 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHeterogeneous Social Event Detection via Hyperbolic Graph Representations
Feb 20, 2023



Social events reflect the dynamics of society and, here, natural disasters and emergencies receive significant attention. The timely detection of these events can provide organisations and individuals with valuable information to reduce or avoid losses. However, due to the complex heterogeneities of the content and structure of social media, existing models can only learn limited information; large amounts of semantic and structural information are ignored. In addition, due to high labour costs, it is rare for social media datasets to include high-quality labels, which also makes it challenging for models to learn information from social media. In this study, we propose two hyperbolic graph representation-based methods for detecting social events from heterogeneous social media environments. For cases where a dataset has labels, we designed a Hyperbolic Social Event Detection (HSED) model that converts complex social information into a unified social message graph. This model addresses the heterogeneity of social media, and, with this graph, the information in social media can be used to capture structural information based on the properties of hyperbolic space. For cases where the dataset is unlabelled, we designed an Unsupervised Hyperbolic Social Event Detection (UHSED). This model is based on the HSED model but includes graph contrastive learning to make it work in unlabelled scenarios. Extensive experiments demonstrate the superiority of the proposed approaches.
A Comprehensive Survey on Pretrained Foundation Models: A History from BERT to ChatGPT
Feb 18, 2023The Pretrained Foundation Models (PFMs) are regarded as the foundation for various downstream tasks with different data modalities. A pretrained foundation model, such as BERT, GPT-3, MAE, DALLE-E, and ChatGPT, is trained on large-scale data which provides a reasonable parameter initialization for a wide range of downstream applications. The idea of pretraining behind PFMs plays an important role in the application of large models. Different from previous methods that apply convolution and recurrent modules for feature extractions, the generative pre-training (GPT) method applies Transformer as the feature extractor and is trained on large datasets with an autoregressive paradigm. Similarly, the BERT apples transformers to train on large datasets as a contextual language model. Recently, the ChatGPT shows promising success on large language models, which applies an autoregressive language model with zero shot or few show prompting. With the extraordinary success of PFMs, AI has made waves in a variety of fields over the past few years. Considerable methods, datasets, and evaluation metrics have been proposed in the literature, the need is raising for an updated survey. This study provides a comprehensive review of recent research advancements, current and future challenges, and opportunities for PFMs in text, image, graph, as well as other data modalities. We first review the basic components and existing pretraining in natural language processing, computer vision, and graph learning. We then discuss other advanced PFMs for other data modalities and unified PFMs considering the data quality and quantity. Besides, we discuss relevant research about the fundamentals of the PFM, including model efficiency and compression, security, and privacy. Finally, we lay out key implications, future research directions, challenges, and open problems.
A Survey on Graph Neural Networks for Graph Summarization
Feb 13, 2023



As large-scale graphs become more widespread today, it exposes computational challenges to extract, process, and interpret large graph data. It is therefore natural to search for ways to summarize the original graph while maintaining its key characteristics. In this survey, we outline the most current progress of deep learning on graphs for graph summarization explicitly concentrating on Graph Neural Networks (GNNs) methods. We structure the paper into four categories, including graph recurrent networks, graph convolutional networks, graph autoencoders, and graph attention networks. We also discuss a new booming line of research which is elaborating on using graph reinforcement learning for evaluating and improving the quality of graph summaries. Finally, we conclude this survey and discuss a number of open research challenges that would motivate further study in this area.
A Comprehensive Survey on Automatic Knowledge Graph Construction
Feb 10, 2023Automatic knowledge graph construction aims to manufacture structured human knowledge. To this end, much effort has historically been spent extracting informative fact patterns from different data sources. However, more recently, research interest has shifted to acquiring conceptualized structured knowledge beyond informative data. In addition, researchers have also been exploring new ways of handling sophisticated construction tasks in diversified scenarios. Thus, there is a demand for a systematic review of paradigms to organize knowledge structures beyond data-level mentions. To meet this demand, we comprehensively survey more than 300 methods to summarize the latest developments in knowledge graph construction. A knowledge graph is built in three steps: knowledge acquisition, knowledge refinement, and knowledge evolution. The processes of knowledge acquisition are reviewed in detail, including obtaining entities with fine-grained types and their conceptual linkages to knowledge graphs; resolving coreferences; and extracting entity relationships in complex scenarios. The survey covers models for knowledge refinement, including knowledge graph completion, and knowledge fusion. Methods to handle knowledge evolution are also systematically presented, including condition knowledge acquisition, condition knowledge graph completion, and knowledge dynamic. We present the paradigms to compare the distinction among these methods along the axis of the data environment, motivation, and architecture. Additionally, we also provide briefs on accessible resources that can help readers to develop practical knowledge graph systems. The survey concludes with discussions on the challenges and possible directions for future exploration.
