 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOffline Reinforcement Learning for Rotation Profile Control in Tokamaks
May 07, 2026Tokamaks remain leading candidates for achieving practical fusion energy, yet many important control problems inside these devices are still difficult or unsolved. One such challenge is controlling the plasma rotation profile, which strongly influences stability, confinement, and transport. While the average rotation can be controlled, controlling the full profile is challenging due to high dimensionality, response to multiple actuators and dependence on plasma condition. Learning-based control methods, such as reinforcement learning (RL), provide a potential solution to this challenging problem with ability to model complex interactions leading to effective multi-input multi-output control. However, learning such policies is challenging due to the lack of accurate simulators that can model the rotation profile dynamics. In this work, we investigate the use of offline RL and offline model-based RL algorithms for rotation profile control, training them solely on historical data from the DIII-D tokamak. Our final method uses probabilistic models of plasma dynamics to generate rollouts for RL training. We deploy this policy on the DIII-D Tokamak and observe promising real-world results. We conclude by highlighting key challenges and insights from training and deploying an RL policy on a complex physical device while using only limited past data.
Occupancy Reward Shaping: Improving Credit Assignment for Offline Goal-Conditioned Reinforcement Learning
Apr 22, 2026The temporal lag between actions and their long-term consequences makes credit assignment a challenge when learning goal-directed behaviors from data. Generative world models capture the distribution of future states an agent may visit, indicating that they have captured temporal information. How can that temporal information be extracted to perform credit assignment? In this paper, we formalize how the temporal information stored in world models encodes the underlying geometry of the world. Leveraging optimal transport, we extract this geometry from a learned model of the occupancy measure into a reward function that captures goal-reaching information. Our resulting method, Occupancy Reward Shaping, largely mitigates the problem of credit assignment in sparse reward settings. ORS provably does not alter the optimal policy, yet empirically improves performance by 2.2x across 13 diverse long-horizon locomotion and manipulation tasks. Moreover, we demonstrate the effectiveness of ORS in the real world for controlling nuclear fusion on 3 Tokamak control tasks. Code: https://github.com/aravindvenu7/occupancy_reward_shaping; Website: https://aravindvenu7.github.io/website/ors/
Cost-Aware Diffusion Active Search
Feb 23, 2026Active search for recovering objects of interest through online, adaptive decision making with autonomous agents requires trading off exploration of unknown environments with exploitation of prior observations in the search space. Prior work has proposed information gain and Thompson sampling based myopic, greedy approaches for agents to actively decide query or search locations when the number of targets is unknown. Decision making algorithms in such partially observable environments have also shown that agents capable of lookahead over a finite horizon outperform myopic policies for active search. Unfortunately, lookahead algorithms typically rely on building a computationally expensive search tree that is simulated and updated based on the agent's observations and a model of the environment dynamics. Instead, in this work, we leverage the sequence modeling abilities of diffusion models to sample lookahead action sequences that balance the exploration-exploitation trade-off for active search without building an exhaustive search tree. We identify the optimism bias in prior diffusion based reinforcement learning approaches when applied to the active search setting and propose mitigating solutions for efficient cost-aware decision making with both single and multi-agent teams. Our proposed algorithm outperforms standard baselines in offline reinforcement learning in terms of full recovery rate and is computationally more efficient than tree search in cost-aware active decision making.
Retrospective In-Context Learning for Temporal Credit Assignment with Large Language Models
Feb 19, 2026Learning from self-sampled data and sparse environmental feedback remains a fundamental challenge in training self-evolving agents. Temporal credit assignment mitigates this issue by transforming sparse feedback into dense supervision signals. However, previous approaches typically depend on learning task-specific value functions for credit assignment, which suffer from poor sample efficiency and limited generalization. In this work, we propose to leverage pretrained knowledge from large language models (LLMs) to transform sparse rewards into dense training signals (i.e., the advantage function) through retrospective in-context learning (RICL). We further propose an online learning framework, RICOL, which iteratively refines the policy based on the credit assignment results from RICL. We empirically demonstrate that RICL can accurately estimate the advantage function with limited samples and effectively identify critical states in the environment for temporal credit assignment. Extended evaluation on four BabyAI scenarios show that RICOL achieves comparable convergent performance with traditional online RL algorithms with significantly higher sample efficiency. Our findings highlight the potential of leveraging LLMs for temporal credit assignment, paving the way for more sample-efficient and generalizable RL paradigms.
