 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTemporal Backtracking Search for Test-time Generative Video Reasoning
Jun 11, 2026While test-time scaling has revolutionized reasoning in large language models, generative video reasoning remains bottlenecked by a single-shot paradigm. We demonstrate that searching over denoising steps cannot rescue logically flawed rollouts because spatial trajectories commit early in the diffusion process. Root-level Best-of-N (BoN) sampling is similarly inefficient: reasoning errors cluster early in the temporal axis, and resampling blindly discards verified upstream progress. To unlock effective test-time scaling for video models, we introduce Temporal Backtracking Search (TBS), which shifts the search space to the temporal axis. TBS transforms video generation into an iterative generate-verify-restart loop via three core mechanisms: (1) variable-K conditioning to resume generation from arbitrary clean prefixes; (2) temporal process verification to localize failures and extract valid restart anchors; and (3) prefix-based search to reallocate compute toward extending correct trajectories rather than root resampling. Across algorithmic, navigation, and robotics domains, TBS Pareto-dominates matched-budget BoN. In a strict out-of-distribution setting where one-shot generation collapses (0.7% for BoN), TBS achieves 22.7%, with every solved episode stemming from a restarted branch. Ultimately, TBS reveals that the local reasoning competence of video models far exceeds what single-shot rollouts indicate, providing a scalable test-time framework to unlock it.
Economy of Minds: Emerging Multi-Agent Intelligence with Economic Interactions
Jun 01, 2026How can a population of agents self-orchestrate and self-adapt into stronger collective intelligence without centralized control? Inspired by Friedrich Hayek's economic theory of decentralized coordination in markets, we study this question through an agent economy in which agents compete via auctions for the right to act, exchange payments, and accumulate wealth from environmental rewards. These simple economic signals induce decentralized credit assignment, driving planning without global orchestration or explicit communication protocols. The population evolves through economic selection: effective agents accumulate wealth and are mutated via exploitation, while ineffective ones go bankrupt and are replaced via exploration. We show that, initialized with weak agents, the economy produces emergent multi-step reasoning strategies and outperforms stronger monolithic baselines across five agentic tasks, including mathematical reasoning, financial research, scientific research, accelerator design, and distributed-system optimization. We further provide theoretical insights into how economic dynamics shape agent behaviors, linking local incentives to long-term global performance. Our results suggest a new path to multi-agent intelligence: rather than engineering coordination, we can design decentralized incentive structures under which it automatically emerges.
Self-Improving Language Models with Bidirectional Evolutionary Search
May 27, 2026Search has been proposed as an effective method for self-improving language models and agentic systems, both for post-training sample generation and for inference. However, widely used methods such as best-of-N sampling and tree search face two fundamental limitations: they are guided by sparse verification signals, and they construct candidates primarily through autoregressive expansion, restricting exploration to regions with substantial model probability mass. To address these, we propose Bidirectional Evolutionary Search (BES), a search framework that couples forward candidate evolution with backward goal decomposition. In the forward search, BES augments standard expansion with evolution operators that recombine partial trajectories to generate candidates that are difficult to obtain from a single model rollout. In the backward search, BES recursively decomposes the original task into checkable subgoals, producing dense intermediate feedback that guides forward search. We provide theoretical motivation showing that candidates generated by expansion-only search are confined to a narrow entropy shell while evolutionary operators can escape it, and that backward search can exponentially reduce the number of required samples to find a correct answer. Experiments show that on challenging post-training tasks where mainstream post-training algorithms fail to improve, BES enables consistent gains, and on three open problem solving benchmarks at inference time, BES outperforms existing open-source frameworks in both average and best-case performance. Code and trained models are available at https://github.com/Embodied-Minds-Lab/BES.
Intent-aligned Formal Specification Synthesis via Traceable Refinement
Apr 12, 2026Large language models are increasingly used to generate code from natural language, but ensuring correctness remains challenging. Formal verification offers a principled way to obtain such guarantees by proving that a program satisfies a formal specification. However, specifications are frequently missing in real-world codebases, and writing high-quality specifications remains expensive and expertise-intensive. We present VeriSpecGen, a traceable refinement framework that synthesizes intent-aligned specifications in Lean through requirement-level attribution and localized repair. VeriSpecGen decomposes natural language into atomic requirements and generates requirement-targeted tests with explicit traceability maps to validate generated specifications. When validation fails, traceability maps attribute failures to specific requirements, enabling targeted clause-level repairs. VeriSpecGen achieve 86.6% on VERINA SpecGen task using Claude Opus 4.5, improving over baselines by up to 31.8 points across different model families and scales. Beyond inference-time gains, we generate 343K training examples from VeriSpecGen refinement trajectories and demonstrate that training on these trajectories substantially improves specification synthesis by 62-106% relative and transfers gains to general reasoning abilities.
