 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Post-Training Shapes Biological Reasoning Models
Jun 15, 2026Scientific reasoning models for biology combine language models with foundation models trained on multimodal biological data, including DNA, RNA, and proteins. These models are built through post-training, yet how each stage shapes reasoning and generalization remains poorly understood. We study when post-training improves performance and when it induces over-specialization. Across genomics, transcriptomics, and proteins, we train and evaluate more than 100 biological reasoning models under controlled variation in backbone, continued pre-training (CPT), supervised fine-tuning (SFT), and reinforcement learning (RL), measuring both in-domain (ID) and out-of-domain (OOD) performance. We find that each post-training stage reshapes generalization in a distinct way rather than contributing uniform gains. CPT improves downstream performance by aligning models with biological language. SFT consistently increases ID performance but causes OOD performance to peak early and decline as models fit the training distribution. RL, when applied to strong SFT checkpoints with aligned rewards, improves OOD performance and partially recovers generalization. These results show that biological reasoning does not improve monotonically with additional supervision or compute. Instead, performance depends on how training stages are composed. Under fixed post-training budgets, the strongest ID-OOD trade-off comes from brief SFT, larger RL allocations, and asymmetric adaptation capacity across stages.
Self-Improving Language Models with Bidirectional Evolutionary Search
May 27, 2026Search has been proposed as an effective method for self-improving language models and agentic systems, both for post-training sample generation and for inference. However, widely used methods such as best-of-N sampling and tree search face two fundamental limitations: they are guided by sparse verification signals, and they construct candidates primarily through autoregressive expansion, restricting exploration to regions with substantial model probability mass. To address these, we propose Bidirectional Evolutionary Search (BES), a search framework that couples forward candidate evolution with backward goal decomposition. In the forward search, BES augments standard expansion with evolution operators that recombine partial trajectories to generate candidates that are difficult to obtain from a single model rollout. In the backward search, BES recursively decomposes the original task into checkable subgoals, producing dense intermediate feedback that guides forward search. We provide theoretical motivation showing that candidates generated by expansion-only search are confined to a narrow entropy shell while evolutionary operators can escape it, and that backward search can exponentially reduce the number of required samples to find a correct answer. Experiments show that on challenging post-training tasks where mainstream post-training algorithms fail to improve, BES enables consistent gains, and on three open problem solving benchmarks at inference time, BES outperforms existing open-source frameworks in both average and best-case performance. Code and trained models are available at https://github.com/Embodied-Minds-Lab/BES.
Evaluating Relational Reasoning in LLMs with REL
Apr 14, 2026Relational reasoning is the ability to infer relations that jointly bind multiple entities, attributes, or variables. This ability is central to scientific reasoning, but existing evaluations of relational reasoning in large language models often focus on structured inputs such as tables, graphs, or synthetic tasks, and do not isolate the difficulty introduced by higher-arity relational binding. We study this problem through the lens of Relational Complexity (RC), which we define as the minimum number of independent entities or operands that must be simultaneously bound to apply a relation. RC provides a principled way to vary reasoning difficulty while controlling for confounders such as input size, vocabulary, and representational choices. Building on RC, we introduce REL, a generative benchmark framework spanning algebra, chemistry, and biology that varies RC within each domain. Across frontier LLMs, performance degrades consistently and monotonically as RC increases, even when the total number of entities is held fixed. This failure mode persists with increased test-time compute and in-context learning, suggesting a limitation tied to the arity of the required relational binding rather than to insufficient inference steps or lack of exposure to examples. Our results identify a regime of higher-arity reasoning in which current models struggle, and motivate re-examining benchmarks through the lens of relational complexity.
Matching Features, Not Tokens: Energy-Based Fine-Tuning of Language Models
Mar 12, 2026Cross-entropy (CE) training provides dense and scalable supervision for language models, but it optimizes next-token prediction under teacher forcing rather than sequence-level behavior under model rollouts. We introduce a feature-matching objective for language-model fine-tuning that targets sequence-level statistics of the completion distribution, providing dense semantic feedback without requiring a task-specific verifier or preference model. To optimize this objective efficiently, we propose energy-based fine-tuning (EBFT), which uses strided block-parallel sampling to generate multiple rollouts from nested prefixes concurrently, batches feature extraction over these rollouts, and uses the resulting embeddings to perform an on-policy policy-gradient update. We present a theoretical perspective connecting EBFT to KL-regularized feature-matching and energy-based modeling. Empirically, across Q&A coding, unstructured coding, and translation, EBFT matches RLVR and outperforms SFT on downstream accuracy while achieving a lower validation cross-entropy than both methods.
The Role of Sparsity for Length Generalization in Transformers
Feb 24, 2025



