 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImageFolder: Autoregressive Image Generation with Folded Tokens
Oct 02, 2024



Image tokenizers are crucial for visual generative models, e.g., diffusion models (DMs) and autoregressive (AR) models, as they construct the latent representation for modeling. Increasing token length is a common approach to improve the image reconstruction quality. However, tokenizers with longer token lengths are not guaranteed to achieve better generation quality. There exists a trade-off between reconstruction and generation quality regarding token length. In this paper, we investigate the impact of token length on both image reconstruction and generation and provide a flexible solution to the tradeoff. We propose ImageFolder, a semantic tokenizer that provides spatially aligned image tokens that can be folded during autoregressive modeling to improve both generation efficiency and quality. To enhance the representative capability without increasing token length, we leverage dual-branch product quantization to capture different contexts of images. Specifically, semantic regularization is introduced in one branch to encourage compacted semantic information while another branch is designed to capture the remaining pixel-level details. Extensive experiments demonstrate the superior quality of image generation and shorter token length with ImageFolder tokenizer.
ControlVAR: Exploring Controllable Visual Autoregressive Modeling
Jun 14, 2024



Conditional visual generation has witnessed remarkable progress with the advent of diffusion models (DMs), especially in tasks like control-to-image generation. However, challenges such as expensive computational cost, high inference latency, and difficulties of integration with large language models (LLMs) have necessitated exploring alternatives to DMs. This paper introduces ControlVAR, a novel framework that explores pixel-level controls in visual autoregressive (VAR) modeling for flexible and efficient conditional generation. In contrast to traditional conditional models that learn the conditional distribution, ControlVAR jointly models the distribution of image and pixel-level conditions during training and imposes conditional controls during testing. To enhance the joint modeling, we adopt the next-scale AR prediction paradigm and unify control and image representations. A teacher-forcing guidance strategy is proposed to further facilitate controllable generation with joint modeling. Extensive experiments demonstrate the superior efficacy and flexibility of ControlVAR across various conditional generation tasks against popular conditional DMs, \eg, ControlNet and T2I-Adaptor.
SOHES: Self-supervised Open-world Hierarchical Entity Segmentation
Apr 18, 2024Open-world entity segmentation, as an emerging computer vision task, aims at segmenting entities in images without being restricted by pre-defined classes, offering impressive generalization capabilities on unseen images and concepts. Despite its promise, existing entity segmentation methods like Segment Anything Model (SAM) rely heavily on costly expert annotators. This work presents Self-supervised Open-world Hierarchical Entity Segmentation (SOHES), a novel approach that eliminates the need for human annotations. SOHES operates in three phases: self-exploration, self-instruction, and self-correction. Given a pre-trained self-supervised representation, we produce abundant high-quality pseudo-labels through visual feature clustering. Then, we train a segmentation model on the pseudo-labels, and rectify the noises in pseudo-labels via a teacher-student mutual-learning procedure. Beyond segmenting entities, SOHES also captures their constituent parts, providing a hierarchical understanding of visual entities. Using raw images as the sole training data, our method achieves unprecedented performance in self-supervised open-world segmentation, marking a significant milestone towards high-quality open-world entity segmentation in the absence of human-annotated masks. Project page: https://SOHES.github.io.
SegGen: Supercharging Segmentation Models with Text2Mask and Mask2Img Synthesis
Nov 06, 2023We propose SegGen, a highly-effective training data generation method for image segmentation, which pushes the performance limits of state-of-the-art segmentation models to a significant extent. SegGen designs and integrates two data generation strategies: MaskSyn and ImgSyn. (i) MaskSyn synthesizes new mask-image pairs via our proposed text-to-mask generation model and mask-to-image generation model, greatly improving the diversity in segmentation masks for model supervision; (ii) ImgSyn synthesizes new images based on existing masks using the mask-to-image generation model, strongly improving image diversity for model inputs. On the highly competitive ADE20K and COCO benchmarks, our data generation method markedly improves the performance of state-of-the-art segmentation models in semantic segmentation, panoptic segmentation, and instance segmentation. Notably, in terms of the ADE20K mIoU, Mask2Former R50 is largely boosted from 47.2 to 49.9 (+2.7); Mask2Former Swin-L is also significantly increased from 56.1 to 57.4 (+1.3). These promising results strongly suggest the effectiveness of our SegGen even when abundant human-annotated training data is utilized. Moreover, training with our synthetic data makes the segmentation models more robust towards unseen domains. Project website: https://seggenerator.github.io
AIMS: All-Inclusive Multi-Level Segmentation
May 28, 2023



