 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting Category Names for Few-Shot Classification with Vision-Language Models
Dec 04, 2022Vision-language foundation models pretrained on large-scale data provide a powerful tool for many visual understanding tasks. Notably, many vision-language models build two encoders (visual and textual) that can map two modalities into the same embedding space. As a result, the learned representations achieve good zero-shot performance on tasks like image classification. However, when there are only a few examples per category, the potential of large vision-language models is often underperformed, mainly due to the gap between a large number of parameters and a relatively small amount of training data. This paper shows that we can significantly improve the performance of few-shot classification by using the category names to initialize the classification head. More interestingly, we can borrow the non-perfect category names, or even names from a foreign language, to improve the few-shot classification performance compared with random initialization. With the proposed category name initialization method, our model obtains the state-of-the-art performance on a number of few-shot image classification benchmarks (e.g., 87.37\% on ImageNet and 96.08\% on Stanford Cars, both using five-shot learning). We also investigate and analyze when the benefit of category names diminishes and how to use distillation to improve the performance of smaller models, providing guidance for future research.
FlowNAS: Neural Architecture Search for Optical Flow Estimation
Jul 04, 2022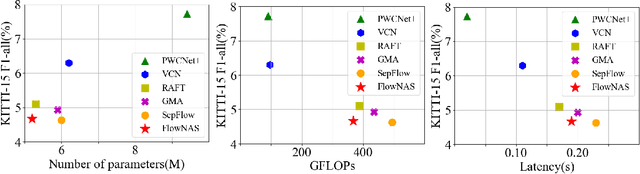
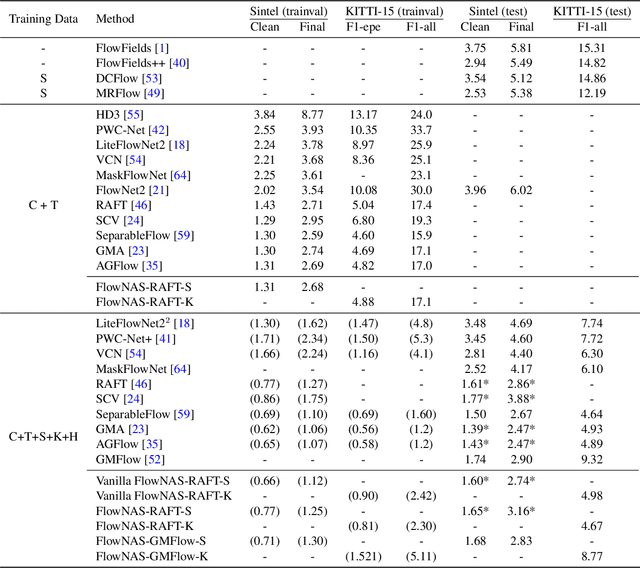
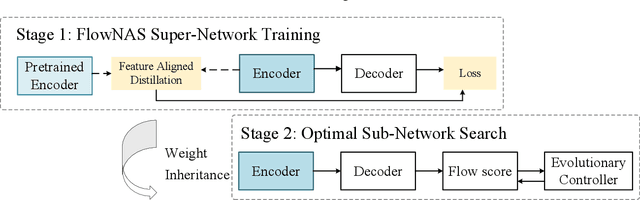
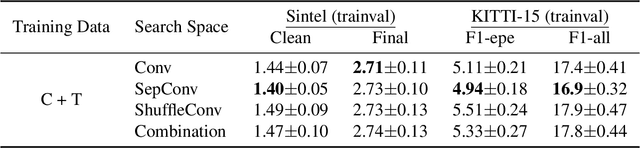
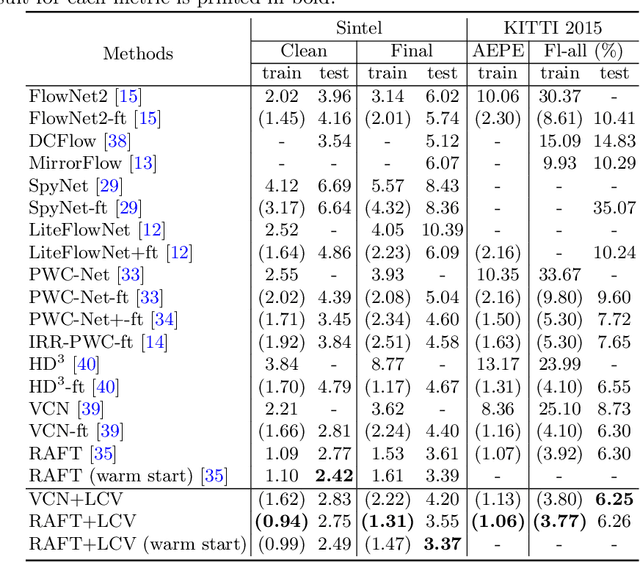