Training large language models to predict beyond their training context lengths has drawn much attention in recent years, yet the principles driving such behavior of length generalization remain underexplored. We propose a new theoretical framework to study length generalization for the next-token prediction task, as performed by decoder-only transformers. Conceptually, we show that length generalization occurs as long as each predicted token depends on a small (fixed) number of previous tokens. We formalize such tasks via a notion we call $k$-sparse planted correlation distributions, and show that an idealized model of transformers which generalize attention heads successfully length-generalize on such tasks. As a bonus, our theoretical model justifies certain techniques to modify positional embeddings which have been introduced to improve length generalization, such as position coupling. We support our theoretical results with experiments on synthetic tasks and natural language, which confirm that a key factor driving length generalization is a ``sparse'' dependency structure of each token on the previous ones. Inspired by our theory, we introduce Predictive Position Coupling, which trains the transformer to predict the position IDs used in a positional coupling approach. Predictive Position Coupling thereby allows us to broaden the array of tasks to which position coupling can successfully be applied to achieve length generalization.
Mixture of Parrots: Experts improve memorization more than reasoning
Oct 24, 2024



The Mixture-of-Experts (MoE) architecture enables a significant increase in the total number of model parameters with minimal computational overhead. However, it is not clear what performance tradeoffs, if any, exist between MoEs and standard dense transformers. In this paper, we show that as we increase the number of experts (while fixing the number of active parameters), the memorization performance consistently increases while the reasoning capabilities saturate. We begin by analyzing the theoretical limitations of MoEs at reasoning. We prove that there exist graph problems that cannot be solved by any number of experts of a certain width; however, the same task can be easily solved by a dense model with a slightly larger width. On the other hand, we find that on memory-intensive tasks, MoEs can effectively leverage a small number of active parameters with a large number of experts to memorize the data. We empirically validate these findings on synthetic graph problems and memory-intensive closed book retrieval tasks. Lastly, we pre-train a series of MoEs and dense transformers and evaluate them on commonly used benchmarks in math and natural language. We find that increasing the number of experts helps solve knowledge-intensive tasks, but fails to yield the same benefits for reasoning tasks.
Multi-Agent Reinforcement Learning from Human Feedback: Data Coverage and Algorithmic Techniques
Sep 04, 2024



We initiate the study of Multi-Agent Reinforcement Learning from Human Feedback (MARLHF), exploring both theoretical foundations and empirical validations. We define the task as identifying Nash equilibrium from a preference-only offline dataset in general-sum games, a problem marked by the challenge of sparse feedback signals. Our theory establishes the upper complexity bounds for Nash Equilibrium in effective MARLHF, demonstrating that single-policy coverage is inadequate and highlighting the importance of unilateral dataset coverage. These theoretical insights are verified through comprehensive experiments. To enhance the practical performance, we further introduce two algorithmic techniques. (1) We propose a Mean Squared Error (MSE) regularization along the time axis to achieve a more uniform reward distribution and improve reward learning outcomes. (2) We utilize imitation learning to approximate the reference policy, ensuring stability and effectiveness in training. Our findings underscore the multifaceted approach required for MARLHF, paving the way for effective preference-based multi-agent systems.
Eliminating Position Bias of Language Models: A Mechanistic Approach
Jul 01, 2024



