 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffCloud: Real-to-Sim from Point Clouds with Differentiable Simulation and Rendering of Deformable Objects
Apr 07, 2022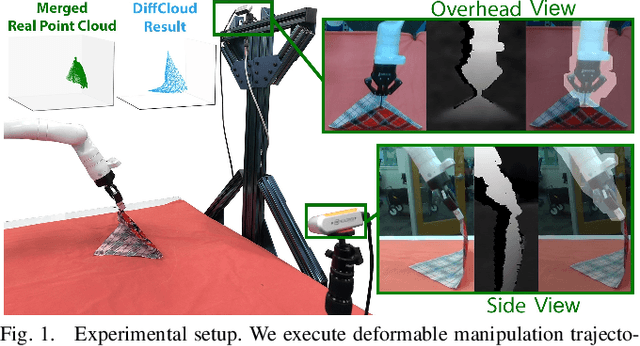

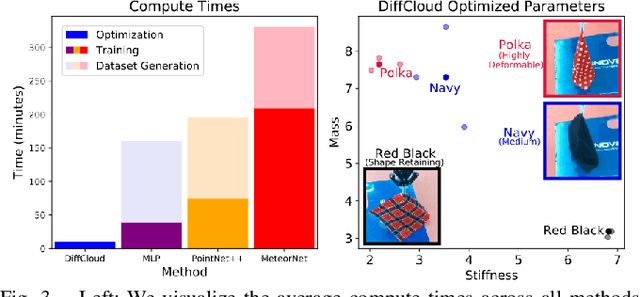
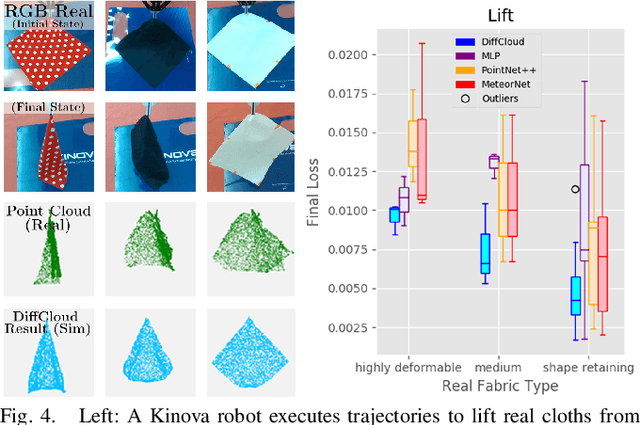
Research in manipulation of deformable objects is typically conducted on a limited range of scenarios, because handling each scenario on hardware takes significant effort. Realistic simulators with support for various types of deformations and interactions have the potential to speed up experimentation with novel tasks and algorithms. However, for highly deformable objects it is challenging to align the output of a simulator with the behavior of real objects. Manual tuning is not intuitive, hence automated methods are needed. We view this alignment problem as a joint perception-inference challenge and demonstrate how to use recent neural network architectures to successfully perform simulation parameter inference from real point clouds. We analyze the performance of various architectures, comparing their data and training requirements. Furthermore, we propose to leverage differentiable point cloud sampling and differentiable simulation to significantly reduce the time to achieve the alignment. We employ an efficient way to propagate gradients from point clouds to simulated meshes and further through to the physical simulation parameters, such as mass and stiffness. Experiments with highly deformable objects show that our method can achieve comparable or better alignment with real object behavior, while reducing the time needed to achieve this by more than an order of magnitude. Videos and supplementary material are available at https://tinyurl.com/diffcloud.
