 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePaLM 2 Technical Report
May 17, 2023



We introduce PaLM 2, a new state-of-the-art language model that has better multilingual and reasoning capabilities and is more compute-efficient than its predecessor PaLM. PaLM 2 is a Transformer-based model trained using a mixture of objectives. Through extensive evaluations on English and multilingual language, and reasoning tasks, we demonstrate that PaLM 2 has significantly improved quality on downstream tasks across different model sizes, while simultaneously exhibiting faster and more efficient inference compared to PaLM. This improved efficiency enables broader deployment while also allowing the model to respond faster, for a more natural pace of interaction. PaLM 2 demonstrates robust reasoning capabilities exemplified by large improvements over PaLM on BIG-Bench and other reasoning tasks. PaLM 2 exhibits stable performance on a suite of responsible AI evaluations, and enables inference-time control over toxicity without additional overhead or impact on other capabilities. Overall, PaLM 2 achieves state-of-the-art performance across a diverse set of tasks and capabilities. When discussing the PaLM 2 family, it is important to distinguish between pre-trained models (of various sizes), fine-tuned variants of these models, and the user-facing products that use these models. In particular, user-facing products typically include additional pre- and post-processing steps. Additionally, the underlying models may evolve over time. Therefore, one should not expect the performance of user-facing products to exactly match the results reported in this report.
Practical Conformer: Optimizing size, speed and flops of Conformer for on-Device and cloud ASR
Mar 31, 2023



Conformer models maintain a large number of internal states, the vast majority of which are associated with self-attention layers. With limited memory bandwidth, reading these from memory at each inference step can slow down inference. In this paper, we design an optimized conformer that is small enough to meet on-device restrictions and has fast inference on TPUs. We explore various ideas to improve the execution speed, including replacing lower conformer blocks with convolution-only blocks, strategically downsizing the architecture, and utilizing an RNNAttention-Performer. Our optimized conformer can be readily incorporated into a cascaded-encoder setting, allowing a second-pass decoder to operate on its output and improve the accuracy whenever more resources are available. Altogether, we find that these optimizations can reduce latency by a factor of 6.8x, and come at a reasonable trade-off in quality. With the cascaded second-pass, we show that the recognition accuracy is completely recoverable. Thus, our proposed encoder can double as a strong standalone encoder in on device, and as the first part of a high-performance ASR pipeline.
VILA: Learning Image Aesthetics from User Comments with Vision-Language Pretraining
Mar 24, 2023



Assessing the aesthetics of an image is challenging, as it is influenced by multiple factors including composition, color, style, and high-level semantics. Existing image aesthetic assessment (IAA) methods primarily rely on human-labeled rating scores, which oversimplify the visual aesthetic information that humans perceive. Conversely, user comments offer more comprehensive information and are a more natural way to express human opinions and preferences regarding image aesthetics. In light of this, we propose learning image aesthetics from user comments, and exploring vision-language pretraining methods to learn multimodal aesthetic representations. Specifically, we pretrain an image-text encoder-decoder model with image-comment pairs, using contrastive and generative objectives to learn rich and generic aesthetic semantics without human labels. To efficiently adapt the pretrained model for downstream IAA tasks, we further propose a lightweight rank-based adapter that employs text as an anchor to learn the aesthetic ranking concept. Our results show that our pretrained aesthetic vision-language model outperforms prior works on image aesthetic captioning over the AVA-Captions dataset, and it has powerful zero-shot capability for aesthetic tasks such as zero-shot style classification and zero-shot IAA, surpassing many supervised baselines. With only minimal finetuning parameters using the proposed adapter module, our model achieves state-of-the-art IAA performance over the AVA dataset.
