 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLiDAR Prompted Spatio-Temporal Multi-View Stereo for Autonomous Driving
Mar 04, 2026Accurate metric depth is critical for autonomous driving perception and simulation, yet current approaches struggle to achieve high metric accuracy, multi-view and temporal consistency, and cross-domain generalization. To address these challenges, we present DriveMVS, a novel multi-view stereo framework that reconciles these competing objectives through two key insights: (1) Sparse but metrically accurate LiDAR observations can serve as geometric prompts to anchor depth estimation in absolute scale, and (2) deep fusion of diverse cues is essential for resolving ambiguities and enhancing robustness, while a spatio-temporal decoder ensures consistency across frames. Built upon these principles, DriveMVS embeds the LiDAR prompt in two ways: as a hard geometric prior that anchors the cost volume, and as soft feature-wise guidance fused by a triple-cue combiner. Regarding temporal consistency, DriveMVS employs a spatio-temporal decoder that jointly leverages geometric cues from the MVS cost volume and temporal context from neighboring frames. Experiments show that DriveMVS achieves state-of-the-art performance on multiple benchmarks, excelling in metric accuracy, temporal stability, and zero-shot cross-domain transfer, demonstrating its practical value for scalable, reliable autonomous driving systems.
SAM4D: Segment Anything in Camera and LiDAR Streams
Jun 26, 2025


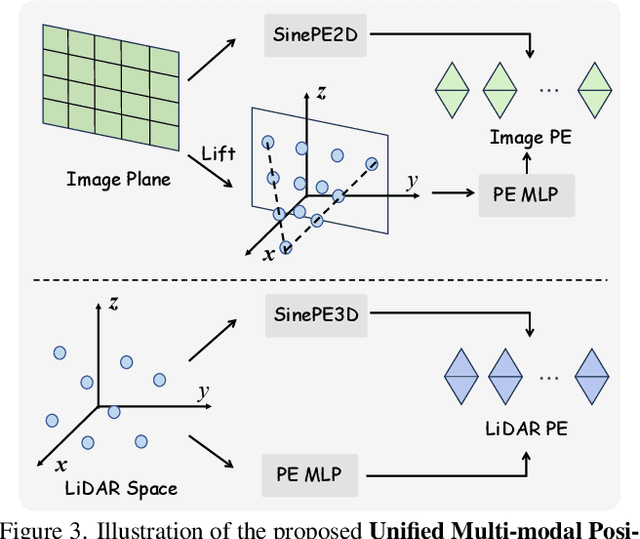
We present SAM4D, a multi-modal and temporal foundation model designed for promptable segmentation across camera and LiDAR streams. Unified Multi-modal Positional Encoding (UMPE) is introduced to align camera and LiDAR features in a shared 3D space, enabling seamless cross-modal prompting and interaction. Additionally, we propose Motion-aware Cross-modal Memory Attention (MCMA), which leverages ego-motion compensation to enhance temporal consistency and long-horizon feature retrieval, ensuring robust segmentation across dynamically changing autonomous driving scenes. To avoid annotation bottlenecks, we develop a multi-modal automated data engine that synergizes VFM-driven video masklets, spatiotemporal 4D reconstruction, and cross-modal masklet fusion. This framework generates camera-LiDAR aligned pseudo-labels at a speed orders of magnitude faster than human annotation while preserving VFM-derived semantic fidelity in point cloud representations. We conduct extensive experiments on the constructed Waymo-4DSeg, which demonstrate the powerful cross-modal segmentation ability and great potential in data annotation of proposed SAM4D.
Para-Lane: Multi-Lane Dataset Registering Parallel Scans for Benchmarking Novel View Synthesis
Feb 21, 2025To evaluate end-to-end autonomous driving systems, a simulation environment based on Novel View Synthesis (NVS) techniques is essential, which synthesizes photo-realistic images and point clouds from previously recorded sequences under new vehicle poses, particularly in cross-lane scenarios. Therefore, the development of a multi-lane dataset and benchmark is necessary. While recent synthetic scene-based NVS datasets have been prepared for cross-lane benchmarking, they still lack the realism of captured images and point clouds. To further assess the performance of existing methods based on NeRF and 3DGS, we present the first multi-lane dataset registering parallel scans specifically for novel driving view synthesis dataset derived from real-world scans, comprising 25 groups of associated sequences, including 16,000 front-view images, 64,000 surround-view images, and 16,000 LiDAR frames. All frames are labeled to differentiate moving objects from static elements. Using this dataset, we evaluate the performance of existing approaches in various testing scenarios at different lanes and distances. Additionally, our method provides the solution for solving and assessing the quality of multi-sensor poses for multi-modal data alignment for curating such a dataset in real-world. We plan to continually add new sequences to test the generalization of existing methods across different scenarios. The dataset is released publicly at the project page: https://nizqleo.github.io/paralane-dataset/.