 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEconomy of Minds: Emerging Multi-Agent Intelligence with Economic Interactions
Jun 01, 2026How can a population of agents self-orchestrate and self-adapt into stronger collective intelligence without centralized control? Inspired by Friedrich Hayek's economic theory of decentralized coordination in markets, we study this question through an agent economy in which agents compete via auctions for the right to act, exchange payments, and accumulate wealth from environmental rewards. These simple economic signals induce decentralized credit assignment, driving planning without global orchestration or explicit communication protocols. The population evolves through economic selection: effective agents accumulate wealth and are mutated via exploitation, while ineffective ones go bankrupt and are replaced via exploration. We show that, initialized with weak agents, the economy produces emergent multi-step reasoning strategies and outperforms stronger monolithic baselines across five agentic tasks, including mathematical reasoning, financial research, scientific research, accelerator design, and distributed-system optimization. We further provide theoretical insights into how economic dynamics shape agent behaviors, linking local incentives to long-term global performance. Our results suggest a new path to multi-agent intelligence: rather than engineering coordination, we can design decentralized incentive structures under which it automatically emerges.
Self-Improving Language Models with Bidirectional Evolutionary Search
May 27, 2026Search has been proposed as an effective method for self-improving language models and agentic systems, both for post-training sample generation and for inference. However, widely used methods such as best-of-N sampling and tree search face two fundamental limitations: they are guided by sparse verification signals, and they construct candidates primarily through autoregressive expansion, restricting exploration to regions with substantial model probability mass. To address these, we propose Bidirectional Evolutionary Search (BES), a search framework that couples forward candidate evolution with backward goal decomposition. In the forward search, BES augments standard expansion with evolution operators that recombine partial trajectories to generate candidates that are difficult to obtain from a single model rollout. In the backward search, BES recursively decomposes the original task into checkable subgoals, producing dense intermediate feedback that guides forward search. We provide theoretical motivation showing that candidates generated by expansion-only search are confined to a narrow entropy shell while evolutionary operators can escape it, and that backward search can exponentially reduce the number of required samples to find a correct answer. Experiments show that on challenging post-training tasks where mainstream post-training algorithms fail to improve, BES enables consistent gains, and on three open problem solving benchmarks at inference time, BES outperforms existing open-source frameworks in both average and best-case performance. Code and trained models are available at https://github.com/Embodied-Minds-Lab/BES.
Scaling Tasks, Not Samples: Mastering Humanoid Control through Multi-Task Model-Based Reinforcement Learning
Mar 02, 2026Developing generalist robots capable of mastering diverse skills remains a central challenge in embodied AI. While recent progress emphasizes scaling model parameters and offline datasets, such approaches are limited in robotics, where learning requires active interaction. We argue that effective online learning should scale the \emph{number of tasks}, rather than the number of samples per task. This regime reveals a structural advantage of model-based reinforcement learning (MBRL). Because physical dynamics are invariant across tasks, a shared world model can aggregate multi-task experience to learn robust, task-agnostic representations. In contrast, model-free methods suffer from gradient interference when tasks demand conflicting actions in similar states. Task diversity therefore acts as a regularizer for MBRL, improving dynamics learning and sample efficiency. We instantiate this idea with \textbf{EfficientZero-Multitask (EZ-M)}, a sample-efficient multi-task MBRL algorithm for online learning. Evaluated on \textbf{HumanoidBench}, a challenging whole-body control benchmark, EZ-M achieves state-of-the-art performance with significantly higher sample efficiency than strong baselines, without extreme parameter scaling. These results establish task scaling as a critical axis for scalable robotic learning. The project website is available \href{https://yewr.github.io/ez_m/}{here}.
TreeGRPO: Tree-Advantage GRPO for Online RL Post-Training of Diffusion Models
Dec 09, 2025



Reinforcement learning (RL) post-training is crucial for aligning generative models with human preferences, but its prohibitive computational cost remains a major barrier to widespread adoption. We introduce \textbf{TreeGRPO}, a novel RL framework that dramatically improves training efficiency by recasting the denoising process as a search tree. From shared initial noise samples, TreeGRPO strategically branches to generate multiple candidate trajectories while efficiently reusing their common prefixes. This tree-structured approach delivers three key advantages: (1) \emph{High sample efficiency}, achieving better performance under same training samples (2) \emph{Fine-grained credit assignment} via reward backpropagation that computes step-specific advantages, overcoming the uniform credit assignment limitation of trajectory-based methods, and (3) \emph{Amortized computation} where multi-child branching enables multiple policy updates per forward pass. Extensive experiments on both diffusion and flow-based models demonstrate that TreeGRPO achieves \textbf{2.4$\times$ faster training} while establishing a superior Pareto frontier in the efficiency-reward trade-off space. Our method consistently outperforms GRPO baselines across multiple benchmarks and reward models, providing a scalable and effective pathway for RL-based visual generative model alignment. The project website is available at treegrpo.github.io.
Learning Manipulation Skills through Robot Chain-of-Thought with Sparse Failure Guidance
May 22, 2024