CoBIT: A Contrastive Bi-directional Image-Text Generation Model
Mar 23, 2023



The field of vision and language has witnessed a proliferation of pre-trained foundation models. Most existing methods are independently pre-trained with contrastive objective like CLIP, image-to-text generative objective like PaLI, or text-to-image generative objective like Parti. However, the three objectives can be pre-trained on the same data, image-text pairs, and intuitively they complement each other as contrasting provides global alignment capacity and generation grants fine-grained understanding. In this work, we present a Contrastive Bi-directional Image-Text generation model (CoBIT), which attempts to unify the three pre-training objectives in one framework. Specifically, CoBIT employs a novel unicoder-decoder structure, consisting of an image unicoder, a text unicoder and a cross-modal decoder. The image/text unicoders can switch between encoding and decoding in different tasks, enabling flexibility and shared knowledge that benefits both image-to-text and text-to-image generations. CoBIT achieves superior performance in image understanding, image-text understanding (Retrieval, Captioning, VQA, SNLI-VE) and text-based content creation, particularly in zero-shot scenarios. For instance, 82.7% in zero-shot ImageNet classification, 9.37 FID score in zero-shot text-to-image generation and 44.8 CIDEr in zero-shot captioning.
Noise2Music: Text-conditioned Music Generation with Diffusion Models
Feb 08, 2023



We introduce Noise2Music, where a series of diffusion models is trained to generate high-quality 30-second music clips from text prompts. Two types of diffusion models, a generator model, which generates an intermediate representation conditioned on text, and a cascader model, which generates high-fidelity audio conditioned on the intermediate representation and possibly the text, are trained and utilized in succession to generate high-fidelity music. We explore two options for the intermediate representation, one using a spectrogram and the other using audio with lower fidelity. We find that the generated audio is not only able to faithfully reflect key elements of the text prompt such as genre, tempo, instruments, mood, and era, but goes beyond to ground fine-grained semantics of the prompt. Pretrained large language models play a key role in this story -- they are used to generate paired text for the audio of the training set and to extract embeddings of the text prompts ingested by the diffusion models. Generated examples: https://google-research.github.io/noise2music
Video-Text Modeling with Zero-Shot Transfer from Contrastive Captioners
Dec 09, 2022



This work explores an efficient approach to establish a foundational video-text model for tasks including open-vocabulary video classification, text-to-video retrieval, video captioning and video question-answering. We present VideoCoCa that reuses a pretrained image-text contrastive captioner (CoCa) model and adapt it to video-text tasks with minimal extra training. While previous works adapt image-text models with various cross-frame fusion modules (for example, cross-frame attention layer or perceiver resampler) and finetune the modified architecture on video-text data, we surprisingly find that the generative attentional pooling and contrastive attentional pooling layers in the image-text CoCa design are instantly adaptable to ``flattened frame embeddings'', yielding a strong zero-shot transfer baseline for many video-text tasks. Specifically, the frozen image encoder of a pretrained image-text CoCa takes each video frame as inputs and generates \(N\) token embeddings per frame for totally \(T\) video frames. We flatten \(N \times T\) token embeddings as a long sequence of frozen video representation and apply CoCa's generative attentional pooling and contrastive attentional pooling on top. All model weights including pooling layers are directly loaded from an image-text CoCa pretrained model. Without any video or video-text data, VideoCoCa's zero-shot transfer baseline already achieves state-of-the-art results on zero-shot video classification on Kinetics 400/600/700, UCF101, HMDB51, and Charades, as well as zero-shot text-to-video retrieval on MSR-VTT and ActivityNet Captions. We also explore lightweight finetuning on top of VideoCoCa, and achieve strong results on video question-answering (iVQA, MSRVTT-QA, MSVD-QA) and video captioning (MSR-VTT, ActivityNet, Youcook2). Our approach establishes a simple and effective video-text baseline for future research.
