 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeD-OPSD: On-Policy Self-Distillation for Continuously Tuning Step-Distilled Diffusion Models
May 06, 2026The landscape of high-performance image generation models is currently shifting from the inefficient multi-step ones to the efficient few-step counterparts (e.g, Z-Image-Turbo and FLUX.2-klein). However, these models present significant challenges for directly continuous supervised fine-tuning. For example, applying the commonly used fine-tuning technique would compromises their inherent few-step inference capability. To address this, we propose D-OPSD, a novel training paradigm for step-distilled diffusion models that enables on-policy learning during supervised fine-tuning. We first find that the modern diffusion model where the LLM/VLM serves as the encoder can inherit its encoder's in-context capabilities. This enables us to make the training as an on-policy self-distillation process. Specifically, during training, we make the model acts as both the teacher and the student with different contexts, where the student is conditioned only on the text feature, while the teacher is conditioned on the multimodal feature of both the text prompt and the target image. Training minimizes the two predicted distributions over the student's own roll-outs. By optimized on the model's own trajectory and under it's own supervision, D-OPSD enables the model to learn new concept, style, etc. without sacrificing the original few-step capacity.
OMG-Avatar: One-shot Multi-LOD Gaussian Head Avatar
Mar 02, 2026We propose OMG-Avatar, a novel One-shot method that leverages a Multi-LOD (Level-of-Detail) Gaussian representation for animatable 3D head reconstruction from a single image in 0.2s. Our method enables LOD head avatar modeling using a unified model that accommodates diverse hardware capabilities and inference speed requirements. To capture both global and local facial characteristics, we employ a transformer-based architecture for global feature extraction and projection-based sampling for local feature acquisition. These features are effectively fused under the guidance of a depth buffer, ensuring occlusion plausibility. We further introduce a coarse-to-fine learning paradigm to support Level-of-Detail functionality and enhance the perception of hierarchical details. To address the limitations of 3DMMs in modeling non-head regions such as the shoulders, we introduce a multi-region decomposition scheme in which the head and shoulders are predicted separately and then integrated through cross-region combination. Extensive experiments demonstrate that OMG-Avatar outperforms state-of-the-art methods in reconstruction quality, reenactment performance, and computational efficiency.
MAI-UI Technical Report: Real-World Centric Foundation GUI Agents
Dec 26, 2025



The development of GUI agents could revolutionize the next generation of human-computer interaction. Motivated by this vision, we present MAI-UI, a family of foundation GUI agents spanning the full spectrum of sizes, including 2B, 8B, 32B, and 235B-A22B variants. We identify four key challenges to realistic deployment: the lack of native agent-user interaction, the limits of UI-only operation, the absence of a practical deployment architecture, and brittleness in dynamic environments. MAI-UI addresses these issues with a unified methodology: a self-evolving data pipeline that expands the navigation data to include user interaction and MCP tool calls, a native device-cloud collaboration system routes execution by task state, and an online RL framework with advanced optimizations to scale parallel environments and context length. MAI-UI establishes new state-of-the-art across GUI grounding and mobile navigation. On grounding benchmarks, it reaches 73.5% on ScreenSpot-Pro, 91.3% on MMBench GUI L2, 70.9% on OSWorld-G, and 49.2% on UI-Vision, surpassing Gemini-3-Pro and Seed1.8 on ScreenSpot-Pro. On mobile GUI navigation, it sets a new SOTA of 76.7% on AndroidWorld, surpassing UI-Tars-2, Gemini-2.5-Pro and Seed1.8. On MobileWorld, MAI-UI obtains 41.7% success rate, significantly outperforming end-to-end GUI models and competitive with Gemini-3-Pro based agentic frameworks. Our online RL experiments show significant gains from scaling parallel environments from 32 to 512 (+5.2 points) and increasing environment step budget from 15 to 50 (+4.3 points). Finally, the native device-cloud collaboration system improves on-device performance by 33%, reduces cloud model calls by over 40%, and preserves user privacy.