Existing optical flow estimators usually employ the network architectures typically designed for image classification as the encoder to extract per-pixel features. However, due to the natural difference between the tasks, the architectures designed for image classification may be sub-optimal for flow estimation. To address this issue, we propose a neural architecture search method named FlowNAS to automatically find the better encoder architecture for flow estimation task. We first design a suitable search space including various convolutional operators and construct a weight-sharing super-network for efficiently evaluating the candidate architectures. Then, for better training the super-network, we propose Feature Alignment Distillation, which utilizes a well-trained flow estimator to guide the training of super-network. Finally, a resource-constrained evolutionary algorithm is exploited to find an optimal architecture (i.e., sub-network). Experimental results show that the discovered architecture with the weights inherited from the super-network achieves 4.67\% F1-all error on KITTI, an 8.4\% reduction of RAFT baseline, surpassing state-of-the-art handcrafted models GMA and AGFlow, while reducing the model complexity and latency. The source code and trained models will be released in https://github.com/VDIGPKU/FlowNAS.
Adaptive Transformers for Robust Few-shot Cross-domain Face Anti-spoofing
Mar 23, 2022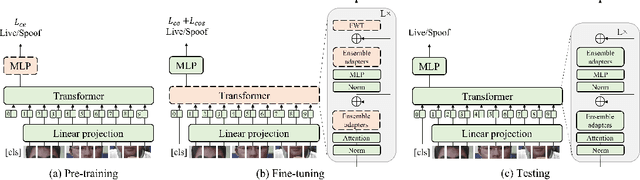
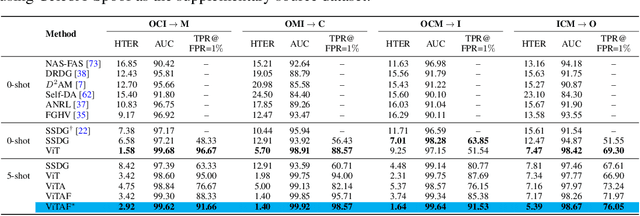
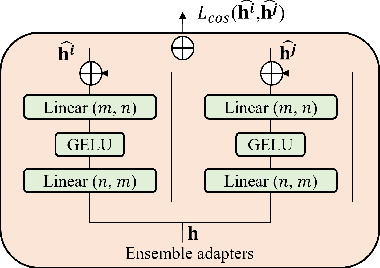
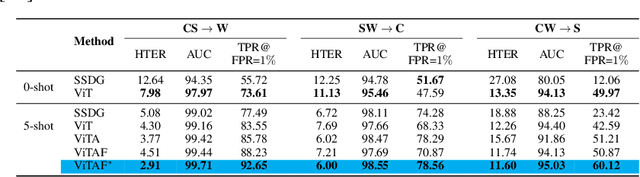
While recent face anti-spoofing methods perform well under the intra-domain setups, an effective approach needs to account for much larger appearance variations of images acquired in complex scenes with different sensors for robust performance. In this paper, we present adaptive vision transformers (ViT) for robust cross-domain face anti-spoofing. Specifically, we adopt ViT as a backbone to exploit its strength to account for long-range dependencies among pixels. We further introduce the ensemble adapters module and feature-wise transformation layers in the ViT to adapt to different domains for robust performance with a few samples. Experiments on several benchmark datasets show that the proposed models achieve both robust and competitive performance against the state-of-the-art methods.