Maximum Likelihood Reinforcement Learning
Feb 02, 2026Reinforcement learning is the method of choice to train models in sampling-based setups with binary outcome feedback, such as navigation, code generation, and mathematical problem solving. In such settings, models implicitly induce a likelihood over correct rollouts. However, we observe that reinforcement learning does not maximize this likelihood, and instead optimizes only a lower-order approximation. Inspired by this observation, we introduce Maximum Likelihood Reinforcement Learning (MaxRL), a sampling-based framework to approximate maximum likelihood using reinforcement learning techniques. MaxRL addresses the challenges of non-differentiable sampling by defining a compute-indexed family of sample-based objectives that interpolate between standard reinforcement learning and exact maximum likelihood as additional sampling compute is allocated. The resulting objectives admit a simple, unbiased policy-gradient estimator and converge to maximum likelihood optimization in the infinite-compute limit. Empirically, we show that MaxRL Pareto-dominates existing methods in all models and tasks we tested, achieving up to 20x test-time scaling efficiency gains compared to its GRPO-trained counterpart. We also observe MaxRL to scale better with additional data and compute. Our results suggest MaxRL is a promising framework for scaling RL training in correctness based settings.
Continual Policy Distillation from Distributed Reinforcement Learning Teachers
Jan 30, 2026Continual Reinforcement Learning (CRL) aims to develop lifelong learning agents to continuously acquire knowledge across diverse tasks while mitigating catastrophic forgetting. This requires efficiently managing the stability-plasticity dilemma and leveraging prior experience to rapidly generalize to novel tasks. While various enhancement strategies for both aspects have been proposed, achieving scalable performance by directly applying RL to sequential task streams remains challenging. In this paper, we propose a novel teacher-student framework that decouples CRL into two independent processes: training single-task teacher models through distributed RL and continually distilling them into a central generalist model. This design is motivated by the observation that RL excels at solving single tasks, while policy distillation -- a relatively stable supervised learning process -- is well aligned with large foundation models and multi-task learning. Moreover, a mixture-of-experts (MoE) architecture and a replay-based approach are employed to enhance the plasticity and stability of the continual policy distillation process. Extensive experiments on the Meta-World benchmark demonstrate that our framework enables efficient continual RL, recovering over 85% of teacher performance while constraining task-wise forgetting to within 10%.
Latent Policy Steering with Embodiment-Agnostic Pretrained World Models
Jul 17, 2025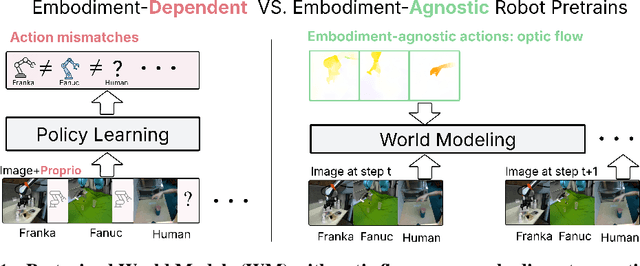
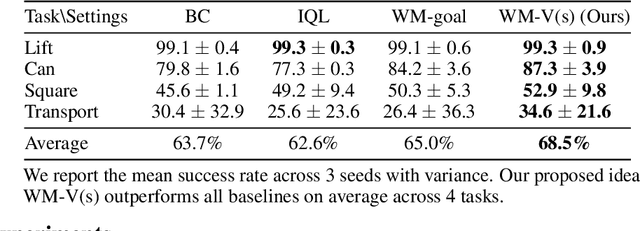

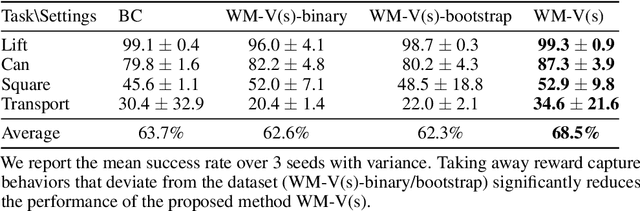
Learning visuomotor policies via imitation has proven effective across a wide range of robotic domains. However, the performance of these policies is heavily dependent on the number of training demonstrations, which requires expensive data collection in the real world. In this work, we aim to reduce data collection efforts when learning visuomotor robot policies by leveraging existing or cost-effective data from a wide range of embodiments, such as public robot datasets and the datasets of humans playing with objects (human data from play). Our approach leverages two key insights. First, we use optic flow as an embodiment-agnostic action representation to train a World Model (WM) across multi-embodiment datasets, and finetune it on a small amount of robot data from the target embodiment. Second, we develop a method, Latent Policy Steering (LPS), to improve the output of a behavior-cloned policy by searching in the latent space of the WM for better action sequences. In real world experiments, we observe significant improvements in the performance of policies trained with a small amount of data (over 50% relative improvement with 30 demonstrations and over 20% relative improvement with 50 demonstrations) by combining the policy with a WM pretrained on two thousand episodes sampled from the existing Open X-embodiment dataset across different robots or a cost-effective human dataset from play.