MobileWorld: Benchmarking Autonomous Mobile Agents in Agent-User Interactive, and MCP-Augmented Environments
Dec 22, 2025



Among existing online mobile-use benchmarks, AndroidWorld has emerged as the dominant benchmark due to its reproducible environment and deterministic evaluation; however, recent agents achieving over 90% success rates indicate its saturation and motivate the need for a more challenging benchmark. In addition, its environment lacks key application categories, such as e-commerce and enterprise communication, and does not reflect realistic mobile-use scenarios characterized by vague user instructions and hybrid tool usage. To bridge this gap, we introduce MobileWorld, a substantially more challenging benchmark designed to better reflect real-world mobile usage, comprising 201 tasks across 20 applications, while maintaining the same level of reproducible evaluation as AndroidWorld. The difficulty of MobileWorld is twofold. First, it emphasizes long-horizon tasks with cross-application interactions: MobileWorld requires nearly twice as many task-completion steps on average (27.8 vs. 14.3) and includes far more multi-application tasks (62.2% vs. 9.5%) compared to AndroidWorld. Second, MobileWorld extends beyond standard GUI manipulation by introducing novel task categories, including agent-user interaction and MCP-augmented tasks. To ensure robust evaluation, we provide snapshot-based container environment and precise functional verifications, including backend database inspection and task callback APIs. We further develop a planner-executor agentic framework with extended action spaces to support user interactions and MCP calls. Our results reveal a sharp performance drop compared to AndroidWorld, with the best agentic framework and end-to-end model achieving 51.7% and 20.9% success rates, respectively. Our analysis shows that current models struggle significantly with user interaction and MCP calls, offering a strategic roadmap toward more robust, next-generation mobile intelligence.
ViSA: 3D-Aware Video Shading for Real-Time Upper-Body Avatar Creation
Dec 09, 2025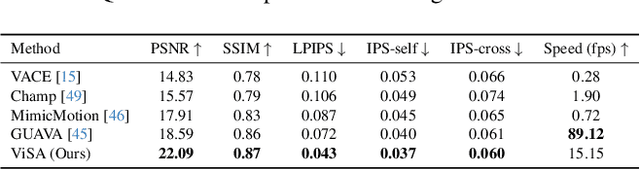
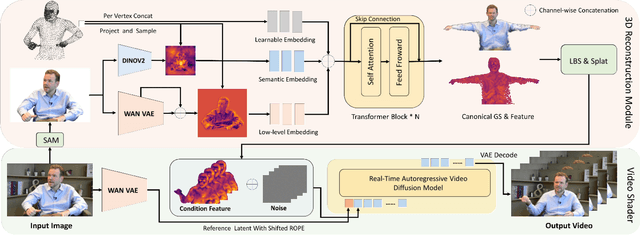
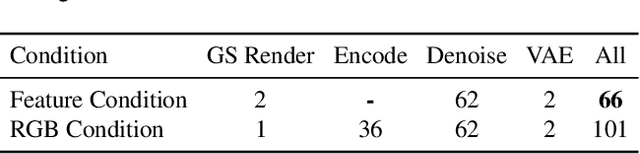
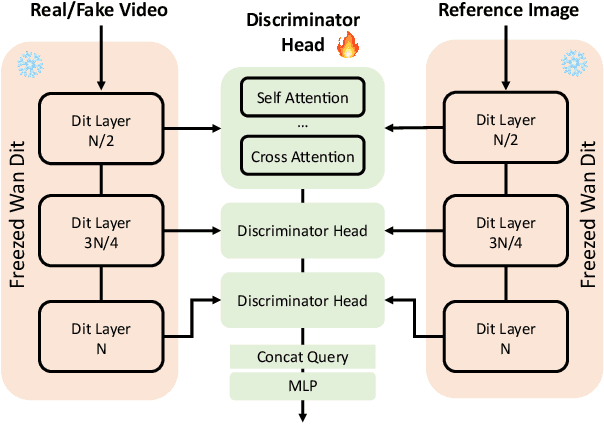
Generating high-fidelity upper-body 3D avatars from one-shot input image remains a significant challenge. Current 3D avatar generation methods, which rely on large reconstruction models, are fast and capable of producing stable body structures, but they often suffer from artifacts such as blurry textures and stiff, unnatural motion. In contrast, generative video models show promising performance by synthesizing photorealistic and dynamic results, but they frequently struggle with unstable behavior, including body structural errors and identity drift. To address these limitations, we propose a novel approach that combines the strengths of both paradigms. Our framework employs a 3D reconstruction model to provide robust structural and appearance priors, which in turn guides a real-time autoregressive video diffusion model for rendering. This process enables the model to synthesize high-frequency, photorealistic details and fluid dynamics in real time, effectively reducing texture blur and motion stiffness while preventing the structural inconsistencies common in video generation methods. By uniting the geometric stability of 3D reconstruction with the generative capabilities of video models, our method produces high-fidelity digital avatars with realistic appearance and dynamic, temporally coherent motion. Experiments demonstrate that our approach significantly reduces artifacts and achieves substantial improvements in visual quality over leading methods, providing a robust and efficient solution for real-time applications such as gaming and virtual reality. Project page: https://lhyfst.github.io/visa
Distribution Matching Distillation Meets Reinforcement Learning
Nov 19, 2025Distribution Matching Distillation (DMD) distills a pre-trained multi-step diffusion model to a few-step one to improve inference efficiency. However, the performance of the latter is often capped by the former. To circumvent this dilemma, we propose DMDR, a novel framework that combines Reinforcement Learning (RL) techniques into the distillation process. We show that for the RL of the few-step generator, the DMD loss itself is a more effective regularization compared to the traditional ones. In turn, RL can help to guide the mode coverage process in DMD more effectively. These allow us to unlock the capacity of the few-step generator by conducting distillation and RL simultaneously. Meanwhile, we design the dynamic distribution guidance and dynamic renoise sampling training strategies to improve the initial distillation process. The experiments demonstrate that DMDR can achieve leading visual quality, prompt coherence among few-step methods, and even exhibit performance that exceeds the multi-step teacher.
