 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Fine-grained Interpretability Evaluation Benchmark for Neural NLP
May 23, 2022
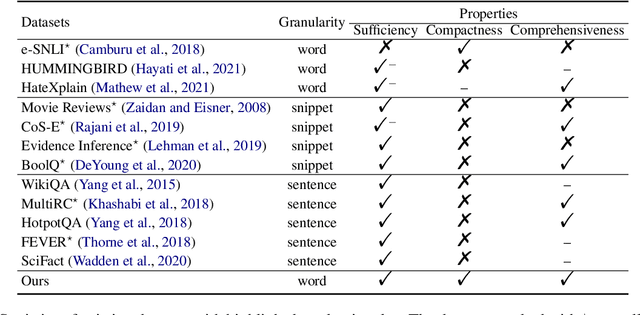
While there is increasing concern about the interpretability of neural models, the evaluation of interpretability remains an open problem, due to the lack of proper evaluation datasets and metrics. In this paper, we present a novel benchmark to evaluate the interpretability of both neural models and saliency methods. This benchmark covers three representative NLP tasks: sentiment analysis, textual similarity and reading comprehension, each provided with both English and Chinese annotated data. In order to precisely evaluate the interpretability, we provide token-level rationales that are carefully annotated to be sufficient, compact and comprehensive. We also design a new metric, i.e., the consistency between the rationales before and after perturbations, to uniformly evaluate the interpretability of models and saliency methods on different tasks. Based on this benchmark, we conduct experiments on three typical models with three saliency methods, and unveil their strengths and weakness in terms of interpretability. We will release this benchmark at \url{https://xyz} and hope it can facilitate the research in building trustworthy systems.
ERNIE-Search: Bridging Cross-Encoder with Dual-Encoder via Self On-the-fly Distillation for Dense Passage Retrieval
May 18, 2022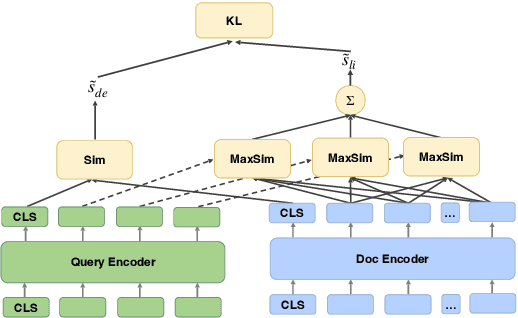

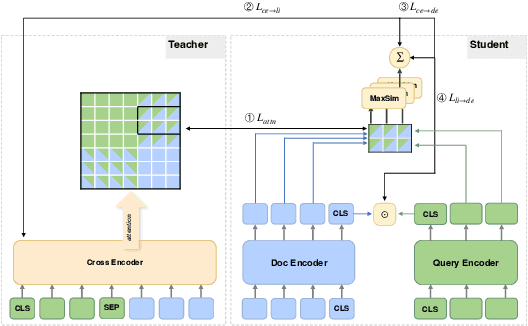
Neural retrievers based on pre-trained language models (PLMs), such as dual-encoders, have achieved promising performance on the task of open-domain question answering (QA). Their effectiveness can further reach new state-of-the-arts by incorporating cross-architecture knowledge distillation. However, most of the existing studies just directly apply conventional distillation methods. They fail to consider the particular situation where the teacher and student have different structures. In this paper, we propose a novel distillation method that significantly advances cross-architecture distillation for dual-encoders. Our method 1) introduces a self on-the-fly distillation method that can effectively distill late interaction (i.e., ColBERT) to vanilla dual-encoder, and 2) incorporates a cascade distillation process to further improve the performance with a cross-encoder teacher. Extensive experiments are conducted to validate that our proposed solution outperforms strong baselines and establish a new state-of-the-art on open-domain QA benchmarks.