Learning Contrastive Representation for Semantic Correspondence
Sep 22, 2021
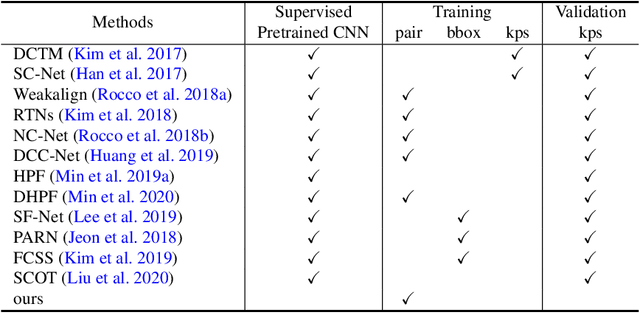
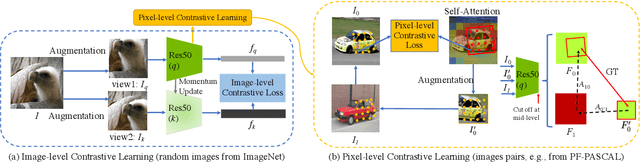

Dense correspondence across semantically related images has been extensively studied, but still faces two challenges: 1) large variations in appearance, scale and pose exist even for objects from the same category, and 2) labeling pixel-level dense correspondences is labor intensive and infeasible to scale. Most existing approaches focus on designing various matching approaches with fully-supervised ImageNet pretrained networks. On the other hand, while a variety of self-supervised approaches are proposed to explicitly measure image-level similarities, correspondence matching the pixel level remains under-explored. In this work, we propose a multi-level contrastive learning approach for semantic matching, which does not rely on any ImageNet pretrained model. We show that image-level contrastive learning is a key component to encourage the convolutional features to find correspondence between similar objects, while the performance can be further enhanced by regularizing cross-instance cycle-consistency at intermediate feature levels. Experimental results on the PF-PASCAL, PF-WILLOW, and SPair-71k benchmark datasets demonstrate that our method performs favorably against the state-of-the-art approaches. The source code and trained models will be made available to the public.
Learnable Cost Volume Using the Cayley Representation
Jul 21, 2020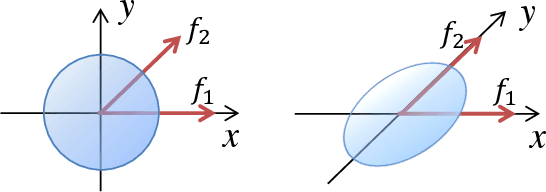

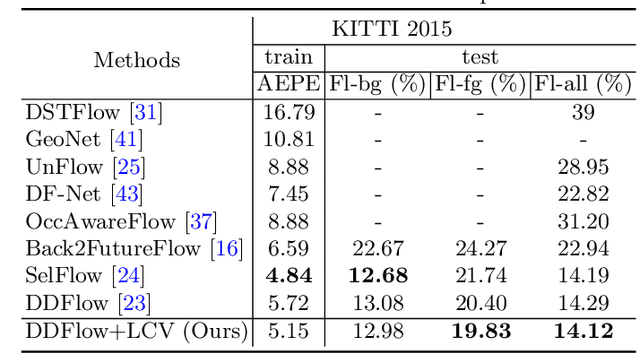
Cost volume is an essential component of recent deep models for optical flow estimation and is usually constructed by calculating the inner product between two feature vectors. However, the standard inner product in the commonly-used cost volume may limit the representation capacity of flow models because it neglects the correlation among different channel dimensions and weighs each dimension equally. To address this issue, we propose a learnable cost volume (LCV) using an elliptical inner product, which generalizes the standard inner product by a positive definite kernel matrix. To guarantee its positive definiteness, we perform spectral decomposition on the kernel matrix and re-parameterize it via the Cayley representation. The proposed LCV is a lightweight module and can be easily plugged into existing models to replace the vanilla cost volume. Experimental results show that the LCV module not only improves the accuracy of state-of-the-art models on standard benchmarks, but also promotes their robustness against illumination change, noises, and adversarial perturbations of the input signals.
