 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQ-Hawkeye: Reliable Visual Policy Optimization for Image Quality Assessment
Jan 30, 2026Image Quality Assessment (IQA) predicts perceptual quality scores consistent with human judgments. Recent RL-based IQA methods built on MLLMs focus on generating visual quality descriptions and scores, ignoring two key reliability limitations: (i) although the model's prediction stability varies significantly across training samples, existing GRPO-based methods apply uniform advantage weighting, thereby amplifying noisy signals from unstable samples in gradient updates; (ii) most works emphasize text-grounded reasoning over images while overlooking the model's visual perception ability of image content. In this paper, we propose Q-Hawkeye, an RL-based reliable visual policy optimization framework that redesigns the learning signal through unified Uncertainty-Aware Dynamic Optimization and Perception-Aware Optimization. Q-Hawkeye estimates predictive uncertainty using the variance of predicted scores across multiple rollouts and leverages this uncertainty to reweight each sample's update strength, stabilizing policy optimization. To strengthen perceptual reliability, we construct paired inputs of degraded images and their original images and introduce an Implicit Perception Loss that constrains the model to ground its quality judgments in genuine visual evidence. Extensive experiments demonstrate that Q-Hawkeye outperforms state-of-the-art methods and generalizes better across multiple datasets. The code and models will be made available.
GaussMarker: Robust Dual-Domain Watermark for Diffusion Models
Jun 13, 2025As Diffusion Models (DM) generate increasingly realistic images, related issues such as copyright and misuse have become a growing concern. Watermarking is one of the promising solutions. Existing methods inject the watermark into the single-domain of initial Gaussian noise for generation, which suffers from unsatisfactory robustness. This paper presents the first dual-domain DM watermarking approach using a pipelined injector to consistently embed watermarks in both the spatial and frequency domains. To further boost robustness against certain image manipulations and advanced attacks, we introduce a model-independent learnable Gaussian Noise Restorer (GNR) to refine Gaussian noise extracted from manipulated images and enhance detection robustness by integrating the detection scores of both watermarks. GaussMarker efficiently achieves state-of-the-art performance under eight image distortions and four advanced attacks across three versions of Stable Diffusion with better recall and lower false positive rates, as preferred in real applications.
From Easy to Hard: Building a Shortcut for Differentially Private Image Synthesis
Apr 02, 2025



Differentially private (DP) image synthesis aims to generate synthetic images from a sensitive dataset, alleviating the privacy leakage concerns of organizations sharing and utilizing synthetic images. Although previous methods have significantly progressed, especially in training diffusion models on sensitive images with DP Stochastic Gradient Descent (DP-SGD), they still suffer from unsatisfactory performance. In this work, inspired by curriculum learning, we propose a two-stage DP image synthesis framework, where diffusion models learn to generate DP synthetic images from easy to hard. Unlike existing methods that directly use DP-SGD to train diffusion models, we propose an easy stage in the beginning, where diffusion models learn simple features of the sensitive images. To facilitate this easy stage, we propose to use `central images', simply aggregations of random samples of the sensitive dataset. Intuitively, although those central images do not show details, they demonstrate useful characteristics of all images and only incur minimal privacy costs, thus helping early-phase model training. We conduct experiments to present that on the average of four investigated image datasets, the fidelity and utility metrics of our synthetic images are 33.1% and 2.1% better than the state-of-the-art method.
DAS3D: Dual-modality Anomaly Synthesis for 3D Anomaly Detection
Oct 13, 2024



Synthesizing anomaly samples has proven to be an effective strategy for self-supervised 2D industrial anomaly detection. However, this approach has been rarely explored in multi-modality anomaly detection, particularly involving 3D and RGB images. In this paper, we propose a novel dual-modality augmentation method for 3D anomaly synthesis, which is simple and capable of mimicking the characteristics of 3D defects. Incorporating with our anomaly synthesis method, we introduce a reconstruction-based discriminative anomaly detection network, in which a dual-modal discriminator is employed to fuse the original and reconstructed embedding of two modalities for anomaly detection. Additionally, we design an augmentation dropout mechanism to enhance the generalizability of the discriminator. Extensive experiments show that our method outperforms the state-of-the-art methods on detection precision and achieves competitive segmentation performance on both MVTec 3D-AD and Eyescandies datasets.