Exploiting Category Names for Few-Shot Classification with Vision-Language Models
Dec 04, 2022Vision-language foundation models pretrained on large-scale data provide a powerful tool for many visual understanding tasks. Notably, many vision-language models build two encoders (visual and textual) that can map two modalities into the same embedding space. As a result, the learned representations achieve good zero-shot performance on tasks like image classification. However, when there are only a few examples per category, the potential of large vision-language models is often underperformed, mainly due to the gap between a large number of parameters and a relatively small amount of training data. This paper shows that we can significantly improve the performance of few-shot classification by using the category names to initialize the classification head. More interestingly, we can borrow the non-perfect category names, or even names from a foreign language, to improve the few-shot classification performance compared with random initialization. With the proposed category name initialization method, our model obtains the state-of-the-art performance on a number of few-shot image classification benchmarks (e.g., 87.37\% on ImageNet and 96.08\% on Stanford Cars, both using five-shot learning). We also investigate and analyze when the benefit of category names diminishes and how to use distillation to improve the performance of smaller models, providing guidance for future research.
Deep object detection for waterbird monitoring using aerial imagery
Oct 10, 2022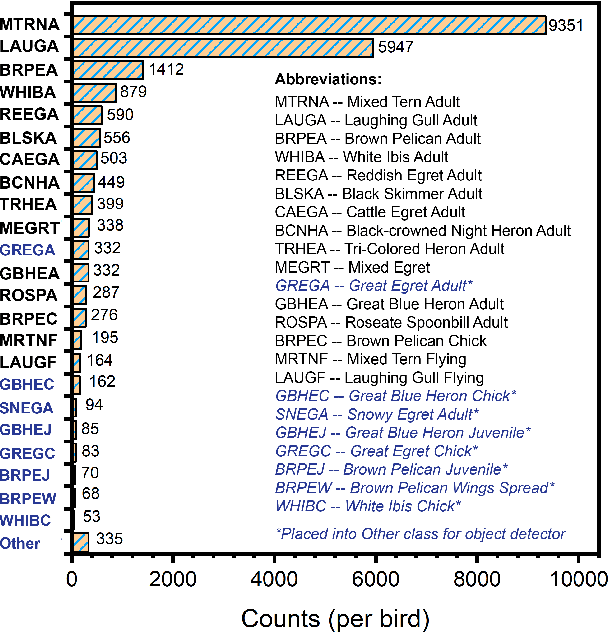
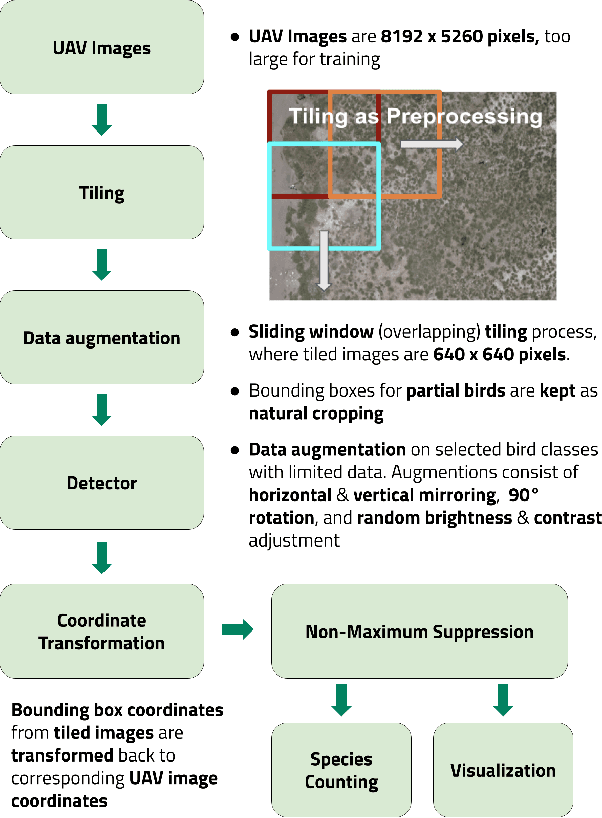
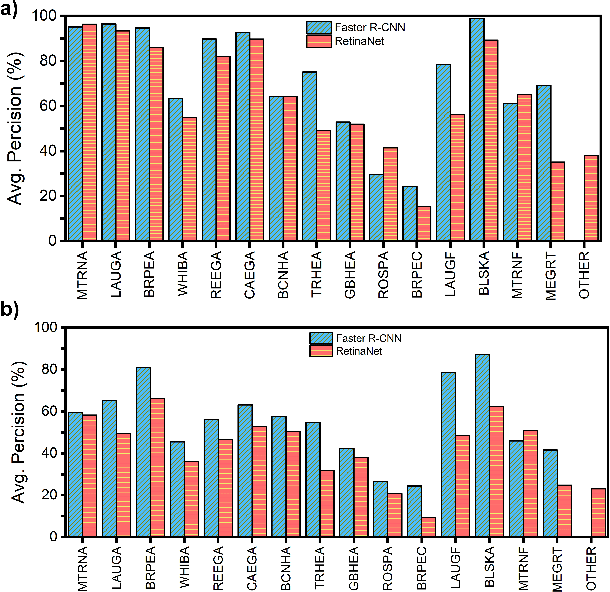
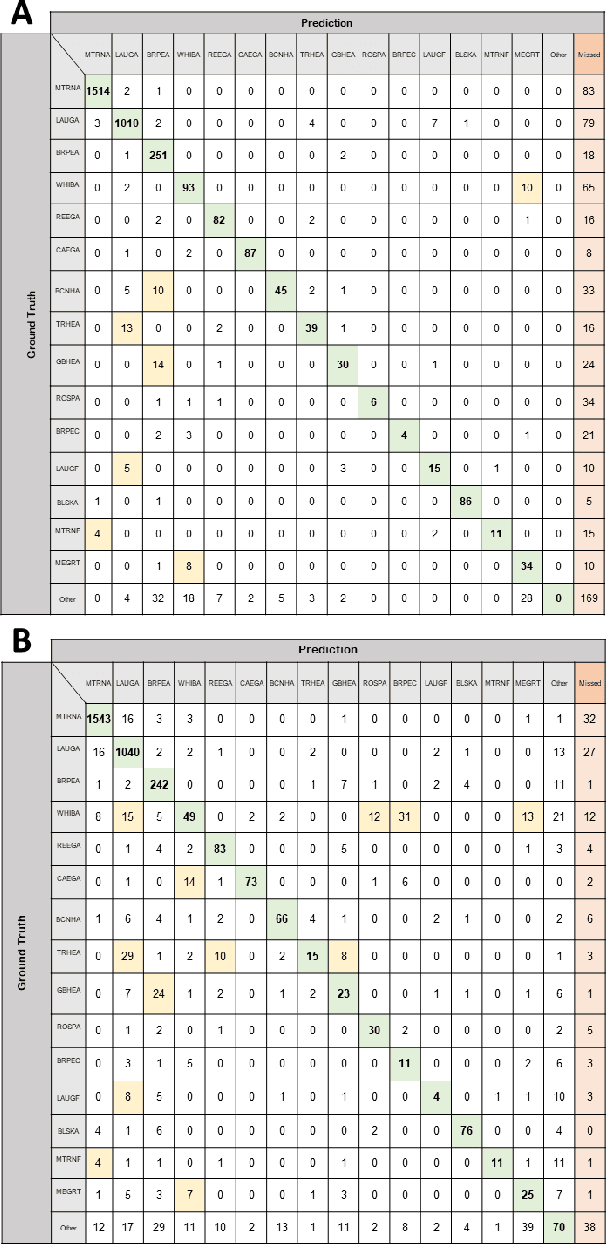
Monitoring of colonial waterbird nesting islands is essential to tracking waterbird population trends, which are used for evaluating ecosystem health and informing conservation management decisions. Recently, unmanned aerial vehicles, or drones, have emerged as a viable technology to precisely monitor waterbird colonies. However, manually counting waterbirds from hundreds, or potentially thousands, of aerial images is both difficult and time-consuming. In this work, we present a deep learning pipeline that can be used to precisely detect, count, and monitor waterbirds using aerial imagery collected by a commercial drone. By utilizing convolutional neural network-based object detectors, we show that we can detect 16 classes of waterbird species that are commonly found in colonial nesting islands along the Texas coast. Our experiments using Faster R-CNN and RetinaNet object detectors give mean interpolated average precision scores of 67.9% and 63.1% respectively.