ObjectFolder 2.0: A Multisensory Object Dataset for Sim2Real Transfer
Apr 05, 2022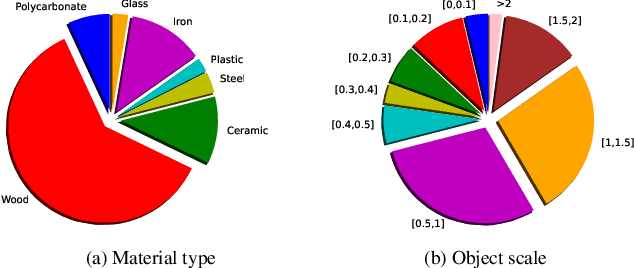
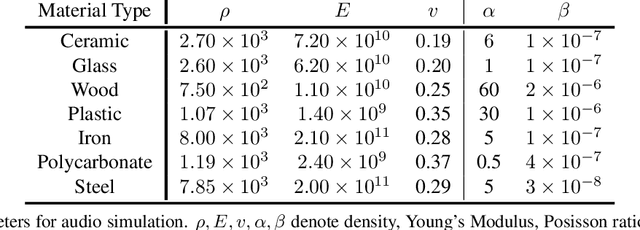


Objects play a crucial role in our everyday activities. Though multisensory object-centric learning has shown great potential lately, the modeling of objects in prior work is rather unrealistic. ObjectFolder 1.0 is a recent dataset that introduces 100 virtualized objects with visual, acoustic, and tactile sensory data. However, the dataset is small in scale and the multisensory data is of limited quality, hampering generalization to real-world scenarios. We present ObjectFolder 2.0, a large-scale, multisensory dataset of common household objects in the form of implicit neural representations that significantly enhances ObjectFolder 1.0 in three aspects. First, our dataset is 10 times larger in the amount of objects and orders of magnitude faster in rendering time. Second, we significantly improve the multisensory rendering quality for all three modalities. Third, we show that models learned from virtual objects in our dataset successfully transfer to their real-world counterparts in three challenging tasks: object scale estimation, contact localization, and shape reconstruction. ObjectFolder 2.0 offers a new path and testbed for multisensory learning in computer vision and robotics. The dataset is available at https://github.com/rhgao/ObjectFolder.
Symbolic State Estimation with Predicates for Contact-Rich Manipulation Tasks
Mar 04, 2022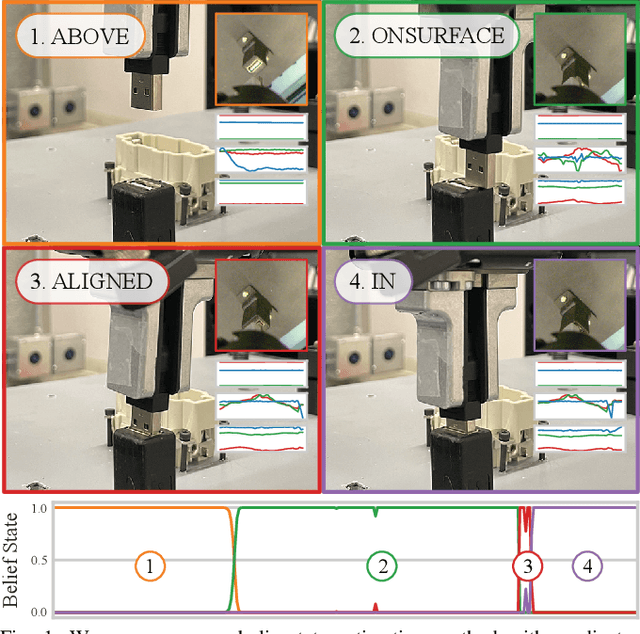

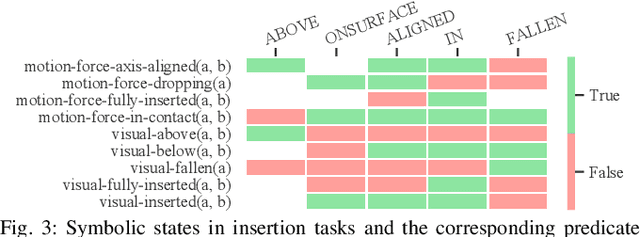
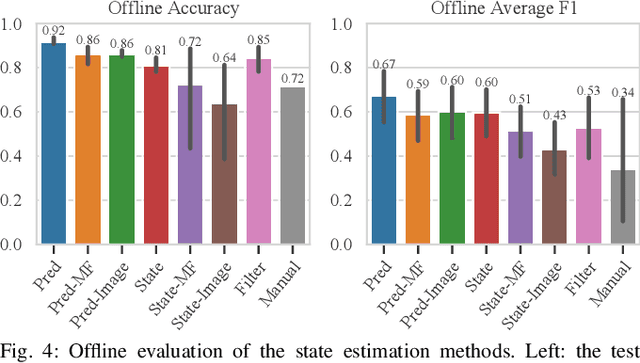
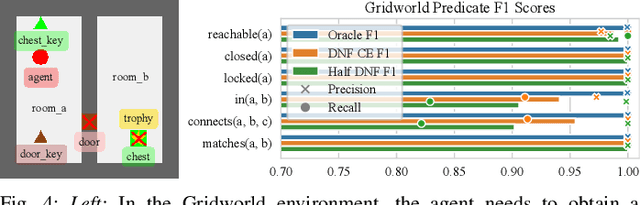
Manipulation tasks often require a robot to adjust its sensorimotor skills based on the state it finds itself in. Taking peg-in-hole as an example: once the peg is aligned with the hole, the robot should push the peg downwards. While high level execution frameworks such as state machines and behavior trees are commonly used to formalize such decision-making problems, these frameworks require a mechanism to detect the high-level symbolic state. Handcrafting heuristics to identify symbolic states can be brittle, and using data-driven methods can produce noisy predictions, particularly when working with limited datasets, as is common in real-world robotic scenarios. This paper proposes a Bayesian state estimation method to predict symbolic states with predicate classifiers. This method requires little training data and allows fusing noisy observations from multiple sensor modalities. We evaluate our framework on a set of real-world peg-in-hole and connector-socket insertion tasks, demonstrating its ability to classify symbolic states and to generalize to unseen tasks, outperforming baseline methods. We also demonstrate the ability of our method to improve the robustness of manipulation policies on a real robot.
A Bayesian Treatment of Real-to-Sim for Deformable Object Manipulation
Dec 09, 2021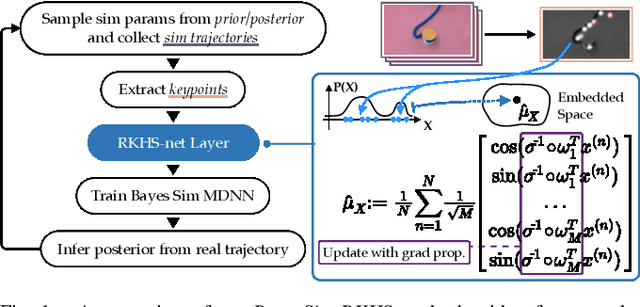