Keep Various Trajectories: Promoting Exploration of Ensemble Policies in Continuous Control
Oct 17, 2023The combination of deep reinforcement learning (DRL) with ensemble methods has been proved to be highly effective in addressing complex sequential decision-making problems. This success can be primarily attributed to the utilization of multiple models, which enhances both the robustness of the policy and the accuracy of value function estimation. However, there has been limited analysis of the empirical success of current ensemble RL methods thus far. Our new analysis reveals that the sample efficiency of previous ensemble DRL algorithms may be limited by sub-policies that are not as diverse as they could be. Motivated by these findings, our study introduces a new ensemble RL algorithm, termed \textbf{T}rajectories-awar\textbf{E} \textbf{E}nsemble exploratio\textbf{N} (TEEN). The primary goal of TEEN is to maximize the expected return while promoting more diverse trajectories. Through extensive experiments, we demonstrate that TEEN not only enhances the sample diversity of the ensemble policy compared to using sub-policies alone but also improves the performance over ensemble RL algorithms. On average, TEEN outperforms the baseline ensemble DRL algorithms by 41\% in performance on the tested representative environments.
Recover Triggered States: Protect Model Against Backdoor Attack in Reinforcement Learning
Apr 10, 2023A backdoor attack allows a malicious user to manipulate the environment or corrupt the training data, thus inserting a backdoor into the trained agent. Such attacks compromise the RL system's reliability, leading to potentially catastrophic results in various key fields. In contrast, relatively limited research has investigated effective defenses against backdoor attacks in RL. This paper proposes the Recovery Triggered States (RTS) method, a novel approach that effectively protects the victim agents from backdoor attacks. RTS involves building a surrogate network to approximate the dynamics model. Developers can then recover the environment from the triggered state to a clean state, thereby preventing attackers from activating backdoors hidden in the agent by presenting the trigger. When training the surrogate to predict states, we incorporate agent action information to reduce the discrepancy between the actions taken by the agent on predicted states and the actions taken on real states. RTS is the first approach to defend against backdoor attacks in a single-agent setting. Our results show that using RTS, the cumulative reward only decreased by 1.41% under the backdoor attack.
Centralized Cooperative Exploration Policy for Continuous Control Tasks
Jan 06, 2023



The deep reinforcement learning (DRL) algorithm works brilliantly on solving various complex control tasks. This phenomenal success can be partly attributed to DRL encouraging intelligent agents to sufficiently explore the environment and collect diverse experiences during the agent training process. Therefore, exploration plays a significant role in accessing an optimal policy for DRL. Despite recent works making great progress in continuous control tasks, exploration in these tasks has remained insufficiently investigated. To explicitly encourage exploration in continuous control tasks, we propose CCEP (Centralized Cooperative Exploration Policy), which utilizes underestimation and overestimation of value functions to maintain the capacity of exploration. CCEP first keeps two value functions initialized with different parameters, and generates diverse policies with multiple exploration styles from a pair of value functions. In addition, a centralized policy framework ensures that CCEP achieves message delivery between multiple policies, furthermore contributing to exploring the environment cooperatively. Extensive experimental results demonstrate that CCEP achieves higher exploration capacity. Empirical analysis shows diverse exploration styles in the learned policies by CCEP, reaping benefits in more exploration regions. And this exploration capacity of CCEP ensures it outperforms the current state-of-the-art methods across multiple continuous control tasks shown in experiments.