Despite the progress of image segmentation for accurate visual entity segmentation, completing the diverse requirements of image editing applications for different-level region-of-interest selections remains unsolved. In this paper, we propose a new task, All-Inclusive Multi-Level Segmentation (AIMS), which segments visual regions into three levels: part, entity, and relation (two entities with some semantic relationships). We also build a unified AIMS model through multi-dataset multi-task training to address the two major challenges of annotation inconsistency and task correlation. Specifically, we propose task complementarity, association, and prompt mask encoder for three-level predictions. Extensive experiments demonstrate the effectiveness and generalization capacity of our method compared to other state-of-the-art methods on a single dataset or the concurrent work on segmenting anything. We will make our code and training model publicly available.
TopNet: Transformer-based Object Placement Network for Image Compositing
Apr 06, 2023



We investigate the problem of automatically placing an object into a background image for image compositing. Given a background image and a segmented object, the goal is to train a model to predict plausible placements (location and scale) of the object for compositing. The quality of the composite image highly depends on the predicted location/scale. Existing works either generate candidate bounding boxes or apply sliding-window search using global representations from background and object images, which fail to model local information in background images. However, local clues in background images are important to determine the compatibility of placing the objects with certain locations/scales. In this paper, we propose to learn the correlation between object features and all local background features with a transformer module so that detailed information can be provided on all possible location/scale configurations. A sparse contrastive loss is further proposed to train our model with sparse supervision. Our new formulation generates a 3D heatmap indicating the plausibility of all location/scale combinations in one network forward pass, which is over 10 times faster than the previous sliding-window method. It also supports interactive search when users provide a pre-defined location or scale. The proposed method can be trained with explicit annotation or in a self-supervised manner using an off-the-shelf inpainting model, and it outperforms state-of-the-art methods significantly. The user study shows that the trained model generalizes well to real-world images with diverse challenging scenes and object categories.
SceneComposer: Any-Level Semantic Image Synthesis
Nov 21, 2022



We propose a new framework for conditional image synthesis from semantic layouts of any precision levels, ranging from pure text to a 2D semantic canvas with precise shapes. More specifically, the input layout consists of one or more semantic regions with free-form text descriptions and adjustable precision levels, which can be set based on the desired controllability. The framework naturally reduces to text-to-image (T2I) at the lowest level with no shape information, and it becomes segmentation-to-image (S2I) at the highest level. By supporting the levels in-between, our framework is flexible in assisting users of different drawing expertise and at different stages of their creative workflow. We introduce several novel techniques to address the challenges coming with this new setup, including a pipeline for collecting training data; a precision-encoded mask pyramid and a text feature map representation to jointly encode precision level, semantics, and composition information; and a multi-scale guided diffusion model to synthesize images. To evaluate the proposed method, we collect a test dataset containing user-drawn layouts with diverse scenes and styles. Experimental results show that the proposed method can generate high-quality images following the layout at given precision, and compares favorably against existing methods. Project page \url{https://zengxianyu.github.io/scenec/}
Fine-Grained Entity Segmentation
Nov 12, 2022



In dense image segmentation tasks (e.g., semantic, panoptic), existing methods can hardly generalize well to unseen image domains, predefined classes, and image resolution & quality variations. Motivated by these observations, we construct a large-scale entity segmentation dataset to explore fine-grained entity segmentation, with a strong focus on open-world and high-quality dense segmentation. The dataset contains images spanning diverse image domains and resolutions, along with high-quality mask annotations for training and testing. Given the high-quality and -resolution nature of the dataset, we propose CropFormer for high-quality segmentation, which can improve mask prediction using high-res image crops that provide more fine-grained image details than the full image. CropFormer is the first query-based Transformer architecture that can effectively ensemble mask predictions from multiple image crops, by learning queries that can associate the same entities across the full image and its crop. With CropFormer, we achieve a significant AP gain of $1.9$ on the challenging fine-grained entity segmentation task. The dataset and code will be released at http://luqi.info/entityv2.github.io/.
Improving the Reliability for Confidence Estimation
Oct 13, 2022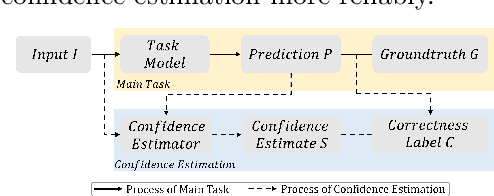