Deformable object manipulation remains a challenging task in robotics research. Conventional techniques for parameter inference and state estimation typically rely on a precise definition of the state space and its dynamics. While this is appropriate for rigid objects and robot states, it is challenging to define the state space of a deformable object and how it evolves in time. In this work, we pose the problem of inferring physical parameters of deformable objects as a probabilistic inference task defined with a simulator. We propose a novel methodology for extracting state information from image sequences via a technique to represent the state of a deformable object as a distribution embedding. This allows to incorporate noisy state observations directly into modern Bayesian simulation-based inference tools in a principled manner. Our experiments confirm that we can estimate posterior distributions of physical properties, such as elasticity, friction and scale of highly deformable objects, such as cloth and ropes. Overall, our method addresses the real-to-sim problem probabilistically and helps to better represent the evolution of the state of deformable objects.
From Machine Learning to Robotics: Challenges and Opportunities for Embodied Intelligence
Oct 28, 2021
Machine learning has long since become a keystone technology, accelerating science and applications in a broad range of domains. Consequently, the notion of applying learning methods to a particular problem set has become an established and valuable modus operandi to advance a particular field. In this article we argue that such an approach does not straightforwardly extended to robotics -- or to embodied intelligence more generally: systems which engage in a purposeful exchange of energy and information with a physical environment. In particular, the purview of embodied intelligent agents extends significantly beyond the typical considerations of main-stream machine learning approaches, which typically (i) do not consider operation under conditions significantly different from those encountered during training; (ii) do not consider the often substantial, long-lasting and potentially safety-critical nature of interactions during learning and deployment; (iii) do not require ready adaptation to novel tasks while at the same time (iv) effectively and efficiently curating and extending their models of the world through targeted and deliberate actions. In reality, therefore, these limitations result in learning-based systems which suffer from many of the same operational shortcomings as more traditional, engineering-based approaches when deployed on a robot outside a well defined, and often narrow operating envelope. Contrary to viewing embodied intelligence as another application domain for machine learning, here we argue that it is in fact a key driver for the advancement of machine learning technology. In this article our goal is to highlight challenges and opportunities that are specific to embodied intelligence and to propose research directions which may significantly advance the state-of-the-art in robot learning.
