducing convolutional operations, as nearby tokens tend to be more similar than others. In addition, the k-NN attention allows for the exploration of long range correlation and at the same time filter out irrelevant tokens by choosing the most similar tokens from the entire image. Despite its simplicity, we verify, both theoretically and empirically, that $k$-NN attention is powerful in distilling noise from input tokens and in speeding up training. Extensive experiments are conducted by using ten different vision transformer architectures to verify that the proposed k-NN attention can work with any existing transformer architectures to improve its prediction performance.
Augmented Transformer with Adaptive Graph for Temporal Action Proposal Generation
Mar 30, 2021



Temporal action proposal generation (TAPG) is a fundamental and challenging task in video understanding, especially in temporal action detection. Most previous works focus on capturing the local temporal context and can well locate simple action instances with clean frames and clear boundaries. However, they generally fail in complicated scenarios where interested actions involve irrelevant frames and background clutters, and the local temporal context becomes less effective. To deal with these problems, we present an augmented transformer with adaptive graph network (ATAG) to exploit both long-range and local temporal contexts for TAPG. Specifically, we enhance the vanilla transformer by equipping a snippet actionness loss and a front block, dubbed augmented transformer, and it improves the abilities of capturing long-range dependencies and learning robust feature for noisy action instances.Moreover, an adaptive graph convolutional network (GCN) is proposed to build local temporal context by mining the position information and difference between adjacent features. The features from the two modules carry rich semantic information of the video, and are fused for effective sequential proposal generation. Extensive experiments are conducted on two challenging datasets, THUMOS14 and ActivityNet1.3, and the results demonstrate that our method outperforms state-of-the-art TAPG methods. Our code will be released soon.
Towards Accurate Human Pose Estimation in Videos of Crowded Scenes
Oct 21, 2020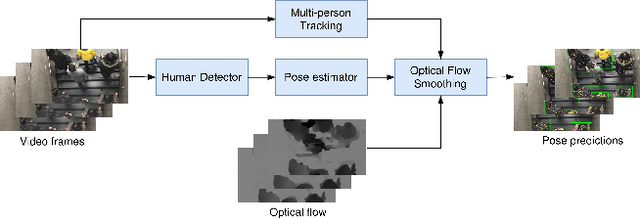

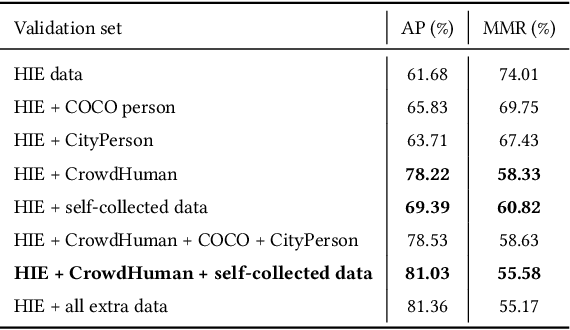
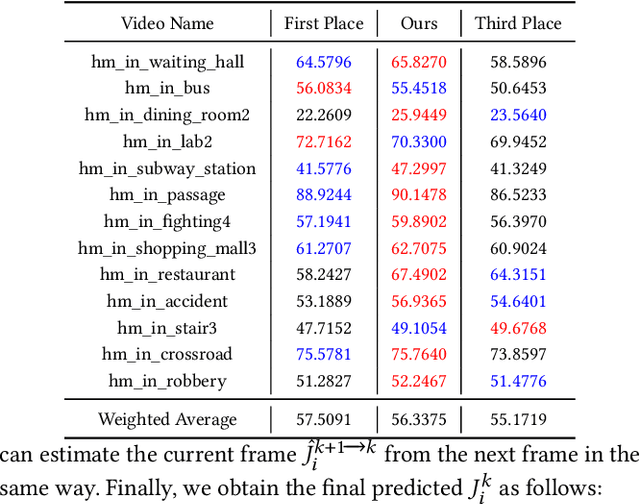
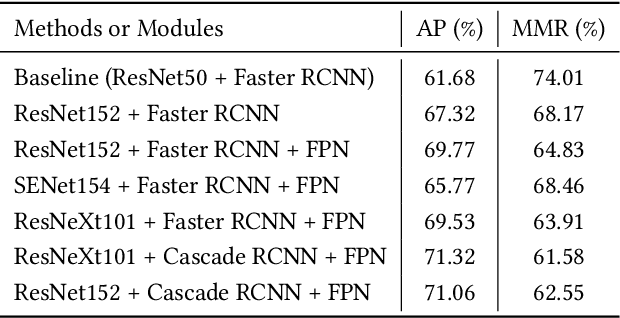
Video-based human pose estimation in crowded scenes is a challenging problem due to occlusion, motion blur, scale variation and viewpoint change, etc. Prior approaches always fail to deal with this problem because of (1) lacking of usage of temporal information; (2) lacking of training data in crowded scenes. In this paper, we focus on improving human pose estimation in videos of crowded scenes from the perspectives of exploiting temporal context and collecting new data. In particular, we first follow the top-down strategy to detect persons and perform single-person pose estimation for each frame. Then, we refine the frame-based pose estimation with temporal contexts deriving from the optical-flow. Specifically, for one frame, we forward the historical poses from the previous frames and backward the future poses from the subsequent frames to current frame, leading to stable and accurate human pose estimation in videos. In addition, we mine new data of similar scenes to HIE dataset from the Internet for improving the diversity of training set. In this way, our model achieves best performance on 7 out of 13 videos and 56.33 average w\_AP on test dataset of HIE challenge.
A Simple Baseline for Pose Tracking in Videos of Crowded Scenes
Oct 21, 2020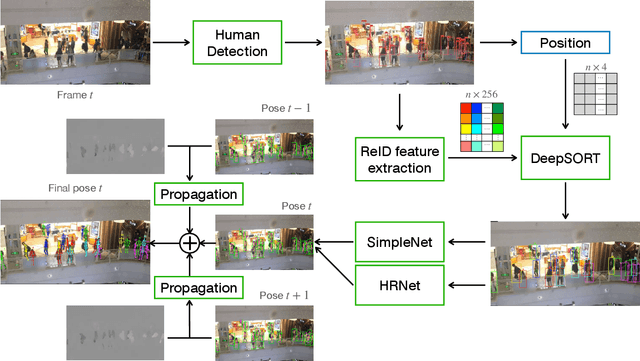
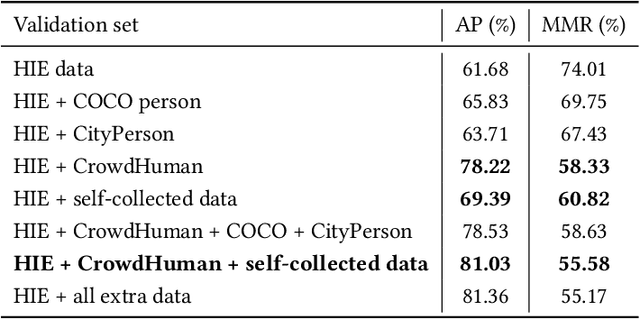

This paper presents our solution to ACM MM challenge: Large-scale Human-centric Video Analysis in Complex Events\cite{lin2020human}; specifically, here we focus on Track3: Crowd Pose Tracking in Complex Events. Remarkable progress has been made in multi-pose training in recent years. However, how to track the human pose in crowded and complex environments has not been well addressed. We formulate the problem as several subproblems to be solved. First, we use a multi-object tracking method to assign human ID to each bounding box generated by the detection model. After that, a pose is generated to each bounding box with ID. At last, optical flow is used to take advantage of the temporal information in the videos and generate the final pose tracking result.