Characterization and Mitigation of Training Instabilities in Microscaling Formats
Jun 25, 2025



Training large language models is an expensive, compute-bound process that must be repeated as models scale, algorithms improve, and new data is collected. To address this, next-generation hardware accelerators increasingly support lower-precision arithmetic formats, such as the Microscaling (MX) formats introduced in NVIDIA's Blackwell architecture. These formats use a shared scale within blocks of parameters to extend representable range and perform forward/backward GEMM operations in reduced precision for efficiency gains. In this work, we investigate the challenges and viability of block-scaled precision formats during model training. Across nearly one thousand language models trained from scratch -- spanning compute budgets from $2 \times 10^{17}$ to $4.8 \times 10^{19}$ FLOPs and sweeping over a broad range of weight-activation precision combinations -- we consistently observe that training in MX formats exhibits sharp, stochastic instabilities in the loss, particularly at larger compute scales. To explain this phenomenon, we conduct controlled experiments and ablations on a smaller proxy model that exhibits similar behavior as the language model, sweeping across architectural settings, hyperparameters, and precision formats. These experiments motivate a simple model in which multiplicative gradient bias introduced by the quantization of layer-norm affine parameters and a small fraction of activations can trigger runaway divergence. Through \emph{in situ} intervention experiments on our proxy model, we demonstrate that instabilities can be averted or delayed by modifying precision schemes mid-training. Guided by these findings, we evaluate stabilization strategies in the LLM setting and show that certain hybrid configurations recover performance competitive with full-precision training. We release our code at https://github.com/Hither1/systems-scaling.
Interpreting the Linear Structure of Vision-language Model Embedding Spaces
Apr 16, 2025



Vision-language models encode images and text in a joint space, minimizing the distance between corresponding image and text pairs. How are language and images organized in this joint space, and how do the models encode meaning and modality? To investigate this, we train and release sparse autoencoders (SAEs) on the embedding spaces of four vision-language models (CLIP, SigLIP, SigLIP2, and AIMv2). SAEs approximate model embeddings as sparse linear combinations of learned directions, or "concepts". We find that, compared to other methods of linear feature learning, SAEs are better at reconstructing the real embeddings, while also able to retain the most sparsity. Retraining SAEs with different seeds or different data diet leads to two findings: the rare, specific concepts captured by the SAEs are liable to change drastically, but we also show that the key commonly-activating concepts extracted by SAEs are remarkably stable across runs. Interestingly, while most concepts are strongly unimodal in activation, we find they are not merely encoding modality per se. Many lie close to - but not entirely within - the subspace defining modality, suggesting that they encode cross-modal semantics despite their unimodal usage. To quantify this bridging behavior, we introduce the Bridge Score, a metric that identifies concept pairs which are both co-activated across aligned image-text inputs and geometrically aligned in the shared space. This reveals that even unimodal concepts can collaborate to support cross-modal integration. We release interactive demos of the SAEs for all models, allowing researchers to explore the organization of the concept spaces. Overall, our findings uncover a sparse linear structure within VLM embedding spaces that is shaped by modality, yet stitched together through latent bridges-offering new insight into how multimodal meaning is constructed.
Data-Efficient Multi-Agent Spatial Planning with LLMs
Feb 26, 2025



In this project, our goal is to determine how to leverage the world-knowledge of pretrained large language models for efficient and robust learning in multiagent decision making. We examine this in a taxi routing and assignment problem where agents must decide how to best pick up passengers in order to minimize overall waiting time. While this problem is situated on a graphical road network, we show that with the proper prompting zero-shot performance is quite strong on this task. Furthermore, with limited fine-tuning along with the one-at-a-time rollout algorithm for look ahead, LLMs can out-compete existing approaches with 50 times fewer environmental interactions. We also explore the benefits of various linguistic prompting approaches and show that including certain easy-to-compute information in the prompt significantly improves performance. Finally, we highlight the LLM's built-in semantic understanding, showing its ability to adapt to environmental factors through simple prompts.
Tractable Joint Prediction and Planning over Discrete Behavior Modes for Urban Driving
Mar 12, 2024Significant progress has been made in training multimodal trajectory forecasting models for autonomous driving. However, effectively integrating these models with downstream planners and model-based control approaches is still an open problem. Although these models have conventionally been evaluated for open-loop prediction, we show that they can be used to parameterize autoregressive closed-loop models without retraining. We consider recent trajectory prediction approaches which leverage learned anchor embeddings to predict multiple trajectories, finding that these anchor embeddings can parameterize discrete and distinct modes representing high-level driving behaviors. We propose to perform fully reactive closed-loop planning over these discrete latent modes, allowing us to tractably model the causal interactions between agents at each step. We validate our approach on a suite of more dynamic merging scenarios, finding that our approach avoids the $\textit{frozen robot problem}$ which is pervasive in conventional planners. Our approach also outperforms the previous state-of-the-art in CARLA on challenging dense traffic scenarios when evaluated at realistic speeds.