Multi-Timescale Dynamics Model Bayesian Optimization for Plasma Stabilization in Tokamaks
Jun 12, 2025Machine learning algorithms often struggle to control complex real-world systems. In the case of nuclear fusion, these challenges are exacerbated, as the dynamics are notoriously complex, data is poor, hardware is subject to failures, and experiments often affect dynamics beyond the experiment's duration. Existing tools like reinforcement learning, supervised learning, and Bayesian optimization address some of these challenges but fail to provide a comprehensive solution. To overcome these limitations, we present a multi-scale Bayesian optimization approach that integrates a high-frequency data-driven dynamics model with a low-frequency Gaussian process. By updating the Gaussian process between experiments, the method rapidly adapts to new data, refining the predictions of the less reliable dynamical model. We validate our approach by controlling tearing instabilities in the DIII-D nuclear fusion plant. Offline testing on historical data shows that our method significantly outperforms several baselines. Results on live experiments on the DIII-D tokamak, conducted under high-performance plasma scenarios prone to instabilities, shows a 50% success rate, marking a 117% improvement over historical outcomes.
Accelerating Diffusion Models in Offline RL via Reward-Aware Consistency Trajectory Distillation
Jun 09, 2025Although diffusion models have achieved strong results in decision-making tasks, their slow inference speed remains a key limitation. While the consistency model offers a potential solution, its applications to decision-making often struggle with suboptimal demonstrations or rely on complex concurrent training of multiple networks. In this work, we propose a novel approach to consistency distillation for offline reinforcement learning that directly incorporates reward optimization into the distillation process. Our method enables single-step generation while maintaining higher performance and simpler training. Empirical evaluations on the Gym MuJoCo benchmarks and long horizon planning demonstrate that our approach can achieve an 8.7% improvement over previous state-of-the-art while offering up to 142x speedup over diffusion counterparts in inference time.
Can Large Reasoning Models Self-Train?
May 27, 2025



Scaling the performance of large language models (LLMs) increasingly depends on methods that reduce reliance on human supervision. Reinforcement learning from automated verification offers an alternative, but it incurs scalability limitations due to dependency upon human-designed verifiers. Self-training, where the model's own judgment provides the supervisory signal, presents a compelling direction. We propose an online self-training reinforcement learning algorithm that leverages the model's self-consistency to infer correctness signals and train without any ground-truth supervision. We apply the algorithm to challenging mathematical reasoning tasks and show that it quickly reaches performance levels rivaling reinforcement-learning methods trained explicitly on gold-standard answers. Additionally, we analyze inherent limitations of the algorithm, highlighting how the self-generated proxy reward initially correlated with correctness can incentivize reward hacking, where confidently incorrect outputs are favored. Our results illustrate how self-supervised improvement can achieve significant performance gains without external labels, while also revealing its fundamental challenges.