The acquisition of manipulation skills through language instruction remains an unresolved challenge. Recently, vision-language models have made significant progress in teaching robots these skills. However, their performance is restricted to a narrow range of simple tasks. In this paper, we propose that vision-language models can provide a superior source of rewards for agents. Our method decomposes complex tasks into simpler sub-goals, enabling better task comprehension and avoiding potential failures with sparse failure guidance. Empirical evidence demonstrates that our algorithm consistently outperforms baselines such as CLIP, LIV, and RoboCLIP. Specifically, our algorithm achieves a $5.4\times$ higher average success rate compared to the best baseline, RoboCLIP, across a series of manipulation tasks. It has shown a comprehensive understanding of a wide range of robotic manipulation tasks.
EfficientZero V2: Mastering Discrete and Continuous Control with Limited Data
Mar 01, 2024Sample efficiency remains a crucial challenge in applying Reinforcement Learning (RL) to real-world tasks. While recent algorithms have made significant strides in improving sample efficiency, none have achieved consistently superior performance across diverse domains. In this paper, we introduce EfficientZero V2, a general framework designed for sample-efficient RL algorithms. We have expanded the performance of EfficientZero to multiple domains, encompassing both continuous and discrete actions, as well as visual and low-dimensional inputs. With a series of improvements we propose, EfficientZero V2 outperforms the current state-of-the-art (SOTA) by a significant margin in diverse tasks under the limited data setting. EfficientZero V2 exhibits a notable advancement over the prevailing general algorithm, DreamerV3, achieving superior outcomes in 50 of 66 evaluated tasks across diverse benchmarks, such as Atari 100k, Proprio Control, and Vision Control.
Foundation Reinforcement Learning: towards Embodied Generalist Agents with Foundation Prior Assistance
Oct 10, 2023



Recently, people have shown that large-scale pre-training from internet-scale data is the key to building generalist models, as witnessed in NLP. To build embodied generalist agents, we and many other researchers hypothesize that such foundation prior is also an indispensable component. However, it is unclear what is the proper concrete form to represent those embodied foundation priors and how they should be used in the downstream task. In this paper, we propose an intuitive and effective set of embodied priors that consist of foundation policy, value, and success reward. The proposed priors are based on the goal-conditioned MDP. To verify their effectiveness, we instantiate an actor-critic method assisted by the priors, called Foundation Actor-Critic (FAC). We name our framework as Foundation Reinforcement Learning (FRL), since it completely relies on embodied foundation priors to explore, learn and reinforce. The benefits of FRL are threefold. (1) Sample efficient. With foundation priors, FAC learns significantly faster than traditional RL. Our evaluation on the Meta-World has proved that FAC can achieve 100% success rates for 7/8 tasks under less than 200k frames, which outperforms the baseline method with careful manual-designed rewards under 1M frames. (2) Robust to noisy priors. Our method tolerates the unavoidable noise in embodied foundation models. We show that FAC works well even under heavy noise or quantization errors. (3) Minimal human intervention: FAC completely learns from the foundation priors, without the need of human-specified dense reward, or providing teleoperated demos. Thus, FAC can be easily scaled up. We believe our FRL framework could enable the future robot to autonomously explore and learn without human intervention in the physical world. In summary, our proposed FRL is a novel and powerful learning paradigm, towards achieving embodied generalist agents.
Real-time scheduling of renewable power systems through planning-based reinforcement learning
Mar 13, 2023