Vision-Only Robot Navigation in a Neural Radiance World
Oct 01, 2021
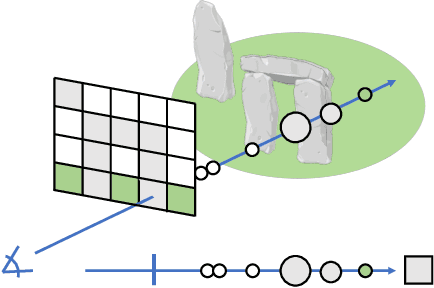
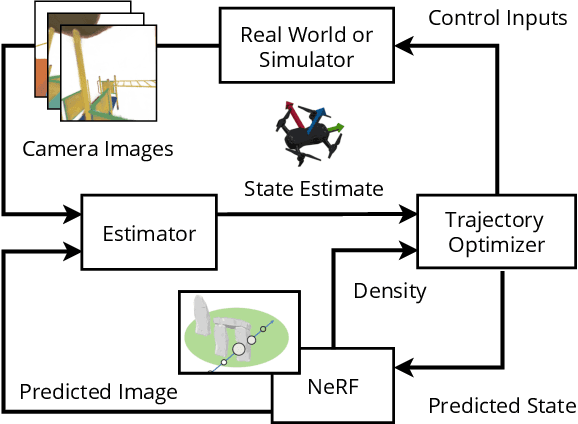
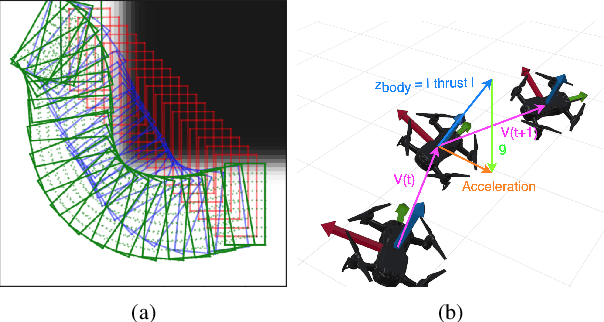
Neural Radiance Fields (NeRFs) have recently emerged as a powerful paradigm for the representation of natural, complex 3D scenes. NeRFs represent continuous volumetric density and RGB values in a neural network, and generate photo-realistic images from unseen camera viewpoints through ray tracing. We propose an algorithm for navigating a robot through a 3D environment represented as a NeRF using only an on-board RGB camera for localization. We assume the NeRF for the scene has been pre-trained offline, and the robot's objective is to navigate through unoccupied space in the NeRF to reach a goal pose. We introduce a trajectory optimization algorithm that avoids collisions with high-density regions in the NeRF based on a discrete time version of differential flatness that is amenable to constraining the robot's full pose and control inputs. We also introduce an optimization based filtering method to estimate 6DoF pose and velocities for the robot in the NeRF given only an onboard RGB camera. We combine the trajectory planner with the pose filter in an online replanning loop to give a vision-based robot navigation pipeline. We present simulation results with a quadrotor robot navigating through a jungle gym environment, the inside of a church, and Stonehenge using only an RGB camera. We also demonstrate an omnidirectional ground robot navigating through the church, requiring it to reorient to fit through the narrow gap. Videos of this work can be found at https://mikh3x4.github.io/nerf-navigation/ .