HelixADMET: a robust and endpoint extensible ADMET system incorporating self-supervised knowledge transfer
May 17, 2022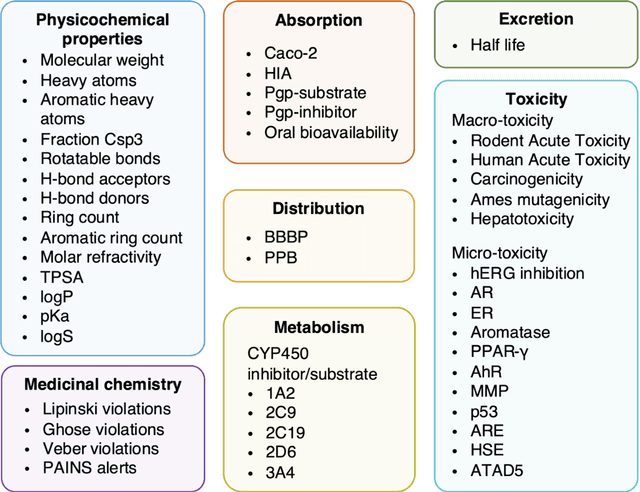
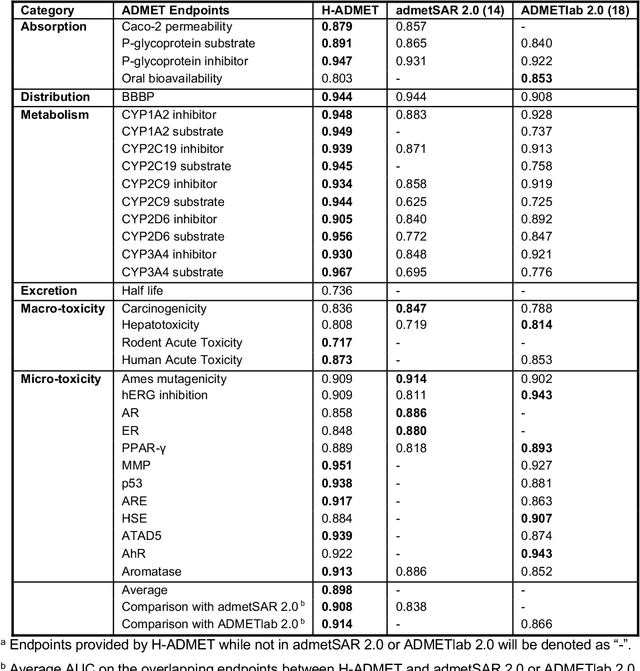
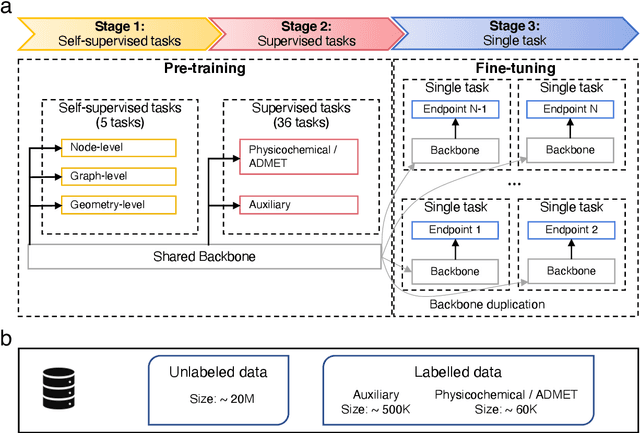
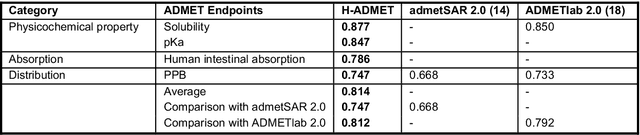
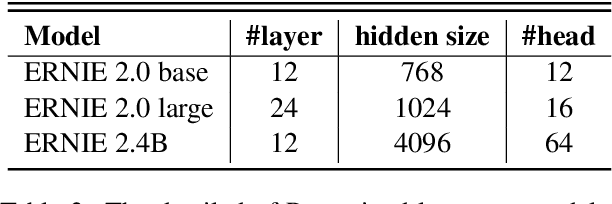
Accurate ADMET (an abbreviation for "absorption, distribution, metabolism, excretion, and toxicity") predictions can efficiently screen out undesirable drug candidates in the early stage of drug discovery. In recent years, multiple comprehensive ADMET systems that adopt advanced machine learning models have been developed, providing services to estimate multiple endpoints. However, those ADMET systems usually suffer from weak extrapolation ability. First, due to the lack of labelled data for each endpoint, typical machine learning models perform frail for the molecules with unobserved scaffolds. Second, most systems only provide fixed built-in endpoints and cannot be customised to satisfy various research requirements. To this end, we develop a robust and endpoint extensible ADMET system, HelixADMET (H-ADMET). H-ADMET incorporates the concept of self-supervised learning to produce a robust pre-trained model. The model is then fine-tuned with a multi-task and multi-stage framework to transfer knowledge between ADMET endpoints, auxiliary tasks, and self-supervised tasks. Our results demonstrate that H-ADMET achieves an overall improvement of 4%, compared with existing ADMET systems on comparable endpoints. Additionally, the pre-trained model provided by H-ADMET can be fine-tuned to generate new and customised ADMET endpoints, meeting various demands of drug research and development requirements.
A Thorough Examination on Zero-shot Dense Retrieval
Apr 27, 2022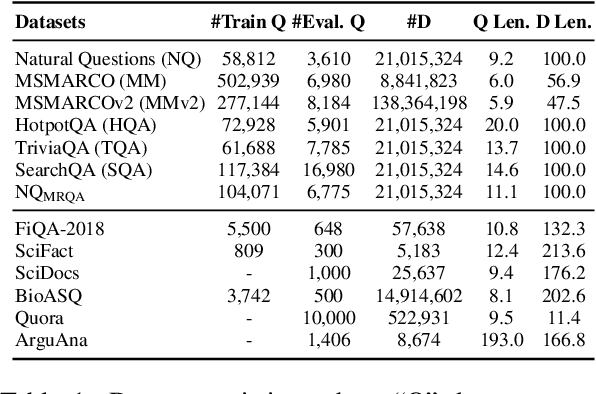
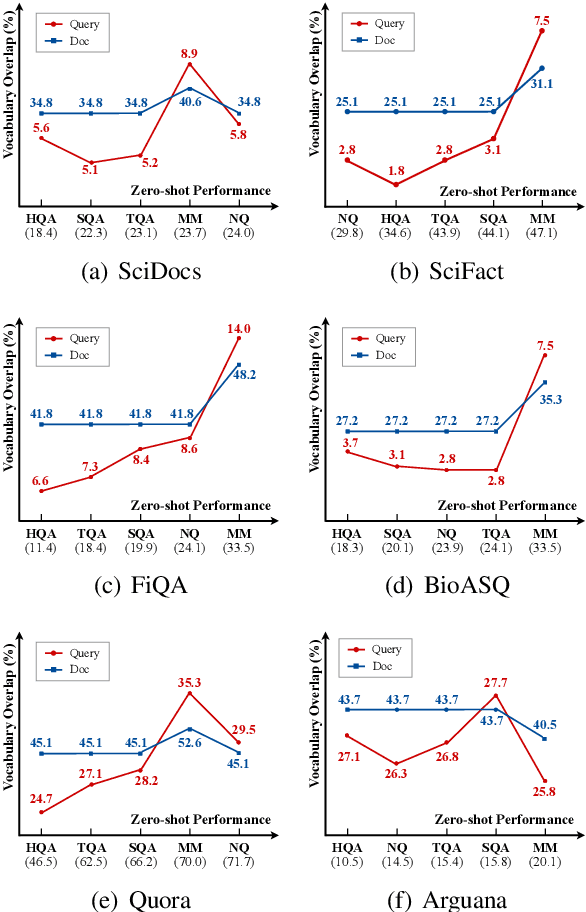
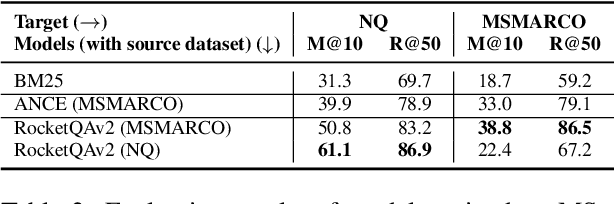
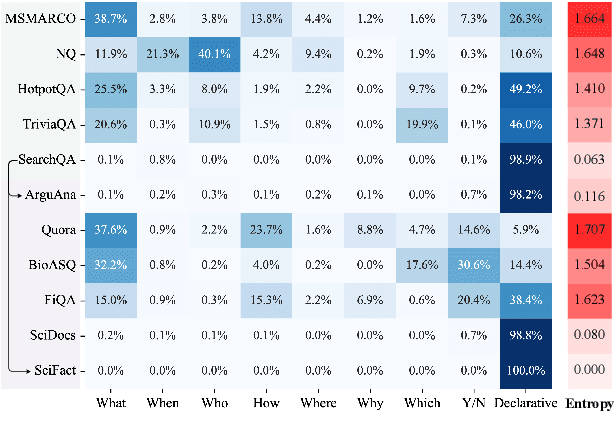
Recent years have witnessed the significant advance in dense retrieval (DR) based on powerful pre-trained language models (PLM). DR models have achieved excellent performance in several benchmark datasets, while they are shown to be not as competitive as traditional sparse retrieval models (e.g., BM25) in a zero-shot retrieval setting. However, in the related literature, there still lacks a detailed and comprehensive study on zero-shot retrieval. In this paper, we present the first thorough examination of the zero-shot capability of DR models. We aim to identify the key factors and analyze how they affect zero-shot retrieval performance. In particular, we discuss the effect of several key factors related to source training set, analyze the potential bias from the target dataset, and review and compare existing zero-shot DR models. Our findings provide important evidence to better understand and develop zero-shot DR models.
Towards Multi-Turn Empathetic Dialogs with Positive Emotion Elicitation
Apr 22, 2022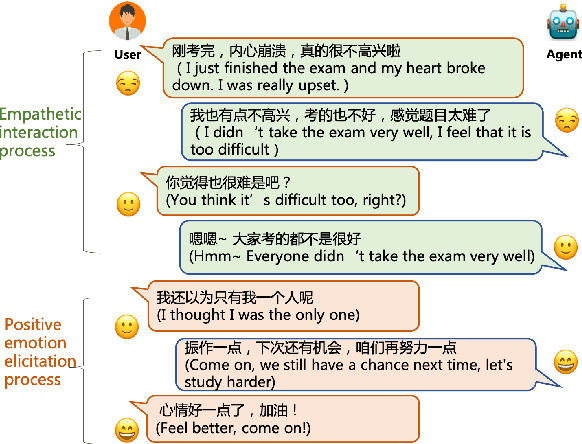
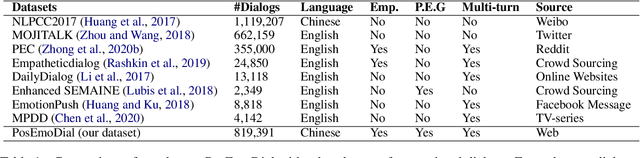

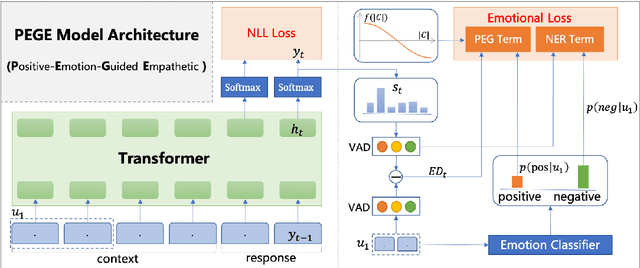
Emotional support is a crucial skill for many real-world scenarios, including caring for the elderly, mental health support, and customer service chats. This paper presents a novel task of empathetic dialog generation with positive emotion elicitation to promote users' positive