 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeta Spatio-Temporal Debiasing for Video Scene Graph Generation
Jul 30, 2022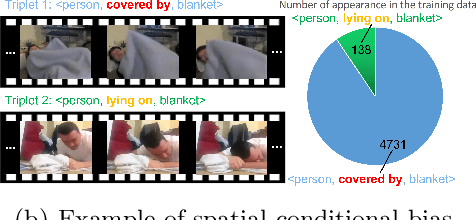
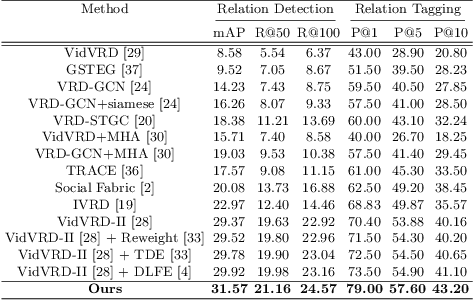
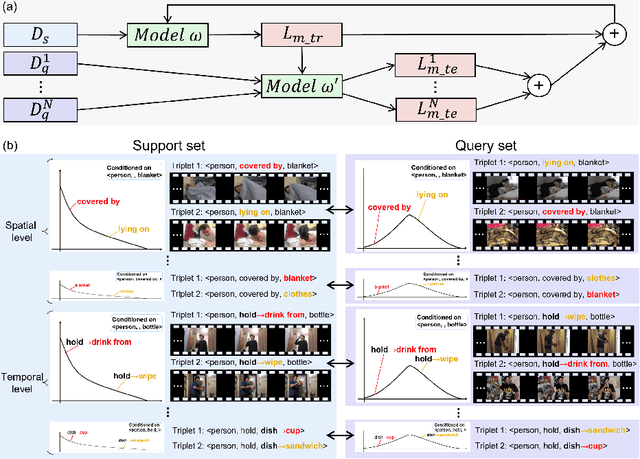

Video scene graph generation (VidSGG) aims to parse the video content into scene graphs, which involves modeling the spatio-temporal contextual information in the video. However, due to the long-tailed training data in datasets, the generalization performance of existing VidSGG models can be affected by the spatio-temporal conditional bias problem. In this work, from the perspective of meta-learning, we propose a novel Meta Video Scene Graph Generation (MVSGG) framework to address such a bias problem. Specifically, to handle various types of spatio-temporal conditional biases, our framework first constructs a support set and a group of query sets from the training data, where the data distribution of each query set is different from that of the support set w.r.t. a type of conditional bias. Then, by performing a novel meta training and testing process to optimize the model to obtain good testing performance on these query sets after training on the support set, our framework can effectively guide the model to learn to well generalize against biases. Extensive experiments demonstrate the efficacy of our proposed framework.
Unified Pretraining Framework for Document Understanding
Apr 28, 2022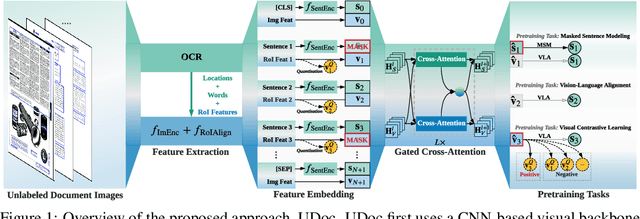
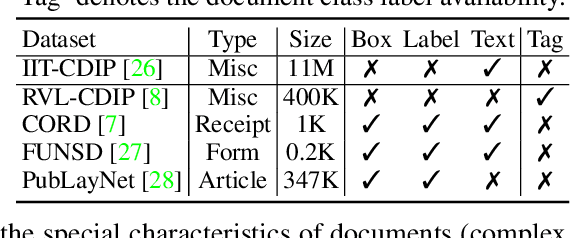
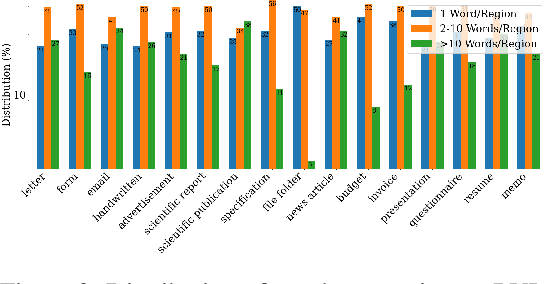
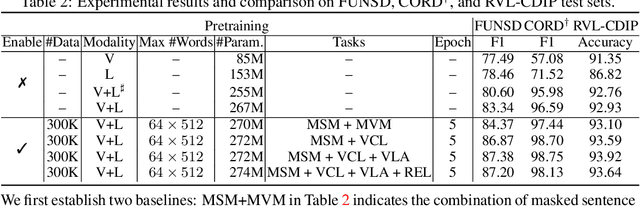
Document intelligence automates the extraction of information from documents and supports many business applications. Recent self-supervised learning methods on large-scale unlabeled document datasets have opened up promising directions towards reducing annotation efforts by training models with self-supervised objectives. However, most of