Semi-Supervised Learning with Meta-Gradient
Jul 08, 2020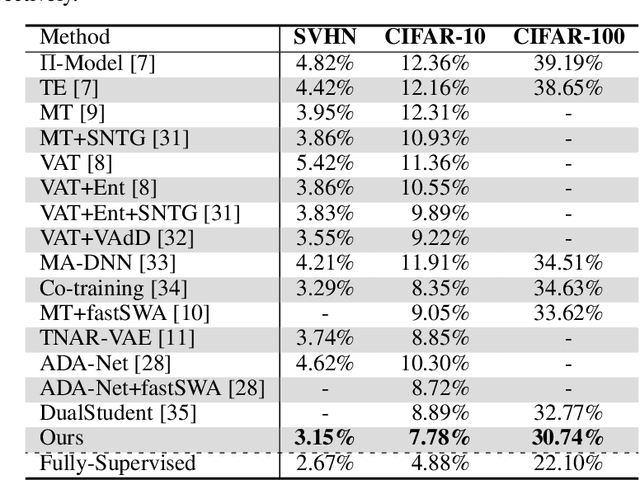
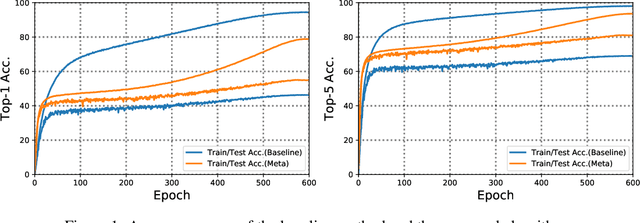
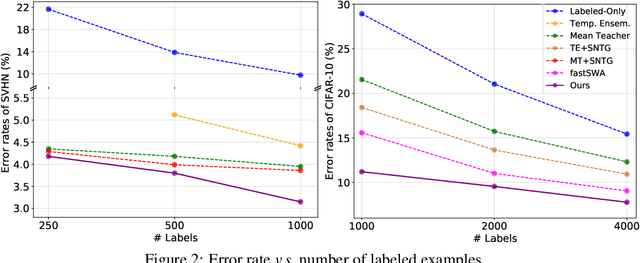
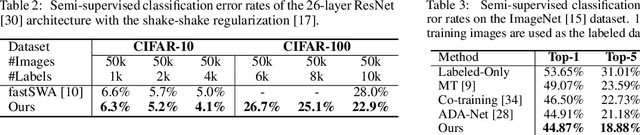
In this work, we propose a simple yet effective meta-learning algorithm in thesemi-supervised settings. We notice that existing consistency-based approachesmostly do not consider the essential role of the label information for consistencyregularization. To alleviate this issue, we bridge the relationship between theconsistency loss and label information by unfolding and differentiating throughone optimization step. Specifically, we exploit the pseudo labels of the unlabeledexamples which are guided by the meta-gradients of the labeled data loss so thatthe model can generalize well on the labeled examples. In addition, we introduce asimple first-order approximation to avoid computing higher-order derivatives andguarantee scalability. Extensive evaluations on the SVHN, CIFAR, and ImageNetdatasets demonstrate that the proposed algorithm performs favorably against thestate-of-the-art methods.
