 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntent-aligned Formal Specification Synthesis via Traceable Refinement
Apr 12, 2026Large language models are increasingly used to generate code from natural language, but ensuring correctness remains challenging. Formal verification offers a principled way to obtain such guarantees by proving that a program satisfies a formal specification. However, specifications are frequently missing in real-world codebases, and writing high-quality specifications remains expensive and expertise-intensive. We present VeriSpecGen, a traceable refinement framework that synthesizes intent-aligned specifications in Lean through requirement-level attribution and localized repair. VeriSpecGen decomposes natural language into atomic requirements and generates requirement-targeted tests with explicit traceability maps to validate generated specifications. When validation fails, traceability maps attribute failures to specific requirements, enabling targeted clause-level repairs. VeriSpecGen achieve 86.6% on VERINA SpecGen task using Claude Opus 4.5, improving over baselines by up to 31.8 points across different model families and scales. Beyond inference-time gains, we generate 343K training examples from VeriSpecGen refinement trajectories and demonstrate that training on these trajectories substantially improves specification synthesis by 62-106% relative and transfers gains to general reasoning abilities.
Learning Adaptive LLM Decoding
Mar 10, 2026Decoding from large language models (LLMs) typically relies on fixed sampling hyperparameters (e.g., temperature, top-p), despite substantial variation in task difficulty and uncertainty across prompts and individual decoding steps. We propose to learn adaptive decoding policies that dynamically select sampling strategies at inference time, conditioned on available compute resources. Rather than fine-tuning the language model itself, we introduce lightweight decoding adapters trained with reinforcement learning and verifiable terminal rewards (e.g. correctness on math and coding tasks). At the sequence level, we frame decoding as a contextual bandit problem: a policy selects a decoding strategy (e.g. greedy, top-k, min-p) for each prompt, conditioned on the prompt embedding and a parallel sampling budget. At the token level, we model decoding as a partially observable Markov decision process (POMDP), where a policy selects sampling actions at each token step based on internal model features and the remaining token budget. Experiments on the MATH and CodeContests benchmarks show that the learned adapters improve the accuracy-budget tradeoff: on MATH, the token-level adapter improves Pass@1 accuracy by up to 10.2% over the best static baseline under a fixed token budget, while the sequence-level adapter yields 2-3% gains under fixed parallel sampling. Ablation analyses support the contribution of both sequence- and token-level adaptation.
Active Inference as a Model of Agency
Jan 23, 2024



Is there a canonical way to think of agency beyond reward maximisation? In this paper, we show that any type of behaviour complying with physically sound assumptions about how macroscopic biological agents interact with the world canonically integrates exploration and exploitation in the sense of minimising risk and ambiguity about states of the world. This description, known as active inference, refines the free energy principle, a popular descriptive framework for action and perception originating in neuroscience. Active inference provides a normative Bayesian framework to simulate and model agency that is widely used in behavioural neuroscience, reinforcement learning (RL) and robotics. The usefulness of active inference for RL is three-fold. \emph{a}) Active inference provides a principled solution to the exploration-exploitation dilemma that usefully simulates biological agency. \emph{b}) It provides an explainable recipe to simulate behaviour, whence behaviour follows as an explainable mixture of exploration and exploitation under a generative world model, and all differences in behaviour are explicit in differences in world model. \emph{c}) This framework is universal in the sense that it is theoretically possible to rewrite any RL algorithm conforming to the descriptive assumptions of active inference as an active inference algorithm. Thus, active inference can be used as a tool to uncover and compare the commitments and assumptions of more specific models of agency.
Learning What and Where to Draw
Oct 08, 2016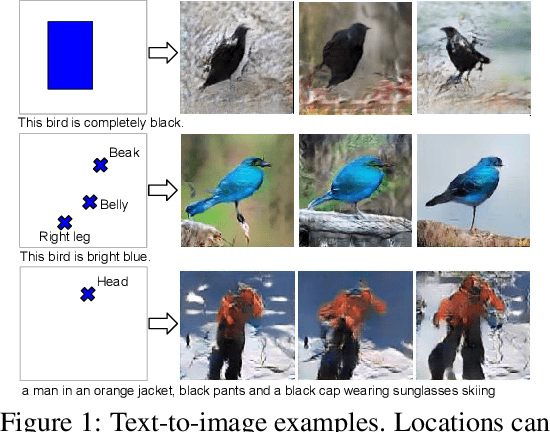
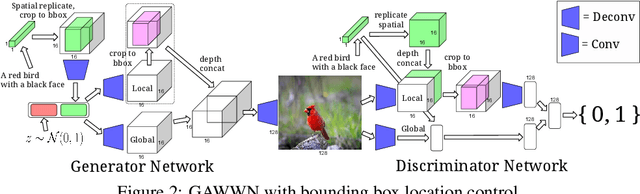
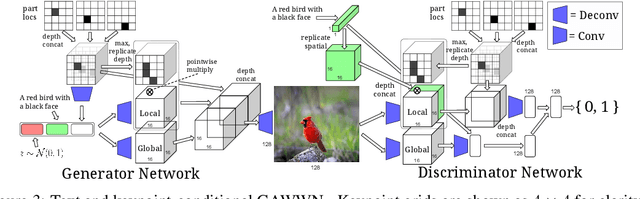
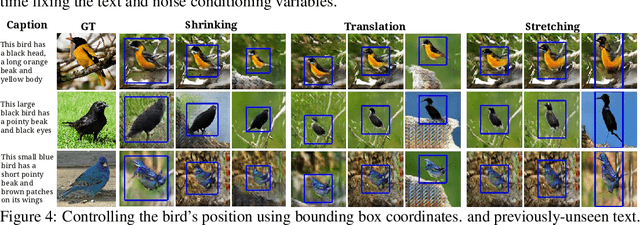
Generative Adversarial Networks (GANs) have recently demonstrated the capability to synthesize compelling real-world images, such as room interiors, album covers, manga, faces, birds, and flowers. While existing models can synthesize images based on global constraints such as a class label or caption, they do not provide control over pose or object location. We propose a new model, the Generative Adversarial What-Where Network (GAWWN), that synthesizes images given instructions describing what content to draw in which location. We show high-quality 128 x 128 image synthesis on the Caltech-UCSD Birds dataset, conditioned on both informal text descriptions and also object location. Our system exposes control over both the bounding box around the bird and its constituent parts. By modeling the conditional distributions over part locations, our system also enables conditioning on arbitrary subsets of parts (e.g. only the beak and tail), yielding an efficient interface for picking part locations. We also show preliminary results on the more challenging domain of text- and location-controllable synthesis of images of human actions on the MPII Human Pose dataset.