the existing document pretraining methods are still language-dominated. We present UDoc, a new unified pretraining framework for document understanding. UDoc is designed to support most document understanding tasks, extending the Transformer to take multimodal embeddings as input. Each input element is composed of words and visual features from a semantic region of the input document image. An important feature of UDoc is that it learns a generic representation by making use of three self-supervised losses, encouraging the representation to model sentences, learn similarities, and align modalities. Extensive empirical analysis demonstrates that the pretraining procedure learns better joint representations and leads to improvements in downstream tasks.
GALA: Toward Geometry-and-Lighting-Aware Object Search for Compositing
Mar 31, 2022
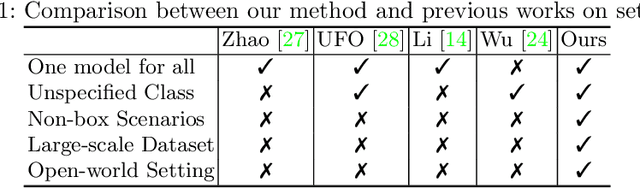

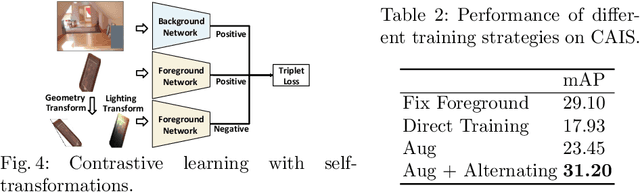
Compositing-aware object search aims to find the most compatible objects for compositing given a background image and a query bounding box. Previous works focus on learning compatibility between the foreground object and background, but fail to learn other important factors from large-scale data, i.e. geometry and lighting. To move a step further, this paper proposes GALA (Geometry-and-Lighting-Aware), a generic foreground object search method with discriminative modeling on geometry and lighting compatibility for open-world image compositing. Remarkably, it achieves state-of-the-art results on the CAIS dataset and generalizes well on large-scale open-world datasets, i.e. Pixabay and Open Images. In addition, our method can effectively handle non-box scenarios, where users only provide background images without any input bounding box. A web demo (see supplementary materials) is built to showcase applications of the proposed method for compositing-aware search and automatic location/scale prediction for the foreground object.
