 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntent-aligned Formal Specification Synthesis via Traceable Refinement
Apr 12, 2026Large language models are increasingly used to generate code from natural language, but ensuring correctness remains challenging. Formal verification offers a principled way to obtain such guarantees by proving that a program satisfies a formal specification. However, specifications are frequently missing in real-world codebases, and writing high-quality specifications remains expensive and expertise-intensive. We present VeriSpecGen, a traceable refinement framework that synthesizes intent-aligned specifications in Lean through requirement-level attribution and localized repair. VeriSpecGen decomposes natural language into atomic requirements and generates requirement-targeted tests with explicit traceability maps to validate generated specifications. When validation fails, traceability maps attribute failures to specific requirements, enabling targeted clause-level repairs. VeriSpecGen achieve 86.6% on VERINA SpecGen task using Claude Opus 4.5, improving over baselines by up to 31.8 points across different model families and scales. Beyond inference-time gains, we generate 343K training examples from VeriSpecGen refinement trajectories and demonstrate that training on these trajectories substantially improves specification synthesis by 62-106% relative and transfers gains to general reasoning abilities.
Learning Adaptive LLM Decoding
Mar 10, 2026Decoding from large language models (LLMs) typically relies on fixed sampling hyperparameters (e.g., temperature, top-p), despite substantial variation in task difficulty and uncertainty across prompts and individual decoding steps. We propose to learn adaptive decoding policies that dynamically select sampling strategies at inference time, conditioned on available compute resources. Rather than fine-tuning the language model itself, we introduce lightweight decoding adapters trained with reinforcement learning and verifiable terminal rewards (e.g. correctness on math and coding tasks). At the sequence level, we frame decoding as a contextual bandit problem: a policy selects a decoding strategy (e.g. greedy, top-k, min-p) for each prompt, conditioned on the prompt embedding and a parallel sampling budget. At the token level, we model decoding as a partially observable Markov decision process (POMDP), where a policy selects sampling actions at each token step based on internal model features and the remaining token budget. Experiments on the MATH and CodeContests benchmarks show that the learned adapters improve the accuracy-budget tradeoff: on MATH, the token-level adapter improves Pass@1 accuracy by up to 10.2% over the best static baseline under a fixed token budget, while the sequence-level adapter yields 2-3% gains under fixed parallel sampling. Ablation analyses support the contribution of both sequence- and token-level adaptation.
BreathNet: Generalizable Audio Deepfake Detection via Breath-Cue-Guided Feature Refinement
Feb 14, 2026As deepfake audio becomes more realistic and diverse, developing generalizable countermeasure systems has become crucial. Existing detection methods primarily depend on XLS-R front-end features to improve generalization. Nonetheless, their performance remains limited, partly due to insufficient attention to fine-grained information, such as physiological cues or frequency-domain features. In this paper, we propose BreathNet, a novel audio deepfake detection framework that integrates fine-grained breath information to improve generalization. Specifically, we design BreathFiLM, a feature-wise linear modulation mechanism that selectively amplifies temporal representations based on the presence of breathing sounds. BreathFiLM is trained jointly with the XLS-R extractor, in turn encouraging the extractor to learn and encode breath-related cues into the temporal features. Then, we use the frequency front-end to extract spectral features, which are then fused with temporal features to provide complementary information introduced by vocoders or compression artifacts. Additionally, we propose a group of feature losses comprising Positive-only Supervised Contrastive Loss (PSCL), center loss, and contrast loss. These losses jointly enhance the discriminative ability, encouraging the model to separate bona fide and deepfake samples more effectively in the feature space. Extensive experiments on five benchmark datasets demonstrate state-of-the-art (SOTA) performance. Using the ASVspoof 2019 LA training set, our method attains 1.99% average EER across four related eval benchmarks, with particularly strong performance on the In-the-Wild dataset, where it achieves 4.70% EER. Moreover, under the ASVspoof5 evaluation protocol, our method achieves an EER of 4.94% on this latest benchmark.
VERINA: Benchmarking Verifiable Code Generation
May 29, 2025Large language models (LLMs) are increasingly integrated in software development, but ensuring correctness in LLM-generated code remains challenging and often requires costly manual review. Verifiable code generation -- jointly generating code, specifications, and proofs of code-specification alignment -- offers a promising path to address this limitation and further unleash LLMs' benefits in coding. Yet, there exists a significant gap in evaluation: current benchmarks often lack support for end-to-end verifiable code generation. In this paper, we introduce Verina (Verifiable Code Generation Arena), a high-quality benchmark enabling a comprehensive and modular evaluation of code, specification, and proof generation as well as their compositions. Verina consists of 189 manually curated coding tasks in Lean, with detailed problem descriptions, reference implementations, formal specifications, and extensive test suites. Our extensive evaluation of state-of-the-art LLMs reveals significant challenges in verifiable code generation, especially in proof generation, underscoring the need for improving LLM-based theorem provers in verification domains. The best model, OpenAI o4-mini, generates only 61.4% correct code, 51.0% sound and complete specifications, and 3.6% successful proofs, with one trial per task. We hope Verina will catalyze progress in verifiable code generation by providing a rigorous and comprehensive benchmark. We release our dataset on https://huggingface.co/datasets/sunblaze-ucb/verina and our evaluation code on https://github.com/sunblaze-ucb/verina.