Position bias has proven to be a prevalent issue of modern language models (LMs), where the models prioritize content based on its position within the given context. This bias often leads to unexpected model failures and hurts performance, robustness, and reliability across various applications. Our mechanistic analysis attributes the position bias to two components employed in nearly all state-of-the-art LMs: causal attention and relative positional encodings. Specifically, we find that causal attention generally causes models to favor distant content, while relative positional encodings like RoPE prefer nearby ones based on the analysis of retrieval-augmented question answering (QA). Further, our empirical study on object detection reveals that position bias is also present in vision-language models (VLMs). Based on the above analyses, we propose to ELIMINATE position bias caused by different input segment orders (e.g., options in LM-as-a-judge, retrieved documents in QA) in a TRAINING-FREE ZERO-SHOT manner. Our method changes the causal attention to bidirectional attention between segments and utilizes model attention values to decide the relative orders of segments instead of using the order provided in input prompts, therefore enabling Position-INvariant inferencE (PINE) at the segment level. By eliminating position bias, models achieve better performance and reliability in downstream tasks where position bias widely exists, such as LM-as-a-judge and retrieval-augmented QA. Notably, PINE is especially useful when adapting LMs for evaluating reasoning pairs: it consistently provides 8 to 10 percentage points performance gains in most cases, and makes Llama-3-70B-Instruct perform even better than GPT-4-0125-preview on the RewardBench reasoning subset.
Transcendence: Generative Models Can Outperform The Experts That Train Them
Jun 17, 2024


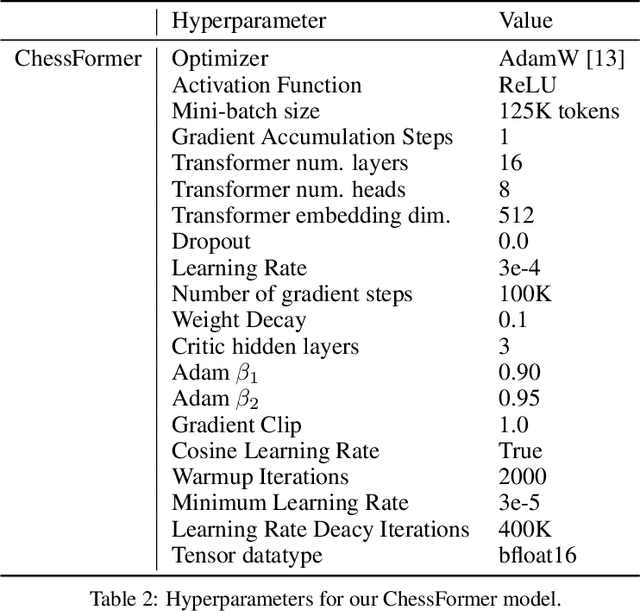
Generative models are trained with the simple objective of imitating the conditional probability distribution induced by the data they are trained on. Therefore, when trained on data generated by humans, we may not expect the artificial model to outperform the humans on their original objectives. In this work, we study the phenomenon of transcendence: when a generative model achieves capabilities that surpass the abilities of the experts generating its data. We demonstrate transcendence by training an autoregressive transformer to play chess from game transcripts, and show that the trained model can sometimes achieve better performance than all players in the dataset. We theoretically prove that transcendence is enabled by low-temperature sampling, and rigorously assess this experimentally. Finally, we discuss other sources of transcendence, laying the groundwork for future investigation of this phenomenon in a broader setting.
Scaling Laws in Linear Regression: Compute, Parameters, and Data
Jun 12, 2024



Empirically, large-scale deep learning models often satisfy a neural scaling law: the test error of the trained model improves polynomially as the model size and data size grow. However, conventional wisdom suggests the test error consists of approximation, bias, and variance errors, where the variance error increases with model size. This disagrees with the general form of neural scaling laws, which predict that increasing model size monotonically improves performance. We study the theory of scaling laws in an infinite dimensional linear regression setup. Specifically, we consider a model with $M$ parameters as a linear function of sketched covariates. The model is trained by one-pass stochastic gradient descent (SGD) using $N$ data. Assuming the optimal parameter satisfies a Gaussian prior and the data covariance matrix has a power-law spectrum of degree $a>1$, we show that the reducible part of the test error is $\Theta(M^{-(a-1)} + N^{-(a-1)/a})$. The variance error, which increases with $M$, is dominated by the other errors due to the implicit regularization of SGD, thus disappearing from the bound. Our theory is consistent with the empirical neural scaling laws and verified by numerical simulation.