High Quality Segmentation for Ultra High-resolution Images
Dec 26, 2021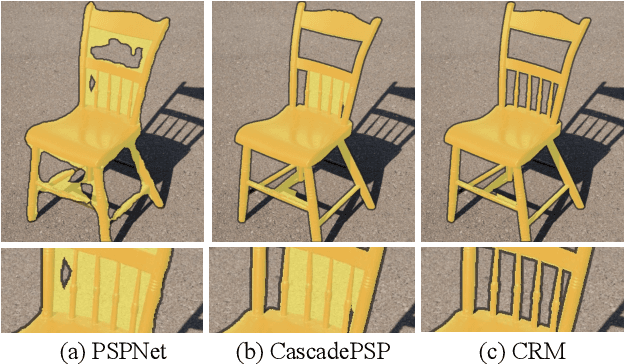
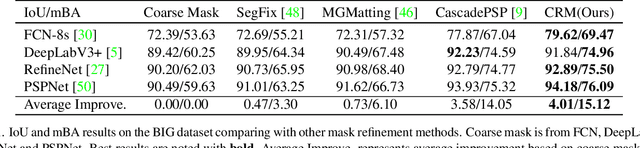
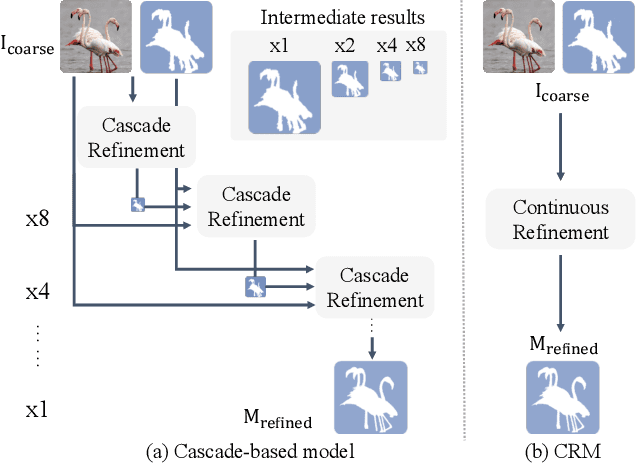
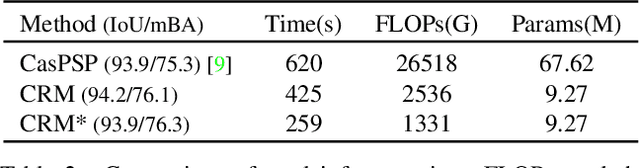
To segment 4K or 6K ultra high-resolution images needs extra computation consideration in image segmentation. Common strategies, such as down-sampling, patch cropping, and cascade model, cannot address well the balance issue between accuracy and computation cost. Motivated by the fact that humans distinguish among objects continuously from coarse to precise levels, we propose the Continuous Refinement Model~(CRM) for the ultra high-resolution segmentation refinement task. CRM continuously aligns the feature map with the refinement target and aggregates features to reconstruct these images' details. Besides, our CRM shows its significant generalization ability to fill the resolution gap between low-resolution training images and ultra high-resolution testing ones. We present quantitative performance evaluation and visualization to show that our proposed method is fast and effective on image segmentation refinement. Code will be released at https://github.com/dvlab-research/Entity.
CaSP: Class-agnostic Semi-Supervised Pretraining for Detection and Segmentation
Dec 09, 2021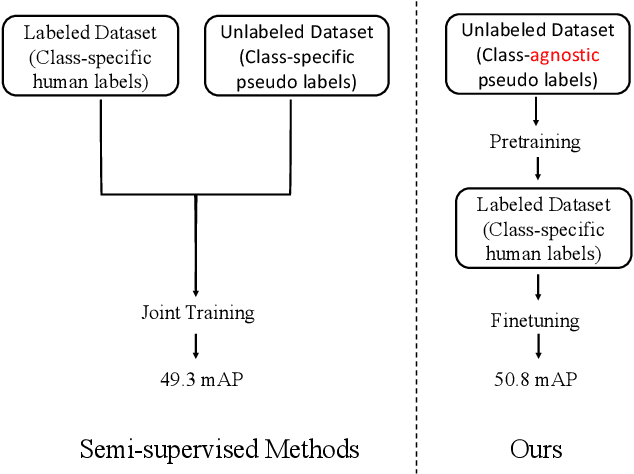
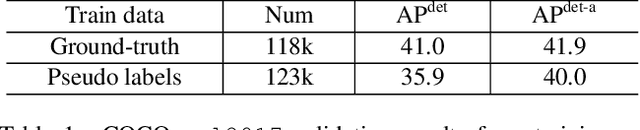
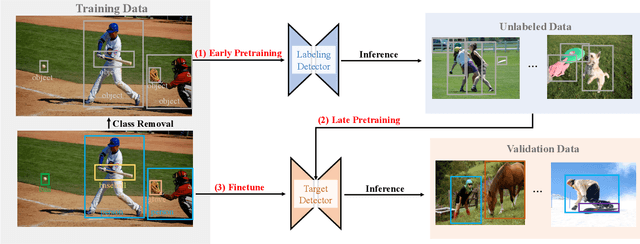
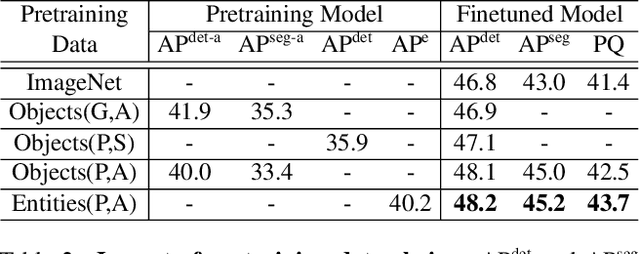
To improve instance-level detection/segmentation performance, existing self-supervised and semi-supervised methods extract either very task-unrelated or very task-specific training signals from unlabeled data. We argue that these two approaches, at the two extreme ends of the task-specificity spectrum, are suboptimal for the task performance. Utilizing too little task-specific training signals causes underfitting to the ground-truth labels of downstream tasks, while the opposite causes overfitting to the ground-truth labels. To this end, we propose a novel Class-agnostic Semi-supervised Pretraining (CaSP) framework to achieve a more favorable task-specificity balance in extracting training signals from