Model-Agnostic Structured Sparsification with Learnable Channel Shuffle
Feb 19, 2020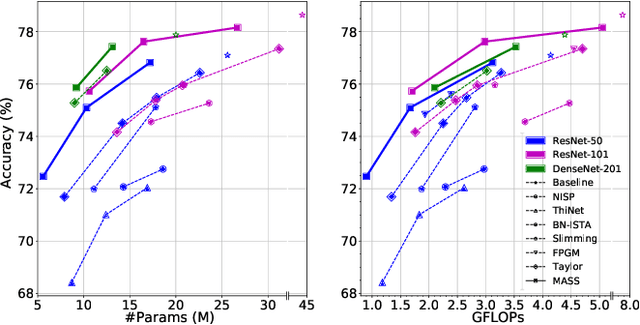
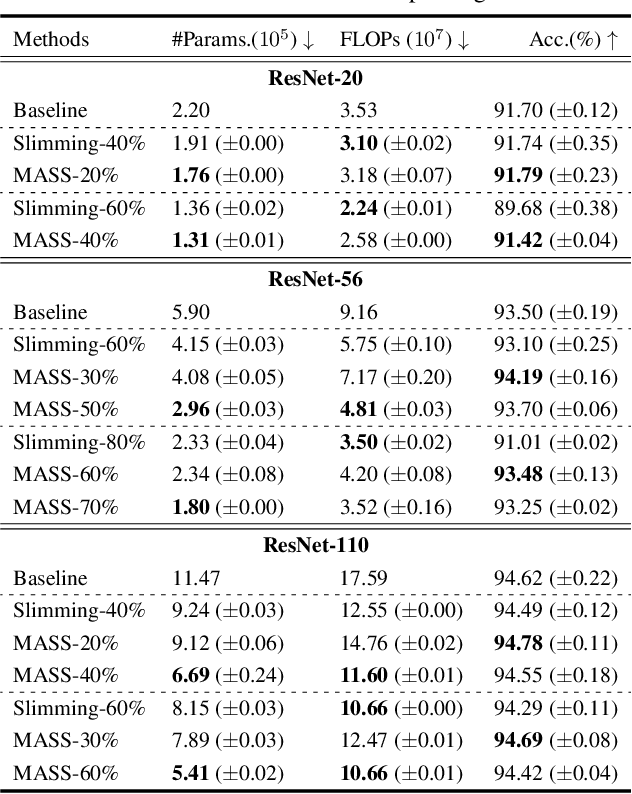
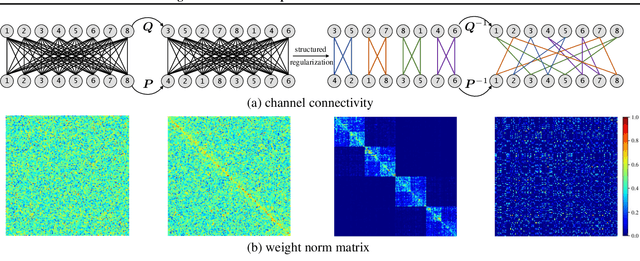
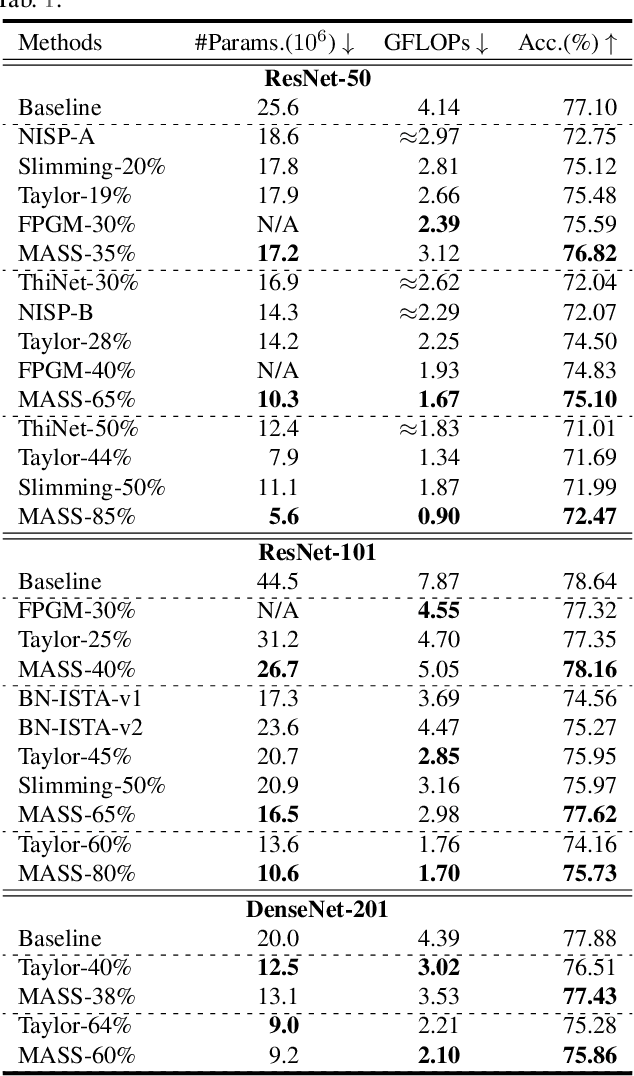
Recent advances in convolutional neural networks (CNNs) usually come with the expense of considerable computational overhead and memory footprint. Network compression aims to alleviate this issue by training compact models with comparable performance. However, existing compression techniques either entail dedicated expert design or compromise with a moderate performance drop. To this end, we propose a model-agnostic structured sparsification method for efficient network compression. The proposed method automatically induces structurally sparse representations of the convolutional weights, thereby facilitating the implementation of the compressed model with the highly-optimized group convolution. We further address the problem of inter-group communication with a learnable channel shuffle mechanism. The proposed approach is model-agnostic and highly compressible with a negligible performance drop. Extensive experimental results and analysis demonstrate that our approach performs favorably against the state-of-the-art network pruning methods. The code will be publicly available after the review process.
Adversarial Learning of Privacy-Preserving and Task-Oriented Representations
Nov 22, 2019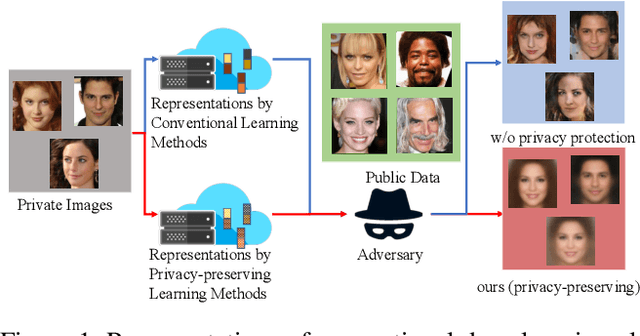