Normalization effects on deep neural networks
Sep 02, 2022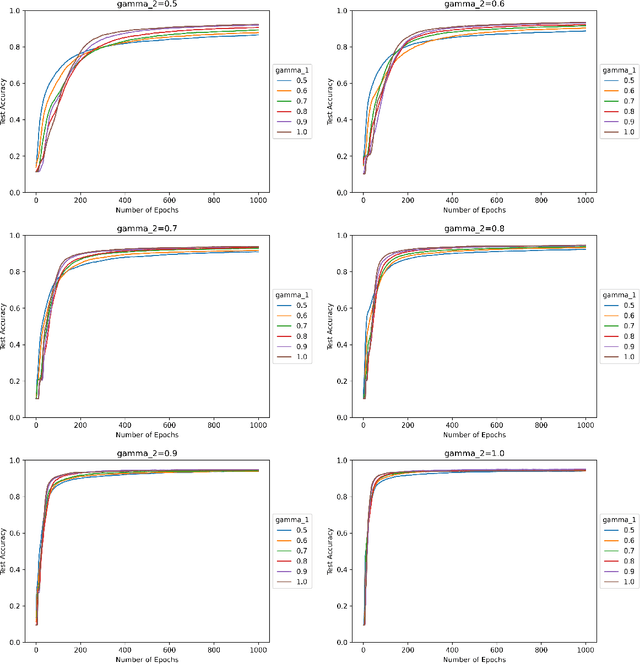
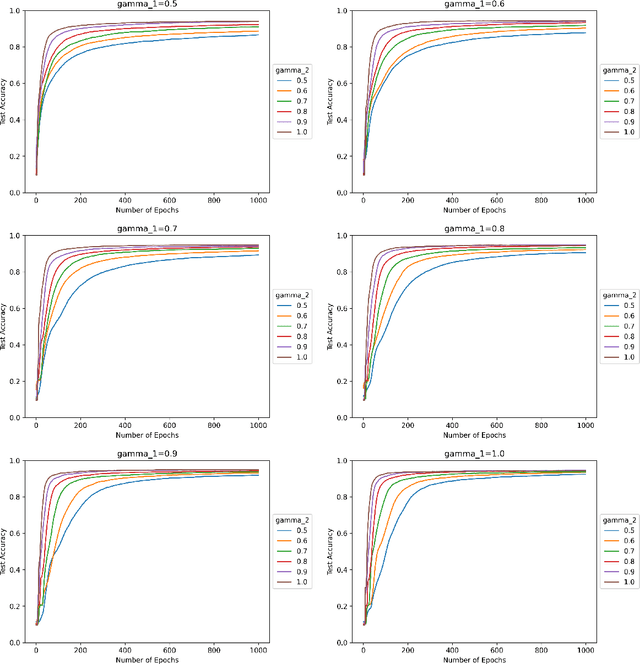
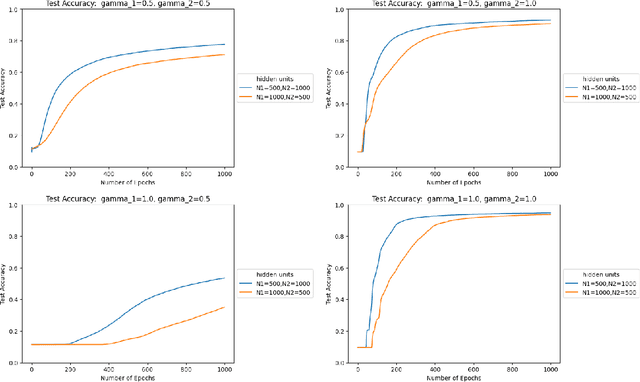
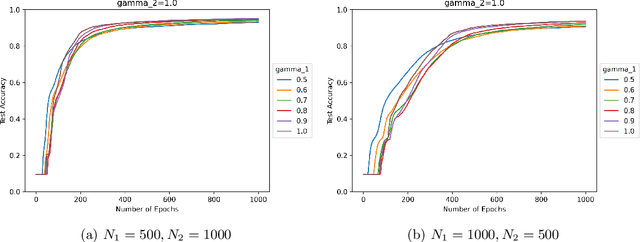
We study the effect of normalization on the layers of deep neural networks of feed-forward type. A given layer $i$ with $N_{i}$ hidden units is allowed to be normalized by $1/N_{i}^{\gamma_{i}}$ with $\gamma_{i}\in[1/2,1]$ and we study the effect of the choice of the $\gamma_{i}$ on the statistical behavior of the neural network's output (such as variance) as well as on the test accuracy on the MNIST data set. We find that in terms of variance of the neural network's output and test accuracy the best choice is to choose the $\gamma_{i}$'s to be equal to one, which is the mean-field scaling. We also find that this is particularly true for the outer layer, in that the neural network's behavior is more sensitive in the scaling of the outer layer as opposed to the scaling of the inner layers. The mechanism for the mathematical analysis is an asymptotic expansion for the neural network's output. An important practical consequence of the analysis is that it provides a systematic and mathematically informed way to choose the learning rate hyperparameters. Such a choice guarantees that the neural network behaves in a statistically robust way as the $N_i$ grow to infinity.
Scaling Autoregressive Models for Content-Rich Text-to-Image Generation
Jun 22, 2022