unlabeled data. Compared to semi-supervised learning, CaSP reduces the task specificity in training signals by ignoring class information in the pseudo labels and having a separate pretraining stage that uses only task-unrelated unlabeled data. On the other hand, CaSP preserves the right amount of task specificity by leveraging box/mask-level pseudo labels. As a result, our pretrained model can better avoid underfitting/overfitting to ground-truth labels when finetuned on the downstream task. Using 3.6M unlabeled data, we achieve a remarkable performance gain of 4.7% over ImageNet-pretrained baseline on object detection. Our pretrained model also demonstrates excellent transferability to other detection and segmentation tasks/frameworks.
Open-Vocabulary Instance Segmentation via Robust Cross-Modal Pseudo-Labeling
Nov 24, 2021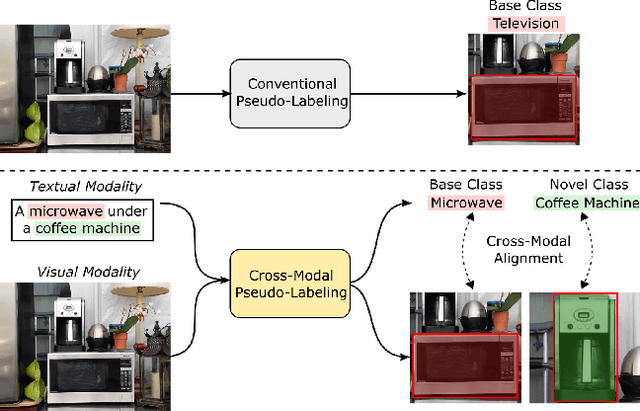

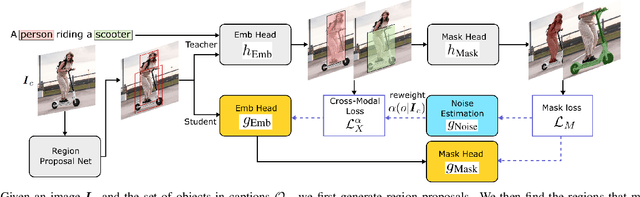
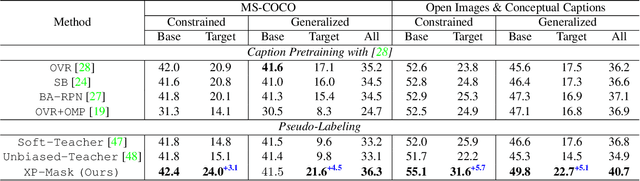
Open-vocabulary instance segmentation aims at segmenting novel classes without mask annotations. It is an important step toward reducing laborious human supervision. Most existing works first pretrain a model on captioned images covering many novel classes and then finetune it on limited base classes with mask annotations. However, the high-level textual information learned from caption pretraining alone cannot effectively encode the details required for pixel-wise segmentation. To address this, we propose a cross-modal pseudo-labeling framework, which generates training pseudo masks by aligning word semantics in captions with visual features of object masks in images. Thus, our framework is capable of labeling novel classes in captions via their word semantics to self-train a student model. To account for noises in pseudo masks, we design a robust student model that selectively distills mask knowledge by estimating the mask noise levels, hence mitigating the adverse impact of noisy pseudo masks. By extensive experiments, we show the effectiveness of our framework, where we significantly improve mAP score by 4.5% on MS-COCO and 5.1% on the large-scale Open Images & Conceptual Captions datasets compared to the state-of-the-art.