Grounding Predicates through Actions
Sep 29, 2021
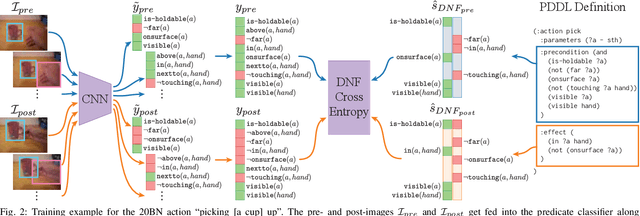

Symbols representing abstract states such as "dish in dishwasher" or "cup on table" allow robots to reason over long horizons by hiding details unnecessary for high level planning. Current methods for learning to identify symbolic states in visual data require large amounts of labeled training data, but manually annotating such datasets is prohibitively expensive due to the combinatorial number of predicates in images. We propose a novel method for automatically labeling symbolic states in large-scale video activity datasets by exploiting known pre- and post-conditions of actions. This automatic labeling scheme only requires weak supervision in the form of an action label that describes which action is demonstrated in each video. We apply our framework to an existing large-scale human activity dataset. We train predicate classifiers to identify symbolic relationships between objects when prompted with object bounding boxes and achieve 0.93 test accuracy. We further demonstrate the ability of these predicate classifiers trained on human data to be applied to robot environments in a real-world task planning domain.
TrajectoTree: Trajectory Optimization Meets Tree Search for Planning Multi-contact Dexterous Manipulation
Sep 28, 2021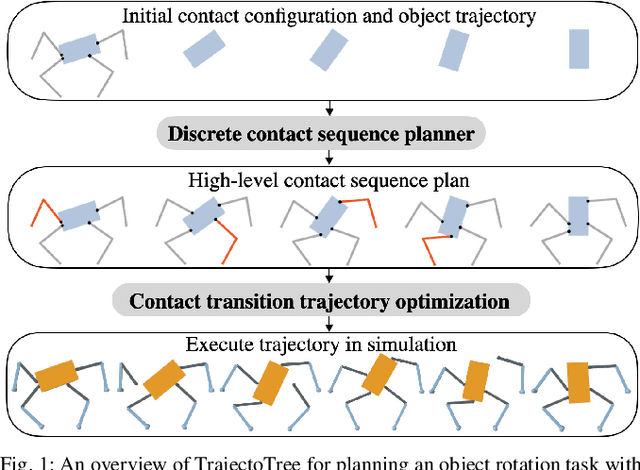
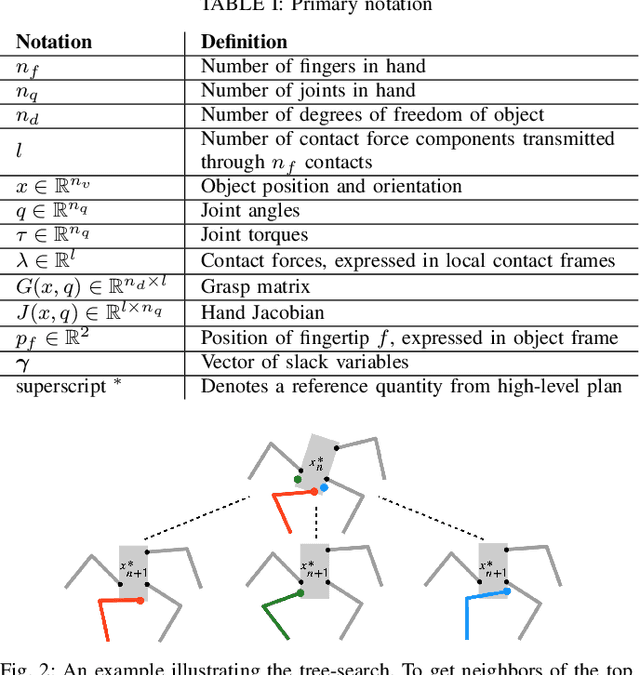
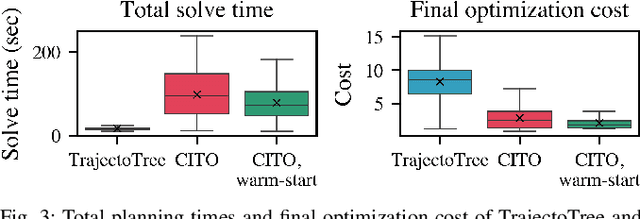

Dexterous manipulation tasks often require contact switching, where fingers make and break contact with the object. We propose a method that plans trajectories for dexterous manipulation tasks involving contact switching using contact-implicit trajectory optimization (CITO) augmented with a high-level discrete contact sequence planner. We first use the high-level planner to find a sequence of finger contact switches given a desired object trajectory. With this contact sequence plan, we impose additional constraints in the CITO problem. We show that our method finds trajectories approximately 7 times faster than a general CITO baseline for a four-finger planar manipulation scenario. Furthermore, when executing the planned trajectories in a full dynamics simulator, we are able to more closely track the object pose trajectories planned by our method than those planned by the baselines.