AgentXploit: End-to-End Redteaming of Black-Box AI Agents
May 09, 2025



The strong planning and reasoning capabilities of Large Language Models (LLMs) have fostered the development of agent-based systems capable of leveraging external tools and interacting with increasingly complex environments. However, these powerful features also introduce a critical security risk: indirect prompt injection, a sophisticated attack vector that compromises the core of these agents, the LLM, by manipulating contextual information rather than direct user prompts. In this work, we propose a generic black-box fuzzing framework, AgentXploit, designed to automatically discover and exploit indirect prompt injection vulnerabilities across diverse LLM agents. Our approach starts by constructing a high-quality initial seed corpus, then employs a seed selection algorithm based on Monte Carlo Tree Search (MCTS) to iteratively refine inputs, thereby maximizing the likelihood of uncovering agent weaknesses. We evaluate AgentXploit on two public benchmarks, AgentDojo and VWA-adv, where it achieves 71% and 70% success rates against agents based on o3-mini and GPT-4o, respectively, nearly doubling the performance of baseline attacks. Moreover, AgentXploit exhibits strong transferability across unseen tasks and internal LLMs, as well as promising results against defenses. Beyond benchmark evaluations, we apply our attacks in real-world environments, successfully misleading agents to navigate to arbitrary URLs, including malicious sites.
BadSQA: Stealthy Backdoor Attacks Using Presence Events as Triggers in Non-Intrusive Speech Quality Assessment
Sep 04, 2023



Non-Intrusive speech quality assessment (NISQA) has gained significant attention for predicting the mean opinion score (MOS) of speech without requiring the reference speech. In practical NISQA scenarios, untrusted third-party resources are often employed during deep neural network training to reduce costs. However, it would introduce a potential security vulnerability as specially designed untrusted resources can launch backdoor attacks against NISQA systems. Existing backdoor attacks primarily focus on classification tasks and are not directly applicable to NISQA which is a regression task. In this paper, we propose a novel backdoor attack on NISQA tasks, leveraging presence events as triggers to achieving highly stealthy attacks. To evaluate the effectiveness of our proposed approach, we conducted experiments on four benchmark datasets and employed two state-of-the-art NISQA models. The results demonstrate that the proposed backdoor attack achieved an average attack success rate of up to 99% with a poisoning rate of only 3%.
Evil Operation: Breaking Speaker Recognition with PaddingBack
Aug 08, 2023



Machine Learning as a Service (MLaaS) has gained popularity due to advancements in machine learning. However, untrusted third-party platforms have raised concerns about AI security, particularly in backdoor attacks. Recent research has shown that speech backdoors can utilize transformations as triggers, similar to image backdoors. However, human ears easily detect these transformations, leading to suspicion. In this paper, we introduce PaddingBack, an inaudible backdoor attack that utilizes malicious operations to make poisoned samples indistinguishable from clean ones. Instead of using external perturbations as triggers, we exploit the widely used speech signal operation, padding, to break speaker recognition systems. Our experimental results demonstrate the effectiveness of the proposed approach, achieving a significantly high attack success rate while maintaining a high rate of benign accuracy. Furthermore, PaddingBack demonstrates the ability to resist defense methods while maintaining its stealthiness against human perception. The results of the stealthiness experiment have been made available at https://nbufabio25.github.io/paddingback/.
Fake the Real: Backdoor Attack on Deep Speech Classification via Voice Conversion
Jun 28, 2023Deep speech classification has achieved tremendous success and greatly promoted the emergence of many real-world applications. However, backdoor attacks present a new security threat to it, particularly with untrustworthy third-party platforms, as pre-defined triggers set by the attacker can activate the backdoor. Most of the triggers in existing speech backdoor attacks are sample-agnostic, and even if the triggers are designed to be unnoticeable, they can still be audible. This work explores a backdoor attack that utilizes sample-specific triggers based on voice conversion. Specifically, we adopt a pre-trained voice conversion model to generate the trigger, ensuring that the poisoned samples does not introduce any additional audible noise. Extensive experiments on two speech classification tasks demonstrate the effectiveness of our attack. Furthermore, we analyzed the specific scenarios that activated the proposed backdoor and verified its resistance against fine-tuning.