Multi-Scale Aligned Distillation for Low-Resolution Detection
Sep 14, 2021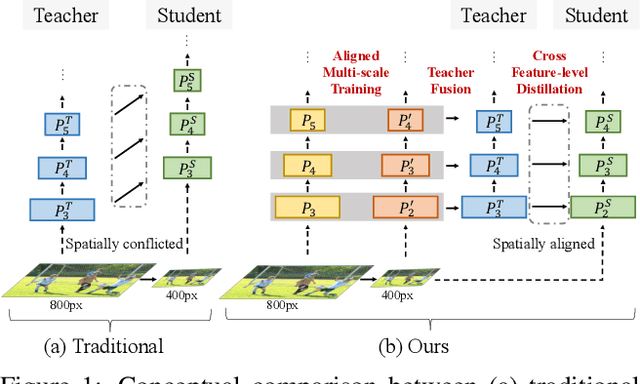
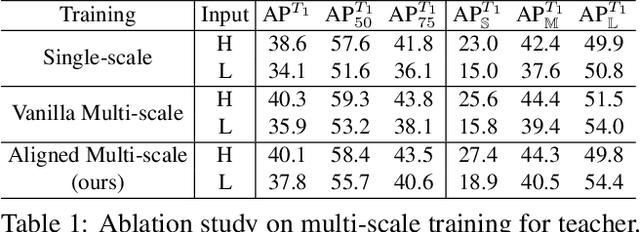
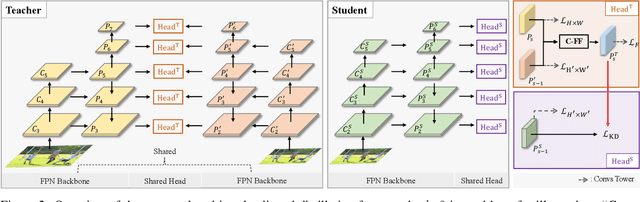

In instance-level detection tasks (e.g., object detection), reducing input resolution is an easy option to improve runtime efficiency. However, this option traditionally hurts the detection performance much. This paper focuses on boosting the performance of low-resolution models by distilling knowledge from a high- or multi-resolution model. We first identify the challenge of applying knowledge distillation (KD) to teacher and student networks that act on different input resolutions. To tackle it, we explore the idea of spatially aligning feature maps between models of varying input resolutions by shifting feature pyramid positions and introduce aligned multi-scale training to train a multi-scale teacher that can distill its knowledge to a low-resolution student. Further, we propose crossing feature-level fusion to dynamically fuse teacher's multi-resolution features to guide the student better. On several instance-level detection tasks and datasets, the low-resolution models trained via our approach perform competitively with high-resolution models trained via conventional multi-scale training, while outperforming the latter's low-resolution models by 2.1% to 3.6% in terms of mAP. Our code is made publicly available at https://github.com/dvlab-research/MSAD.