Diffusion-ES: Gradient-free Planning with Diffusion for Autonomous Driving and Zero-Shot Instruction Following
Feb 09, 2024



Diffusion models excel at modeling complex and multimodal trajectory distributions for decision-making and control. Reward-gradient guided denoising has been recently proposed to generate trajectories that maximize both a differentiable reward function and the likelihood under the data distribution captured by a diffusion model. Reward-gradient guided denoising requires a differentiable reward function fitted to both clean and noised samples, limiting its applicability as a general trajectory optimizer. In this paper, we propose DiffusionES, a method that combines gradient-free optimization with trajectory denoising to optimize black-box non-differentiable objectives while staying in the data manifold. Diffusion-ES samples trajectories during evolutionary search from a diffusion model and scores them using a black-box reward function. It mutates high-scoring trajectories using a truncated diffusion process that applies a small number of noising and denoising steps, allowing for much more efficient exploration of the solution space. We show that DiffusionES achieves state-of-the-art performance on nuPlan, an established closed-loop planning benchmark for autonomous driving. Diffusion-ES outperforms existing sampling-based planners, reactive deterministic or diffusion-based policies, and reward-gradient guidance. Additionally, we show that unlike prior guidance methods, our method can optimize non-differentiable language-shaped reward functions generated by few-shot LLM prompting. When guided by a human teacher that issues instructions to follow, our method can generate novel, highly complex behaviors, such as aggressive lane weaving, which are not present in the training data. This allows us to solve the hardest nuPlan scenarios which are beyond the capabilities of existing trajectory optimization methods and driving policies.
Representation Gap in Deep Reinforcement Learning
May 29, 2022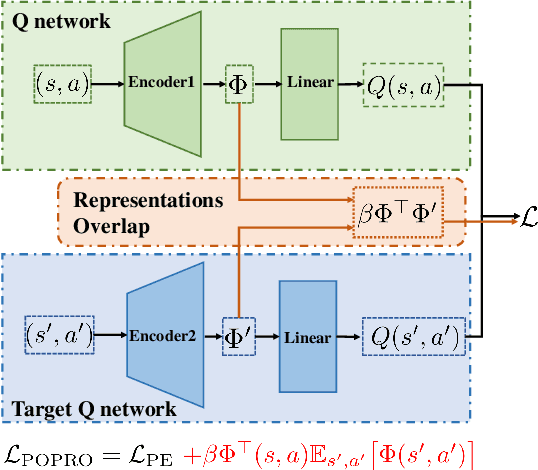
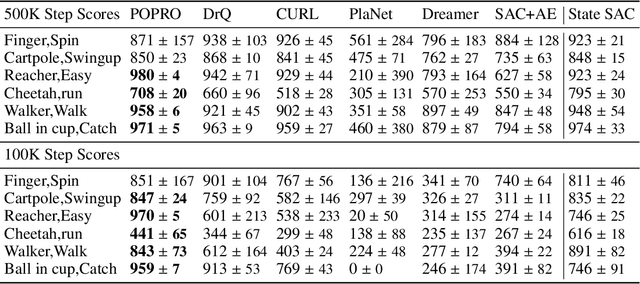
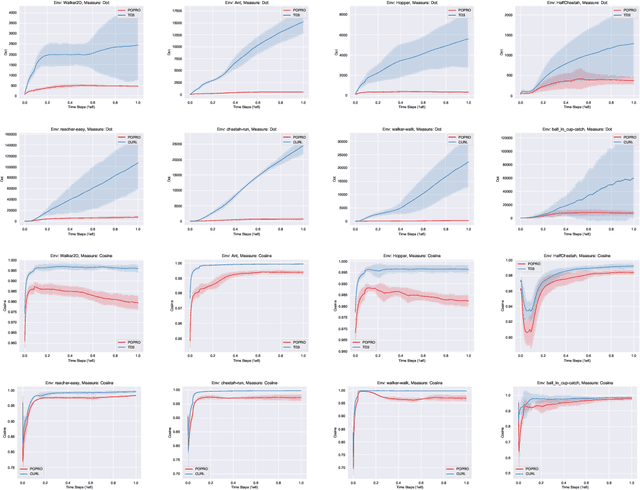
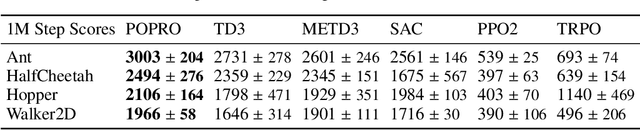
Deep reinforcement learning gives the promise that an agent learns good policy from high-dimensional information. Whereas representation learning removes irrelevant and redundant information and retains pertinent information. We consider the representation capacity of action value function and theoretically reveal its inherent property, \textit{representation gap} with its target action value function. This representation gap is favorable. However, through illustrative experiments, we show that the representation of action value function grows similarly compared with its target value function, i.e. the undesirable inactivity of the representation gap (\textit{representation overlap}). Representation overlap results in a loss of representation capacity, which further leads to sub-optimal learning performance. To activate the representation gap, we propose a simple but effective framework \underline{P}olicy \underline{O}ptimization from \underline{P}reventing \underline{R}epresentation \underline{O}verlaps (POPRO), which regularizes the policy evaluation phase through differing the representation of action value function from its target. We also provide the convergence rate guarantee of POPRO. We evaluate POPRO on gym continuous control suites. The empirical results show that POPRO using pixel inputs outperforms or parallels the sample-efficiency of methods that use state-based features.