Residual-Guided Non-Intrusive Speech Quality Assessment
Mar 22, 2022
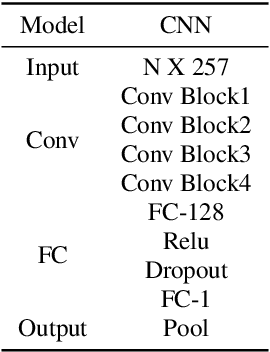
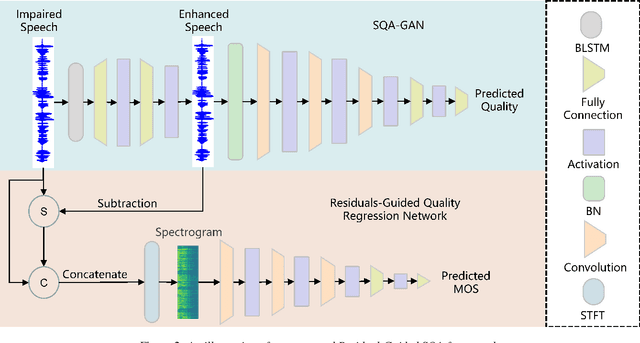

This paper proposes an approach to improve Non-Intrusive speech quality assessment(NI-SQA) based on the residuals between impaired speech and enhanced speech. The difficulty in our task is particularly lack of information, for which the corresponding reference speech is absent. We generate an enhanced speech on the impaired speech to compensate for the absence of the reference audio, then pair the information of residuals with the impaired speech. Compared to feeding the impaired speech directly into the model, residuals could bring some extra helpful information from the contrast in enhancement. The human ear is sensitive to certain noises but different to deep learning model. Causing the Mean Opinion Score(MOS) the model predicted is not enough to fit our subjective sensitive well and causes deviation. These residuals have a close relationship to reference speech and then improve the ability of the deep learning models to predict MOS. During the training phase, experimental results demonstrate that paired with residuals can quickly obtain better evaluation indicators under the same conditions. Furthermore, our final results improved 31.3 percent and 14.1 percent, respectively, in PLCC and RMSE.
Sensor Sampling Trade-Offs for Air Quality Monitoring With Low-Cost Sensors
Dec 14, 2021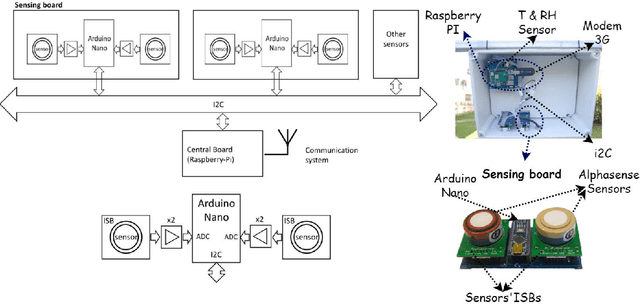
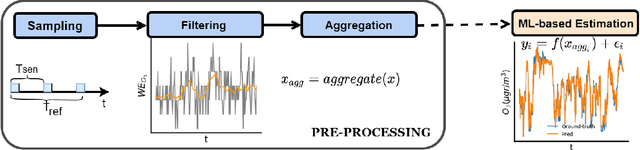
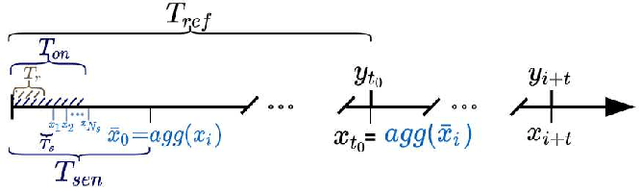
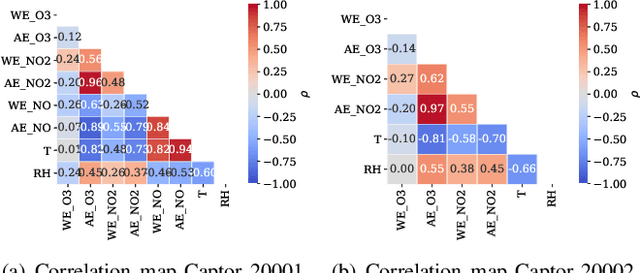
The calibration of low-cost sensors using machine learning techniques is a methodology widely used nowadays. Although many challenges remain to be solved in the deployment of low-cost sensors for air quality monitoring, low-cost sensors have been shown to be useful in conjunction with high-precision instrumentation. Thus, most research is focused on the application of different calibration techniques using machine learning. Nevertheless, the successful application of these models depends on the quality of the data obtained by the sensors, and very little attention has been paid to the whole data gathering process, from sensor sampling and data pre-processing, to the calibration of the sensor itself. In this article, we show the main sensor sampling parameters, with their corresponding impact on the quality of the resulting machine learning-based sensor calibration and their impact on energy consumption, thus showing the existing trade-offs. Finally, the results on an experimental node show the impact of the data sampling strategy in the calibration of tropospheric ozone, nitrogen dioxide and nitrogen monoxide low-cost sensors. Specifically, we show how a sampling strategy that minimizes the duty cycle of the sensing subsystem can reduce power consumption while maintaining data quality.