Open-World Entity Segmentation
Jul 29, 2021
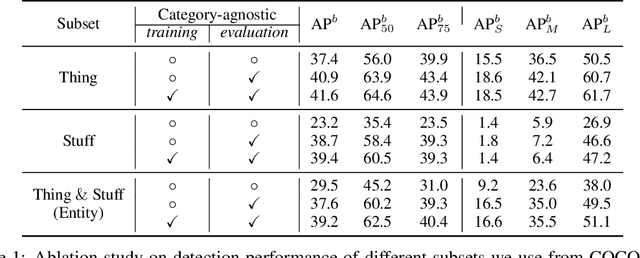


We introduce a new image segmentation task, termed Entity Segmentation (ES) with the aim to segment all visual entities in an image without considering semantic category labels. It has many practical applications in image manipulation/editing where the segmentation mask quality is typically crucial but category labels are less important. In this setting, all semantically-meaningful segments are equally treated as categoryless entities and there is no thing-stuff distinction. Based on our unified entity representation, we propose a center-based entity segmentation framework with two novel modules to improve mask quality. Experimentally, both our new task and framework demonstrate superior advantages as against existing work. In particular, ES enables the following: (1) merging multiple datasets to form a large training set without the need to resolve label conflicts; (2) any model trained on one dataset can generalize exceptionally well to other datasets with unseen domains. Our code is made publicly available at https://github.com/dvlab-research/Entity.
SelfDoc: Self-Supervised Document Representation Learning
Jun 07, 2021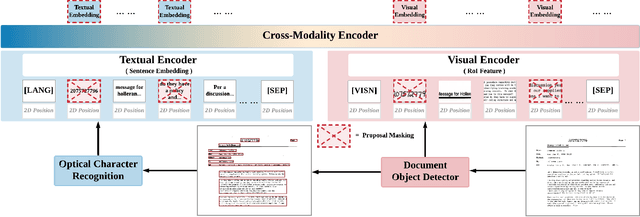
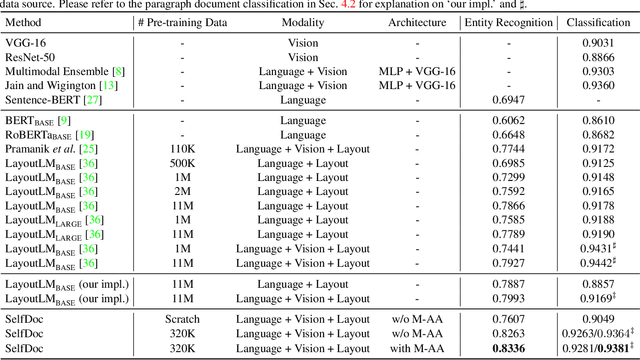
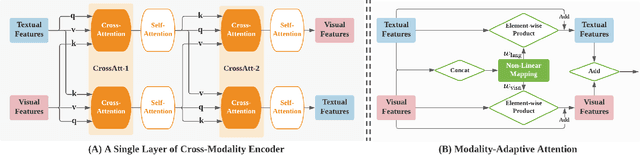

We propose SelfDoc, a task-agnostic pre-training framework for document image understanding. Because documents are multimodal and are intended for sequential reading, our framework exploits the positional, textual, and visual information of every semantically meaningful component in a document, and it models the contextualization between each block of content. Unlike existing document pre-training models, our model is coarse-grained instead of treating individual words as input, therefore avoiding an overly fine-grained with excessive contextualization. Beyond that, we introduce cross-modal learning in the model pre-training phase to fully leverage multimodal information from unlabeled documents. For downstream usage, we propose a novel modality-adaptive attention mechanism for multimodal feature fusion by adaptively emphasizing language and vision signals. Our framework benefits from self-supervised pre-training on documents without requiring annotations by a feature masking training strategy. It achieves superior performance on multiple downstream tasks with significantly fewer document images used in the pre-training stage compared to previous works.
