 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImagen 3
Aug 13, 2024We introduce Imagen 3, a latent diffusion model that generates high quality images from text prompts. We describe our quality and responsibility evaluations. Imagen 3 is preferred over other state-of-the-art (SOTA) models at the time of evaluation. In addition, we discuss issues around safety and representation, as well as methods we used to minimize the potential harm of our models.
Gemma 2: Improving Open Language Models at a Practical Size
Aug 02, 2024



In this work, we introduce Gemma 2, a new addition to the Gemma family of lightweight, state-of-the-art open models, ranging in scale from 2 billion to 27 billion parameters. In this new version, we apply several known technical modifications to the Transformer architecture, such as interleaving local-global attentions (Beltagy et al., 2020a) and group-query attention (Ainslie et al., 2023). We also train the 2B and 9B models with knowledge distillation (Hinton et al., 2015) instead of next token prediction. The resulting models deliver the best performance for their size, and even offer competitive alternatives to models that are 2-3 times bigger. We release all our models to the community.
Exploiting Category Names for Few-Shot Classification with Vision-Language Models
Dec 04, 2022Vision-language foundation models pretrained on large-scale data provide a powerful tool for many visual understanding tasks. Notably, many vision-language models build two encoders (visual and textual) that can map two modalities into the same embedding space. As a result, the learned representations achieve good zero-shot performance on tasks like image classification. However, when there are only a few examples per category, the potential of large vision-language models is often underperformed, mainly due to the gap between a large number of parameters and a relatively small amount of training data. This paper shows that we can significantly improve the performance of few-shot classification by using the category names to initialize the classification head. More interestingly, we can borrow the non-perfect category names, or even names from a foreign language, to improve the few-shot classification performance compared with random initialization. With the proposed category name initialization method, our model obtains the state-of-the-art performance on a number of few-shot image classification benchmarks (e.g., 87.37\% on ImageNet and 96.08\% on Stanford Cars, both using five-shot learning). We also investigate and analyze when the benefit of category names diminishes and how to use distillation to improve the performance of smaller models, providing guidance for future research.
RC-DARTS: Resource Constrained Differentiable Architecture Search
Dec 30, 2019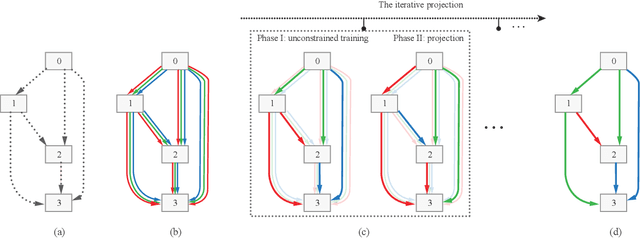
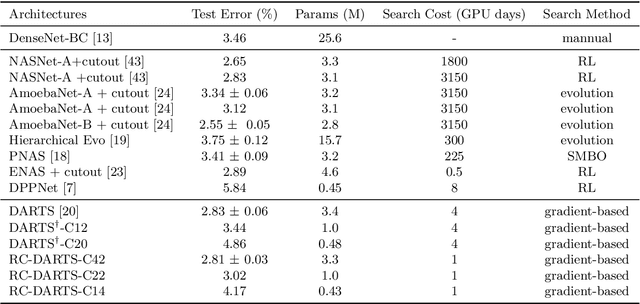
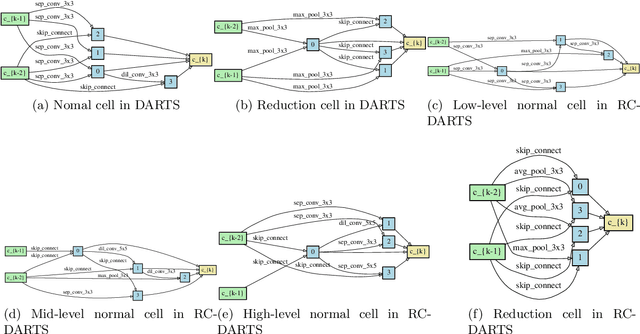
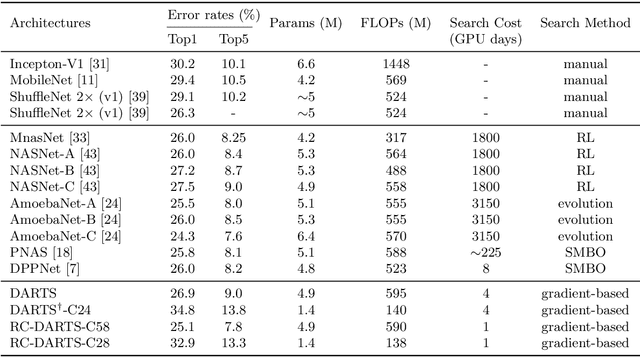
Recent advances show that Neural Architectural Search (NAS) method is able to find state-of-the-art image classification deep architectures. In this paper, we consider the one-shot NAS problem for resource constrained applications. This problem is of great interest because it is critical to choose different architectures according to task complexity when the resource is constrained. Previous techniques are either too slow for one-shot learning or does not take the resource constraint into consideration. In this paper, we propose the resource constrained differentiable architecture search (RC-DARTS) method to learn architectures that are significantly smaller and faster while achieving comparable accuracy. Specifically, we propose to formulate the RC-DARTS task as a constrained optimization problem by adding the resource constraint. An iterative projection method is proposed to solve the given constrained optimization problem. We also propose a multi-level search strategy to enable layers at different depths to adaptively learn different types of neural architectures. Through extensive experiments on the Cifar10 and ImageNet datasets, we show that the RC-DARTS method learns lightweight neural architectures which have smaller model size and lower computational complexity while achieving comparable or better performances than the state-of-the-art methods.