Unsupervised Domain Adaptation GAN Inversion for Image Editing
Nov 22, 2022



Existing GAN inversion methods work brilliantly for high-quality image reconstruction and editing while struggling with finding the corresponding high-quality images for low-quality inputs. Therefore, recent works are directed toward leveraging the supervision of paired high-quality and low-quality images for inversion. However, these methods are infeasible in real-world scenarios and further hinder performance improvement. In this paper, we resolve this problem by introducing Unsupervised Domain Adaptation (UDA) into the Inversion process, namely UDA-Inversion, for both high-quality and low-quality image inversion and editing. Particularly, UDA-Inversion first regards the high-quality and low-quality images as the source domain and unlabeled target domain, respectively. Then, a discrepancy function is presented to measure the difference between two domains, after which we minimize the source error and the discrepancy between the distributions of two domains in the latent space to obtain accurate latent codes for low-quality images. Without direct supervision, constructive representations of high-quality images can be spontaneously learned and transformed into low-quality images based on unsupervised domain adaptation. Experimental results indicate that UDA-inversion is the first that achieves a comparable level of performance with supervised methods in low-quality images across multiple domain datasets. We hope this work provides a unique inspiration for latent embedding distributions in image process tasks.
Mind Your Data! Hiding Backdoors in Offline Reinforcement Learning Datasets
Oct 07, 2022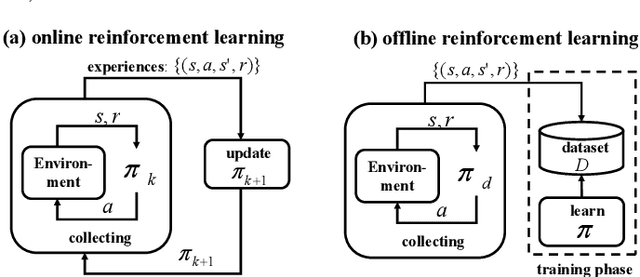

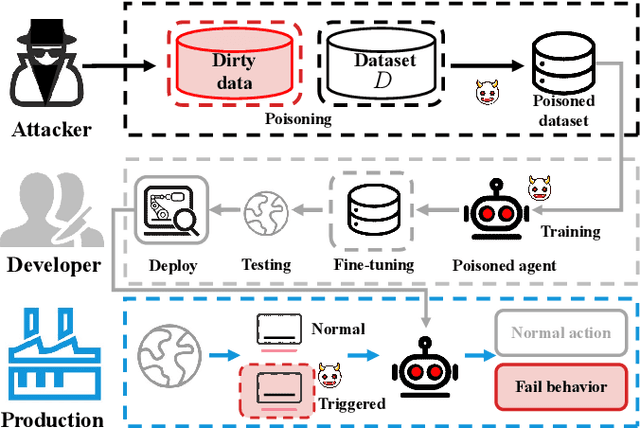
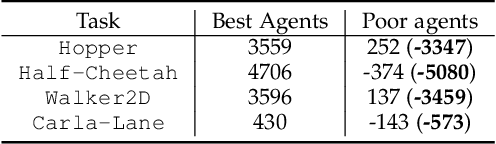
A growing body of research works has focused on the Offline Reinforcement Learning (RL) paradigm. Data providers share large pre-collected datasets on which others can train high-quality agents without interacting with the environments. Such an offline RL paradigm has demonstrated effectiveness in many critical tasks, including robot control, autonomous driving, etc. A well-trained agent can be regarded as a software system. However, less attention is paid to investigating the security threats to the offline RL system. In this paper, we focus on a critical security threat: backdoor attacks. Given normal observations, an agent implanted with backdoors takes actions leading to high rewards. However, the same agent takes actions that lead to low rewards if the observations are injected with triggers that can activate the backdoor. In this paper, we propose Baffle (Backdoor Attack for Offline Reinforcement Learning) and evaluate how different Offline RL algorithms react to this attack. Our experiments conducted on four tasks and four offline RL algorithms expose a disquieting fact: none of the existing offline RL algorithms is immune to such a backdoor attack. More specifically, Baffle modifies $10\%$ of the datasets for four tasks (3 robotic controls and 1 autonomous driving). Agents trained on the poisoned datasets perform well in normal settings. However, when triggers are presented, the agents' performance decreases drastically by $63.6\%$, $57.8\%$, $60.8\%$ and $44.7\%$ in the four tasks on average. The backdoor still persists after fine-tuning poisoned agents on clean datasets. We further show that the inserted backdoor is also hard to be detected by a popular defensive method. This paper calls attention to developing more effective protection for the open-source offline RL dataset.