Multimodal Contrastive Training for Visual Representation Learning
Apr 26, 2021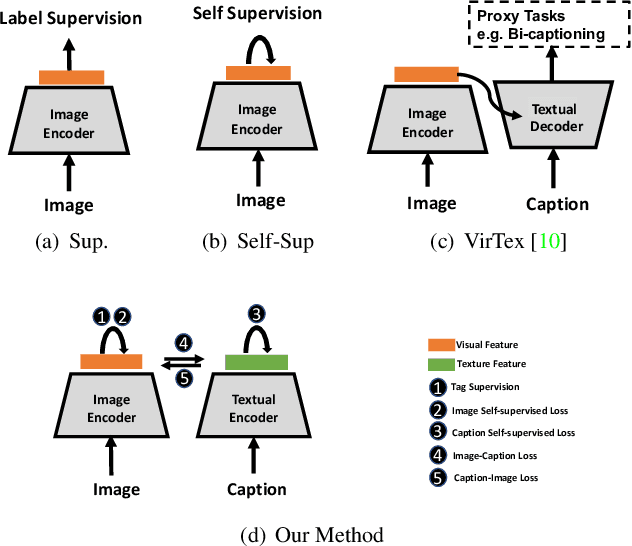
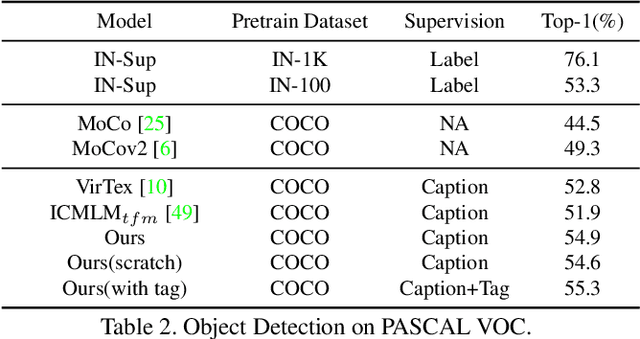
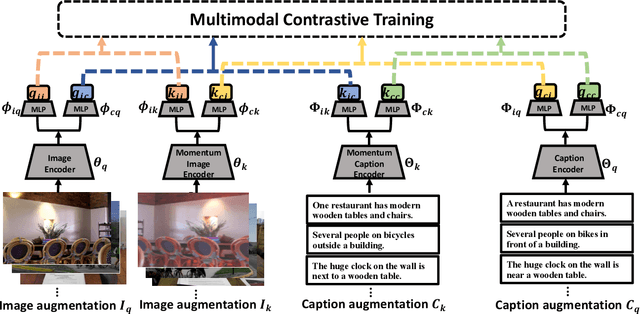
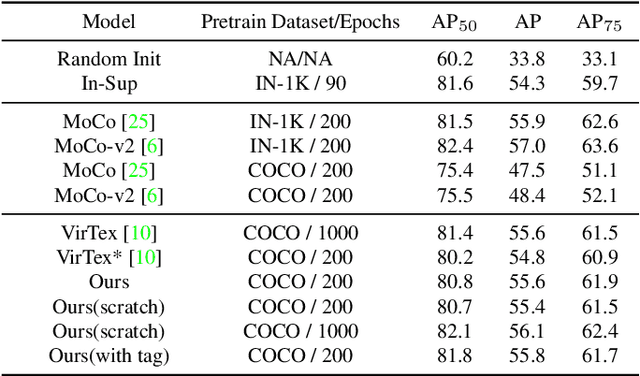
We develop an approach to learning visual representations that embraces multimodal data, driven by a combination of intra- and inter-modal similarity preservation objectives. Unlike existing visual pre-training methods, which solve a proxy prediction task in a single domain, our method exploits intrinsic data properties within each modality and semantic information from cross-modal correlation simultaneously, hence improving the quality of learned visual representations. By including multimodal training in a unified framework with different types of contrastive losses, our method can learn more powerful and generic visual features. We first train our model on COCO and evaluate the learned visual representations on various downstream tasks including image classification, object detection, and instance segmentation. For example, the visual representations pre-trained on COCO by our method achieve state-of-the-art top-1 validation accuracy of $55.3\%$ on ImageNet classification, under the common transfer protocol. We also evaluate our method on the large-scale Stock images dataset and show its effectiveness on multi-label image tagging, and cross-modal retrieval tasks.