Learning Periodic Tasks from Human Demonstrations
Sep 28, 2021
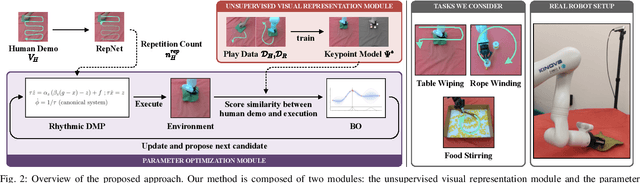
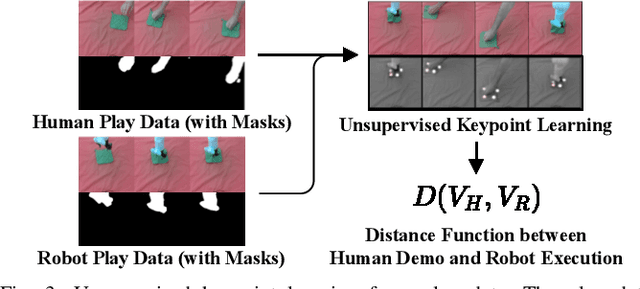
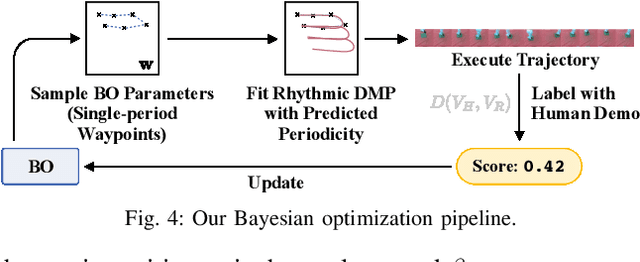
We develop a method for learning periodic tasks from visual demonstrations. The core idea is to leverage periodicity in the policy structure to model periodic aspects of the tasks. We use active learning to optimize parameters of rhythmic dynamic movement primitives (rDMPs) and propose an objective to maximize the similarity between the motion of objects manipulated by the robot and the desired motion in human video demonstrations. We consider tasks with deformable objects and granular matter whose state is challenging to represent and track: wiping surfaces with a cloth, winding cables/wires, stirring granular matter with a spoon. Our method does not require tracking markers or manual annotations. The initial training data consists of 10-minute videos of random unpaired interactions with objects by the robot and human. We use these for unsupervised learning of a keypoint model to get task-agnostic visual correspondences. Then, we use Bayesian optimization to optimize rDMPs from a single human video demonstration within few robot trials. We present simulation and hardware experiments to validate our approach.
On the Opportunities and Risks of Foundation Models
Aug 18, 2021



AI is undergoing a paradigm shift with the rise of models (e.g., BERT, DALL-E, GPT-3) that are trained on broad data at scale and are adaptable to a wide range of downstream tasks. We call these models foundation models to underscore their critically central yet incomplete character. This report provides a thorough account of the opportunities and risks of foundation models, ranging from their capabilities (e.g., language, vision, robotics, reasoning, human interaction) and technical principles(e.g., model architectures, training procedures, data, systems, security, evaluation, theory) to their applications (e.g., law, healthcare, education) and societal impact (e.g., inequity, misuse, economic and environmental impact, legal and ethical considerations). Though foundation models are based on standard deep learning and transfer learning, their scale results in new emergent capabilities,and their effectiveness across so many tasks incentivizes homogenization. Homogenization provides powerful leverage but demands caution, as the defects of the foundation model are inherited by all the adapted models downstream. Despite the impending widespread deployment of foundation models, we currently lack a clear understanding of how they work, when they fail, and what they are even capable of due to their emergent properties. To tackle these questions, we believe much of the critical research on foundation models will require deep interdisciplinary collaboration commensurate with their fundamentally sociotechnical nature.