Unbiased and Efficient Self-Supervised Incremental Contrastive Learning
Jan 28, 2023Contrastive Learning (CL) has been proved to be a powerful self-supervised approach for a wide range of domains, including computer vision and graph representation learning. However, the incremental learning issue of CL has rarely been studied, which brings the limitation in applying it to real-world applications. Contrastive learning identifies the samples with the negative ones from the noise distribution that changes in the incremental scenarios. Therefore, only fitting the change of data without noise distribution causes bias, and directly retraining results in low efficiency. To bridge this research gap, we propose a self-supervised Incremental Contrastive Learning (ICL) framework consisting of (i) a novel Incremental InfoNCE (NCE-II) loss function by estimating the change of noise distribution for old data to guarantee no bias with respect to the retraining, (ii) a meta-optimization with deep reinforced Learning Rate Learning (LRL) mechanism which can adaptively learn the learning rate according to the status of the training processes and achieve fast convergence which is critical for incremental learning. Theoretically, the proposed ICL is equivalent to retraining, which is based on solid mathematical derivation. In practice, extensive experiments in different domains demonstrate that, without retraining a new model, ICL achieves up to 16.7x training speedup and 16.8x faster convergence with competitive results.
A Comprehensive Survey of Graph-level Learning
Jan 14, 2023



Graphs have a superior ability to represent relational data, like chemical compounds, proteins, and social networks. Hence, graph-level learning, which takes a set of graphs as input, has been applied to many tasks including comparison, regression, classification, and more. Traditional approaches to learning a set of graphs tend to rely on hand-crafted features, such as substructures. But while these methods benefit from good interpretability, they often suffer from computational bottlenecks as they cannot skirt the graph isomorphism problem. Conversely, deep learning has helped graph-level learning adapt to the growing scale of graphs by extracting features automatically and decoding graphs into low-dimensional representations. As a result, these deep graph learning methods have been responsible for many successes. Yet, there is no comprehensive survey that reviews graph-level learning starting with traditional learning and moving through to the deep learning approaches. This article fills this gap and frames the representative algorithms into a systematic taxonomy covering traditional learning, graph-level deep neural networks, graph-level graph neural networks, and graph pooling. To ensure a thoroughly comprehensive survey, the evolutions, interactions, and communications between methods from four different branches of development are also examined. This is followed by a brief review of the benchmark data sets, evaluation metrics, and common downstream applications. The survey concludes with 13 future directions of necessary research that will help to overcome the challenges facing this booming field.
Mining User-aware Multi-relations for Fake News Detection in Large Scale Online Social Networks
Jan 04, 2023



Users' involvement in creating and propagating news is a vital aspect of fake news detection in online social networks. Intuitively, credible users are more likely to share trustworthy news, while untrusted users have a higher probability of spreading untrustworthy news. In this paper, we construct a dual-layer graph (i.e., the news layer and the user layer) to extract multiple relations of news and users in social networks to derive rich information for detecting fake news. Based on the dual-layer graph, we propose a fake news detection model named Us-DeFake. It learns the propagation features of news in the news layer and the interaction features of users in the user layer. Through the inter-layer in the graph, Us-DeFake fuses the user signals that contain credibility information into the news features, to provide distinctive user-aware embeddings of news for fake news detection. The training process conducts on multiple dual-layer subgraphs obtained by a graph sampler to scale Us-DeFake in large scale social networks. Extensive experiments on real-world datasets illustrate the superiority of Us-DeFake which outperforms all baselines, and the users' credibility signals learned by interaction relation can notably improve the performance of our model.