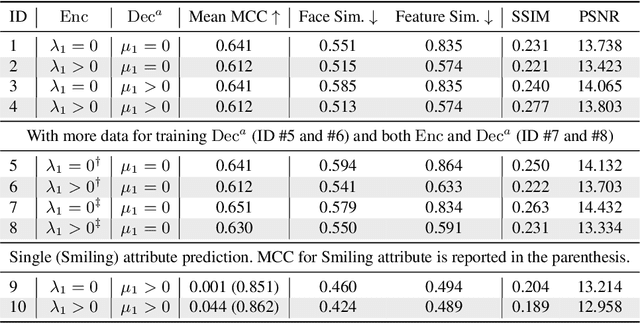
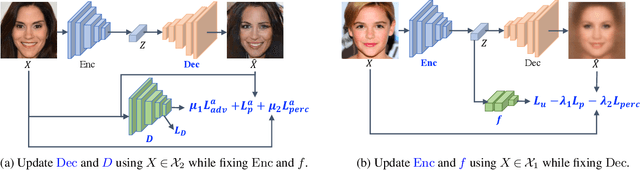
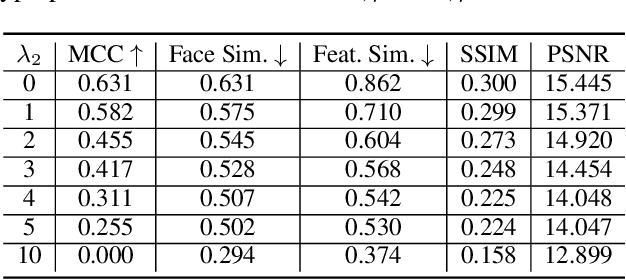
Data privacy has emerged as an important issue as data-driven deep learning has been an essential component of modern machine learning systems. For instance, there could be a potential privacy risk of machine learning systems via the model inversion attack, whose goal is to reconstruct the input data from the latent representation of deep networks. Our work aims at learning a privacy-preserving and task-oriented representation to defend against such model inversion attacks. Specifically, we propose an adversarial reconstruction learning framework that prevents the latent representations decoded into original input data. By simulating the expected behavior of adversary, our framework is realized by minimizing the negative pixel reconstruction loss or the negative feature reconstruction (i.e., perceptual distance) loss. We validate the proposed method on face attribute prediction, showing that our method allows protecting visual privacy with a small decrease in utility performance. In addition, we show the utility-privacy trade-off with different choices of hyperparameter for negative perceptual distance loss at training, allowing service providers to determine the right level of privacy-protection with a certain utility performance. Moreover, we provide an extensive study with different selections of features, tasks, and the data to further analyze their influence on privacy protection.