NOTE-RCNN: NOise Tolerant Ensemble RCNN for Semi-Supervised Object Detection
Dec 01, 2018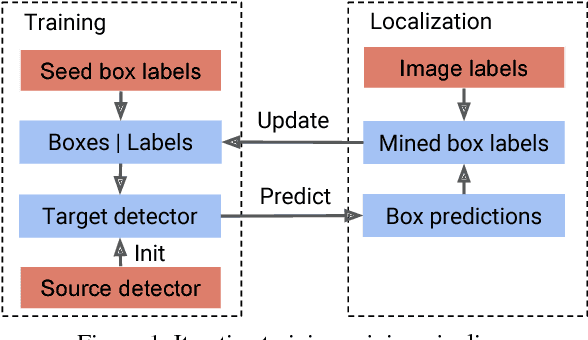
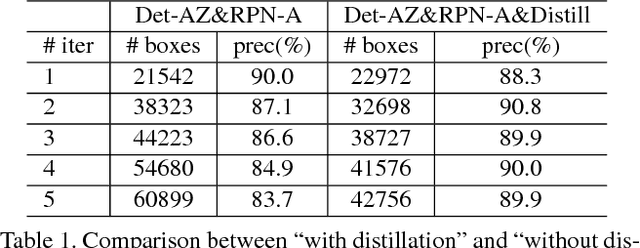

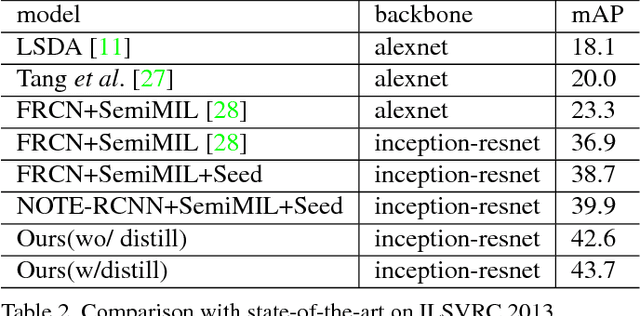
The labeling cost of large number of bounding boxes is one of the main challenges for training modern object detectors. To reduce the dependence on expensive bounding box annotations, we propose a new semi-supervised object detection formulation, in which a few seed box level annotations and a large scale of image level annotations are used to train the detector. We adopt a training-mining framework, which is widely used in weakly supervised object detection tasks. However, the mining process inherently introduces various kinds of labelling noises: false negatives, false positives and inaccurate boundaries, which can be harmful for training the standard object detectors (e.g. Faster RCNN). We propose a novel NOise Tolerant Ensemble RCNN (NOTE-RCNN) object detector to handle such noisy labels. Comparing to standard Faster RCNN, it contains three highlights: an ensemble of two classification heads and a distillation head to avoid overfitting on noisy labels and improve the mining precision, masking the negative sample loss in box predictor to avoid the harm of false negative labels, and training box regression head only on seed annotations to eliminate the harm from inaccurate boundaries of mined bounding boxes. We evaluate the methods on ILSVRC 2013 and MSCOCO 2017 dataset; we observe that the detection accuracy consistently improves as we iterate between mining and training steps, and state-of-the-art performance is achieved.