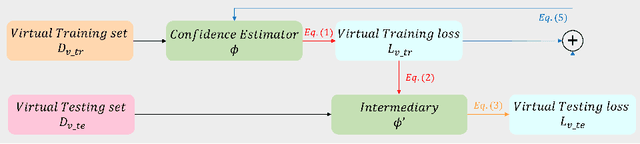
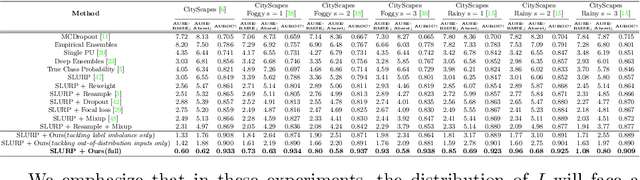
Confidence estimation, a task that aims to evaluate the trustworthiness of the model's prediction output during deployment, has received lots of research attention recently, due to its importance for the safe deployment of deep models. Previous works have outlined two important qualities that a reliable confidence estimation model should possess, i.e., the ability to perform well under label imbalance and the ability to handle various out-of-distribution data inputs. In this work, we propose a meta-learning framework that can simultaneously improve upon both qualities in a confidence estimation model. Specifically, we first construct virtual training and testing sets with some intentionally designed distribution differences between them. Our framework then uses the constructed sets to train the confidence estimation model through a virtual training and testing scheme leading it to learn knowledge that generalizes to diverse distributions. We show the effectiveness of our framework on both monocular depth estimation and image classification.
Text-to-Image Generation via Implicit Visual Guidance and Hypernetwork
Aug 17, 2022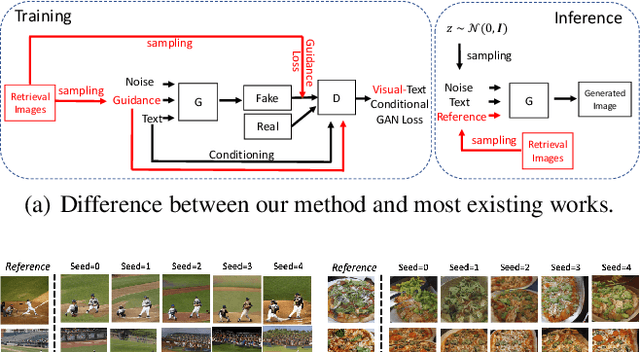
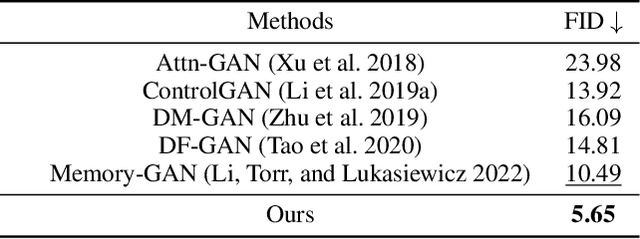
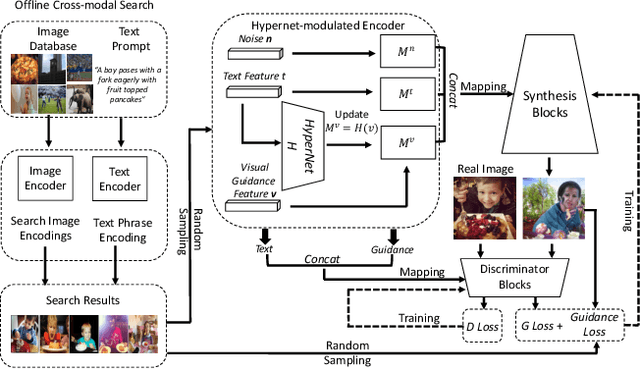
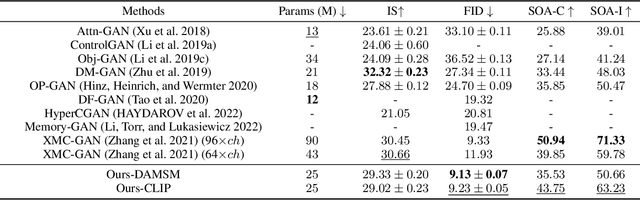
We develop an approach for text-to-image generation that embraces additional retrieval images, driven by a combination of implicit visual guidance loss and generative objectives. Unlike most existing text-to-image generation methods which merely take the text as input, our method dynamically feeds cross-modal search results into a unified training stage, hence improving the quality, controllability and diversity of generation results. We propose a novel hypernetwork modulated visual-text encoding scheme to predict the weight update of the encoding layer, enabling effective transfer from visual information (e.g. layout, content) into the corresponding latent domain. Experimental results show that our model guided with additional retrieval visual data outperforms existing GAN-based models. On COCO dataset, we achieve better FID of $9.13$ with up to $3.5 \times$ fewer generator parameters, compared with the state-of-the-art method.