ELEGANT: Exchanging Latent Encodings with GAN for Transferring Multiple Face Attributes
Jul 25, 2018
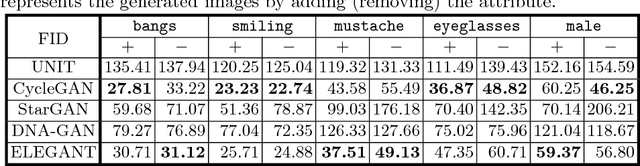


Recent studies on face attribute transfer have achieved great success. A lot of models are able to transfer face attributes with an input image. However, they suffer from three limitations: (1) incapability of generating image by exemplars; (2) being unable to transfer multiple face attributes simultaneously; (3) low quality of generated images, such as low-resolution or artifacts. To address these limitations, we propose a novel model which receives two images of opposite attributes as inputs. Our model can transfer exactly the same type of attributes from one image to another by exchanging certain part of their encodings. All the attributes are encoded in a disentangled manner in the latent space, which enables us to manipulate several attributes simultaneously. Besides, our model learns the residual images so as to facilitate training on higher resolution images. With the help of multi-scale discriminators for adversarial training, it can even generate high-quality images with finer details and less artifacts. We demonstrate the effectiveness of our model on overcoming the above three limitations by comparing with other methods on the CelebA face database. A pytorch implementation is available at https://github.com/Prinsphield/ELEGANT.
* Github: https://github.com/Prinsphield/ELEGANT
DNA-GAN: Learning Disentangled Representations from Multi-Attribute Images
Mar 28, 2018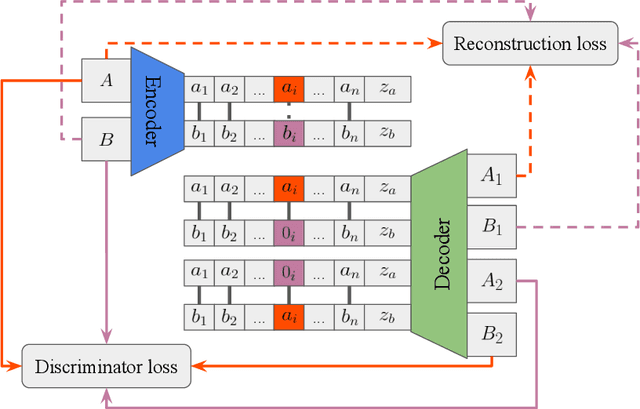



Disentangling factors of variation has become a very challenging problem on representation learning. Existing algorithms suffer from many limitations, such as unpredictable disentangling factors, poor quality of generated images from encodings, lack of identity information, etc. In this paper, we propose a supervised learning model called DNA-GAN which tries to disentangle different factors or attributes of images. The latent representations of images are DNA-like, in which each individual piece (of the encoding) represents an independent factor of the variation. By annihilating the recessive piece and swapping a certain piece of one latent representation with that of the other one, we obtain two different representations which could be decoded into two kinds of images with the existence of the corresponding attribute being changed. In order to obtain realistic images and also disentangled representations, we further introduce the discriminator for adversarial training. Experiments on Multi-PIE and CelebA datasets finally demonstrate that our proposed method is effective for factors disentangling and even overcome certain limitations of the existing methods.