Brain Tumor Synthetic Data Generation with Adaptive StyleGANs
Dec 04, 2022Generative models have been very successful over the years and have received significant attention for synthetic data generation. As deep learning models are getting more and more complex, they require large amounts of data to perform accurately. In medical image analysis, such generative models play a crucial role as the available data is limited due to challenges related to data privacy, lack of data diversity, or uneven data distributions. In this paper, we present a method to generate brain tumor MRI images using generative adversarial networks. We have utilized StyleGAN2 with ADA methodology to generate high-quality brain MRI with tumors while using a significantly smaller amount of training data when compared to the existing approaches. We use three pre-trained models for transfer learning. Results demonstrate that the proposed method can learn the distributions of brain tumors. Furthermore, the model can generate high-quality synthetic brain MRI with a tumor that can limit the small sample size issues. The approach can addresses the limited data availability by generating realistic-looking brain MRI with tumors. The code is available at: ~\url{https://github.com/rizwanqureshi123/Brain-Tumor-Synthetic-Data}.
DAGAD: Data Augmentation for Graph Anomaly Detection
Oct 18, 2022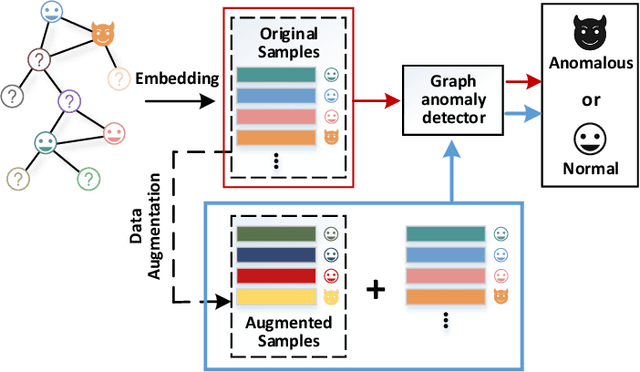
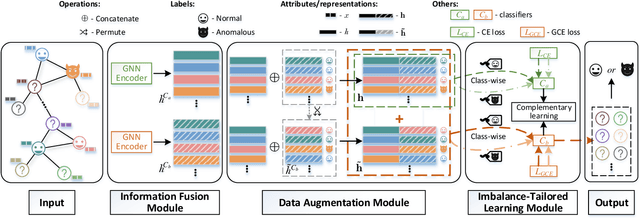
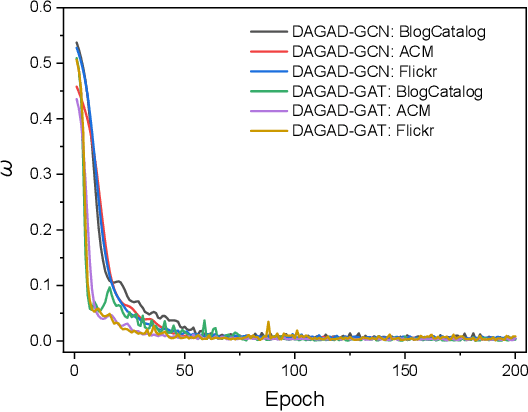
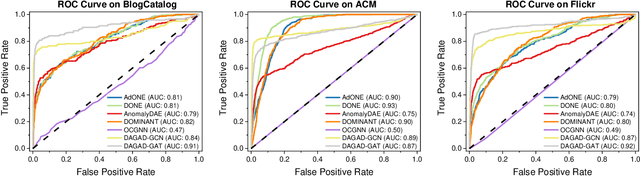
Graph anomaly detection in this paper aims to distinguish abnormal nodes that behave differently from the benign ones accounting for the majority of graph-structured instances. Receiving increasing attention from both academia and industry, yet existing research on this task still suffers from two critical issues when learning informative anomalous behavior from graph data. For one thing, anomalies are usually hard to capture because of their subtle abnormal behavior and the shortage of background knowledge about them, which causes severe anomalous sample scarcity. Meanwhile, the overwhelming majority of objects in real-world graphs are normal, bringing the class imbalance problem as well. To bridge the gaps, this paper devises a novel Data Augmentation-based Graph Anomaly Detection (DAGAD) framework for attributed graphs, equipped with three specially designed modules: 1) an information fusion module employing graph neural network encoders to learn representations, 2) a graph data augmentation module that fertilizes the training set with generated samples, and 3) an imbalance-tailored learning module to discriminate the distributions of the minority (anomalous) and majority (normal) classes. A series of experiments on three datasets prove that DAGAD outperforms ten state-of-the-art baseline detectors concerning various mostly-used metrics, together with an extensive ablation study validating the strength of our proposed modules.