Representation Gap in Deep Reinforcement Learning
May 29, 2022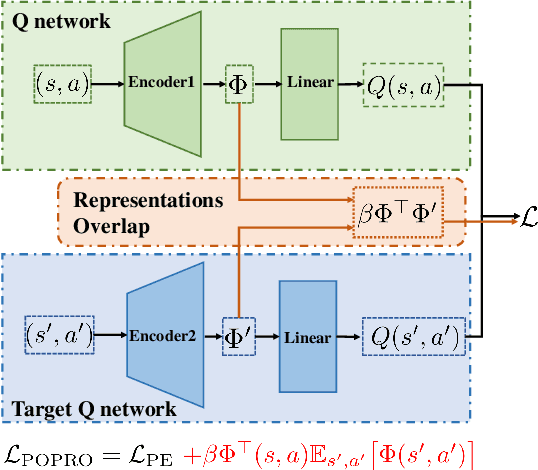
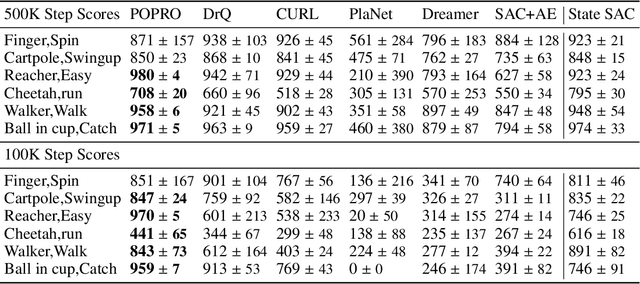
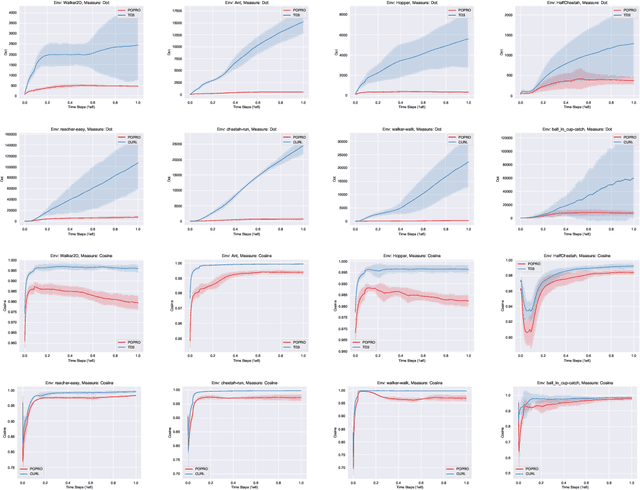
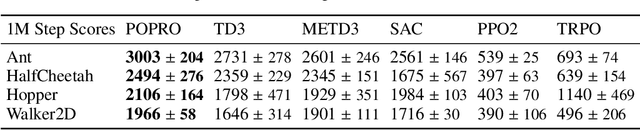
Deep reinforcement learning gives the promise that an agent learns good policy from high-dimensional information. Whereas representation learning removes irrelevant and redundant information and retains pertinent information. We consider the representation capacity of action value function and theoretically reveal its inherent property, \textit{representation gap} with its target action value function. This representation gap is favorable. However, through illustrative experiments, we show that the representation of action value function grows similarly compared with its target value function, i.e. the undesirable inactivity of the representation gap (\textit{representation overlap}). Representation overlap results in a loss of representation capacity, which further leads to sub-optimal learning performance. To activate the representation gap, we propose a simple but effective framework \underline{P}olicy \underline{O}ptimization from \underline{P}reventing \underline{R}epresentation \underline{O}verlaps (POPRO), which regularizes the policy evaluation phase through differing the representation of action value function from its target. We also provide the convergence rate guarantee of POPRO. We evaluate POPRO on gym continuous control suites. The empirical results show that POPRO using pixel inputs outperforms or parallels the sample-efficiency of methods that use state-based features.