Let's Revise Step-by-Step: A Unified Local Search Framework for Code Generation with LLMs
Aug 10, 2025Large Language Models (LLMs) with inference-time scaling techniques show promise for code generation, yet face notable efficiency and scalability challenges. Construction-based tree-search methods suffer from rapid growth in tree size, high token consumption, and lack of anytime property. In contrast, improvement-based methods offer better performance but often struggle with uninformative reward signals and inefficient search strategies. In this work, we propose \textbf{ReLoc}, a unified local search framework which effectively performs step-by-step code revision. Specifically, ReLoc explores a series of local revisions through four key algorithmic components: initial code drafting, neighborhood code generation, candidate evaluation, and incumbent code updating, each of which can be instantiated with specific decision rules to realize different local search algorithms such as Hill Climbing (HC) or Genetic Algorithm (GA). Furthermore, we develop a specialized revision reward model that evaluates code quality based on revision distance to produce fine-grained preferences that guide the local search toward more promising candidates. Finally, our extensive experimental results demonstrate that our approach achieves superior performance across diverse code generation tasks, significantly outperforming both construction-based tree search as well as the state-of-the-art improvement-based code generation methods.
OmniAvatar: Efficient Audio-Driven Avatar Video Generation with Adaptive Body Animation
Jun 23, 2025Significant progress has been made in audio-driven human animation, while most existing methods focus mainly on facial movements, limiting their ability to create full-body animations with natural synchronization and fluidity. They also struggle with precise prompt control for fine-grained generation. To tackle these challenges, we introduce OmniAvatar, an innovative audio-driven full-body video generation model that enhances human animation with improved lip-sync accuracy and natural movements. OmniAvatar introduces a pixel-wise multi-hierarchical audio embedding strategy to better capture audio features in the latent space, enhancing lip-syncing across diverse scenes. To preserve the capability for prompt-driven control of foundation models while effectively incorporating audio features, we employ a LoRA-based training approach. Extensive experiments show that OmniAvatar surpasses existing models in both facial and semi-body video generation, offering precise text-based control for creating videos in various domains, such as podcasts, human interactions, dynamic scenes, and singing. Our project page is https://omni-avatar.github.io/.
CompeteSMoE -- Effective Training of Sparse Mixture of Experts via Competition
Feb 04, 2024



Sparse mixture of experts (SMoE) offers an appealing solution to scale up the model complexity beyond the mean of increasing the network's depth or width. However, effective training of SMoE has proven to be challenging due to the representation collapse issue, which causes parameter redundancy and limited representation potentials. In this work, we propose a competition mechanism to address this fundamental challenge of representation collapse. By routing inputs only to experts with the highest neural response, we show that, under mild assumptions, competition enjoys the same convergence rate as the optimal estimator. We further propose CompeteSMoE, an effective and efficient algorithm to train large language models by deploying a simple router that predicts the competition outcomes. Consequently, CompeteSMoE enjoys strong performance gains from the competition routing policy while having low computation overheads. Our extensive empirical evaluations on two transformer architectures and a wide range of tasks demonstrate the efficacy, robustness, and scalability of CompeteSMoE compared to state-of-the-art SMoE strategies.
HyperRouter: Towards Efficient Training and Inference of Sparse Mixture of Experts
Dec 12, 2023



By routing input tokens to only a few split experts, Sparse Mixture-of-Experts has enabled efficient training of large language models. Recent findings suggest that fixing the routers can achieve competitive performance by alleviating the collapsing problem, where all experts eventually learn similar representations. However, this strategy has two key limitations: (i) the policy derived from random routers might be sub-optimal, and (ii) it requires extensive resources during training and evaluation, leading to limited efficiency gains. This work introduces \HyperRout, which dynamically generates the router's parameters through a fixed hypernetwork and trainable embeddings to achieve a balance between training the routers and freezing them to learn an improved routing policy. Extensive experiments across a wide range of tasks demonstrate the superior performance and efficiency gains of \HyperRouter compared to existing routing methods. Our implementation is publicly available at {\url{{https://github.com/giangdip2410/HyperRouter}}}.