Heterogeneous Graph Neural Network for Privacy-Preserving Recommendation
Oct 09, 2022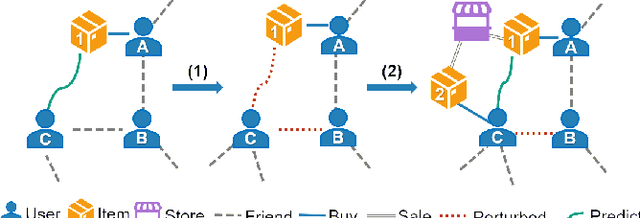
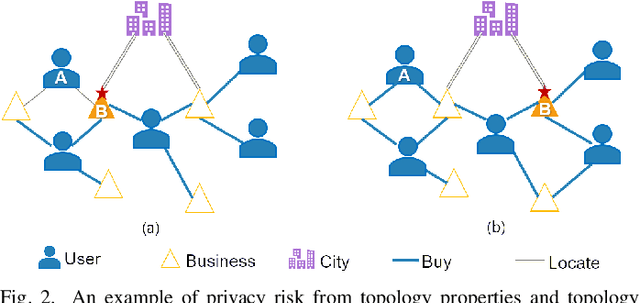
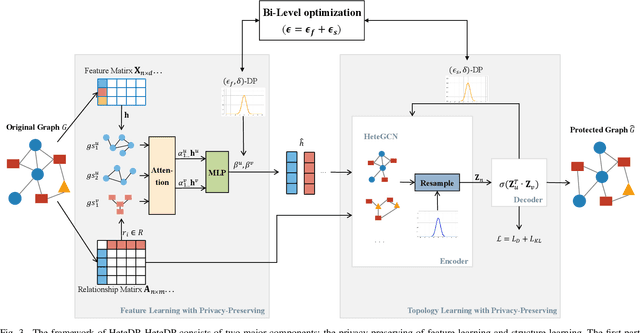
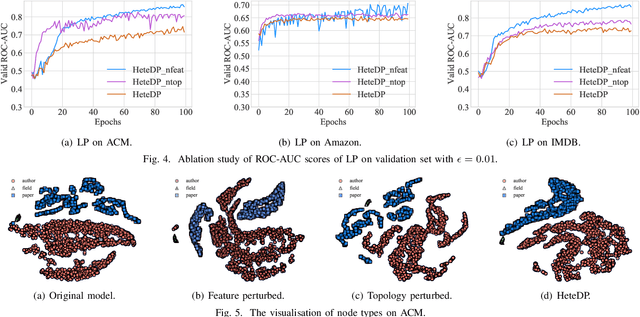
Social networks are considered to be heterogeneous graph neural networks (HGNNs) with deep learning technological advances. HGNNs, compared to homogeneous data, absorb various aspects of information about individuals in the training stage. That means more information has been covered in the learning result, especially sensitive information. However, the privacy-preserving methods on homogeneous graphs only preserve the same type of node attributes or relationships, which cannot effectively work on heterogeneous graphs due to the complexity. To address this issue, we propose a novel heterogeneous graph neural network privacy-preserving method based on a differential privacy mechanism named HeteDP, which provides a double guarantee on graph features and topology. In particular, we first define a new attack scheme to reveal privacy leakage in the heterogeneous graphs. Specifically, we design a two-stage pipeline framework, which includes the privacy-preserving feature encoder and the heterogeneous link reconstructor with gradients perturbation based on differential privacy to tolerate data diversity and against the attack. To better control the noise and promote model performance, we utilize a bi-level optimization pattern to allocate a suitable privacy budget for the above two modules. Our experiments on four public benchmarks show that the HeteDP method is equipped to resist heterogeneous graph privacy leakage with admirable model generalization.