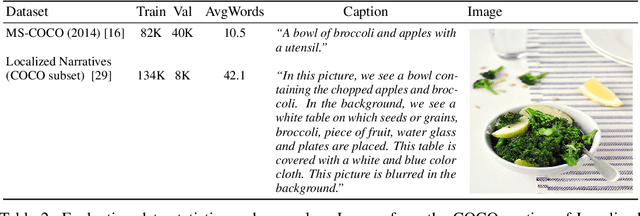
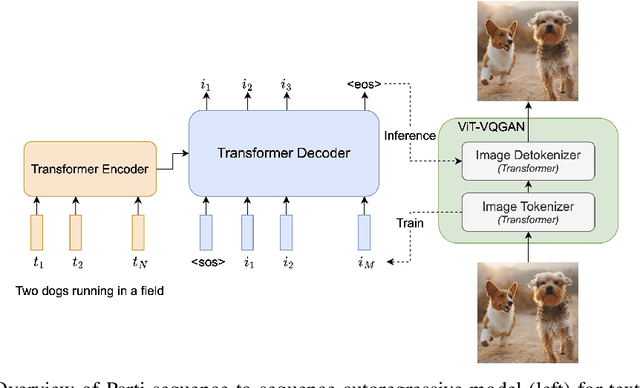
We present the Pathways Autoregressive Text-to-Image (Parti) model, which generates high-fidelity photorealistic images and supports content-rich synthesis involving complex compositions and world knowledge. Parti treats text-to-image generation as a sequence-to-sequence modeling problem, akin to machine translation, with sequences of image tokens as the target outputs rather than text tokens in another language. This strategy can naturally tap into the rich body of prior work on large language models, which have seen continued advances in capabilities and performance through scaling data and model sizes. Our approach is simple: First, Parti uses a Transformer-based image tokenizer, ViT-VQGAN, to encode images as sequences of discrete tokens. Second, we achieve consistent quality improvements by scaling the encoder-decoder Transformer model up to 20B parameters, with a new state-of-the-art zero-shot FID score of 7.23 and finetuned FID score of 3.22 on MS-COCO. Our detailed analysis on Localized Narratives as well as PartiPrompts (P2), a new holistic benchmark of over 1600 English prompts, demonstrate the effectiveness of Parti across a wide variety of categories and difficulty aspects. We also explore and highlight limitations of our models in order to define and exemplify key areas of focus for further improvements. See https://parti.research.google/ for high-resolution images.