The growing renewable energy sources have posed significant challenges to traditional power scheduling. It is difficult for operators to obtain accurate day-ahead forecasts of renewable generation, thereby requiring the future scheduling system to make real-time scheduling decisions aligning with ultra-short-term forecasts. Restricted by the computation speed, traditional optimization-based methods can not solve this problem. Recent developments in reinforcement learning (RL) have demonstrated the potential to solve this challenge. However, the existing RL methods are inadequate in terms of constraint complexity, algorithm performance, and environment fidelity. We are the first to propose a systematic solution based on the state-of-the-art reinforcement learning algorithm and the real power grid environment. The proposed approach enables planning and finer time resolution adjustments of power generators, including unit commitment and economic dispatch, thus increasing the grid's ability to admit more renewable energy. The well-trained scheduling agent significantly reduces renewable curtailment and load shedding, which are issues arising from traditional scheduling's reliance on inaccurate day-ahead forecasts. High-frequency control decisions exploit the existing units' flexibility, reducing the power grid's dependence on hardware transformations and saving investment and operating costs, as demonstrated in experimental results. This research exhibits the potential of reinforcement learning in promoting low-carbon and intelligent power systems and represents a solid step toward sustainable electricity generation.
Spending Thinking Time Wisely: Accelerating MCTS with Virtual Expansions
Oct 23, 2022



One of the most important AI research questions is to trade off computation versus performance since ``perfect rationality" exists in theory but is impossible to achieve in practice. Recently, Monte-Carlo tree search (MCTS) has attracted considerable attention due to the significant performance improvement in various challenging domains. However, the expensive time cost during search severely restricts its scope for applications. This paper proposes the Virtual MCTS (V-MCTS), a variant of MCTS that spends more search time on harder states and less search time on simpler states adaptively. We give theoretical bounds of the proposed method and evaluate the performance and computations on $9 \times 9$ Go board games and Atari games. Experiments show that our method can achieve comparable performances to the original search algorithm while requiring less than $50\%$ search time on average. We believe that this approach is a viable alternative for tasks under limited time and resources. The code is available at \url{https://github.com/YeWR/V-MCTS.git}.
Planning for Sample Efficient Imitation Learning
Oct 18, 2022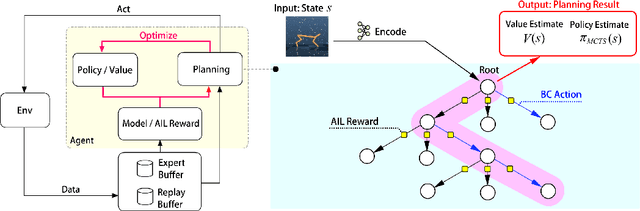
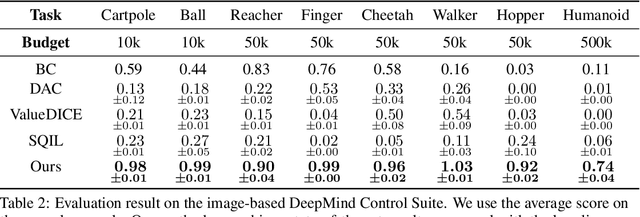

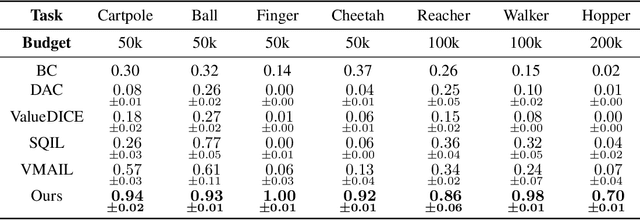
Imitation learning is a class of promising policy learning algorithms that is free from many practical issues with reinforcement learning, such as the reward design issue and the exploration hardness. However, the current imitation algorithm struggles to achieve both high performance and high in-environment sample efficiency simultaneously. Behavioral Cloning (BC) does not need in-environment interactions, but it suffers from the covariate shift problem which harms its performance. Adversarial Imitation Learning (AIL) turns imitation learning into a distribution matching problem. It can achieve better performance on some tasks but it requires a large number of in-environment interactions. Inspired by the recent success of EfficientZero in RL, we propose EfficientImitate (EI), a planning-based imitation learning method that can achieve high in-environment sample efficiency and performance simultaneously. Our algorithmic contribution in this paper is two-fold. First, we extend AIL into the MCTS-based RL. Second, we show the seemingly incompatible two classes of imitation algorithms (BC and AIL) can be naturally unified under our framework, enjoying the benefits of both. We benchmark our method not only on the state-based DeepMind Control Suite, but also on the image version which many previous works find highly challenging. Experimental results show that EI achieves state-of-the-art results in performance and sample efficiency. EI shows over 4x gain in performance in the limited sample setting on state-based and image-based tasks and can solve challenging problems like Humanoid, where previous methods fail with small amount of interactions. Our code is available at https://github.com/zhaohengyin/EfficientImitate.