emotions, similar to that of emotional support between humans. In this task, the agent conducts empathetic responses along with the target of eliciting the user's positive emotions in the multi-turn dialog. To facilitate the study of this task, we collect a large-scale emotional dialog dataset with positive emotion elicitation, called PosEmoDial (about 820k dialogs, 3M utterances). In these dialogs, the agent tries to guide the user from any possible initial emotional state, e.g., sadness, to a positive emotional state. Then we present a positive-emotion-guided dialog generation model with a novel loss function design. This loss function encourages the dialog model to not only elicit positive emotions from users but also ensure smooth emotional transitions along with the whole dialog. Finally, we establish benchmark results on PosEmoDial, and we will release this dataset and related source code to facilitate future studies.
Where to Go for the Holidays: Towards Mixed-Type Dialogs for Clarification of User Goals
Apr 15, 2022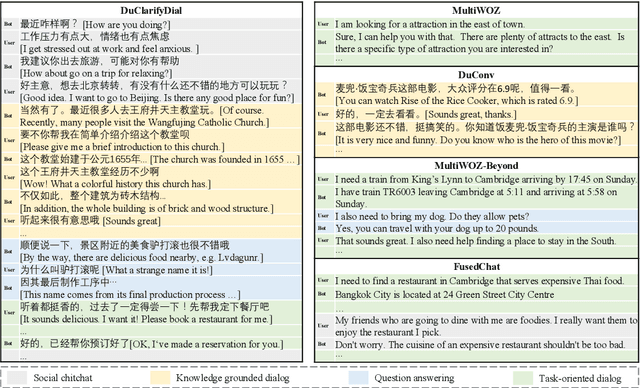

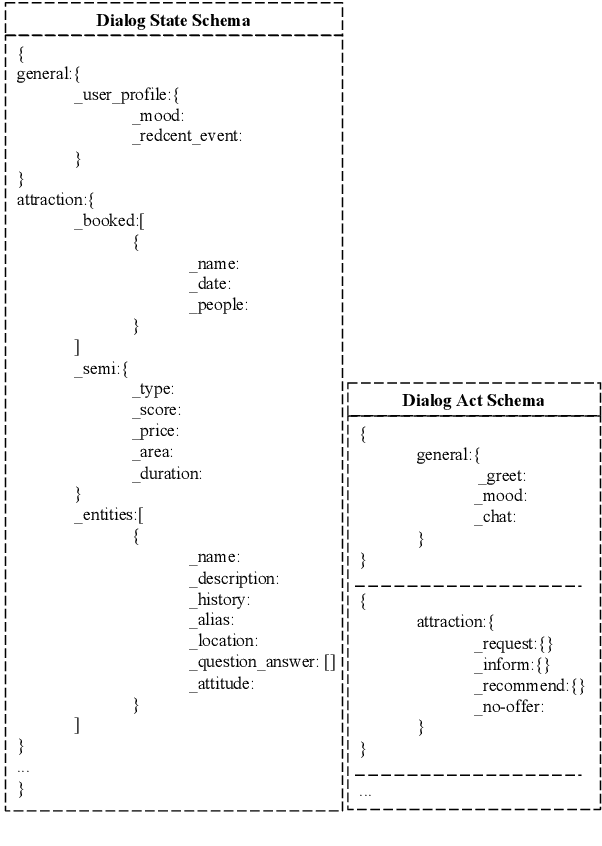
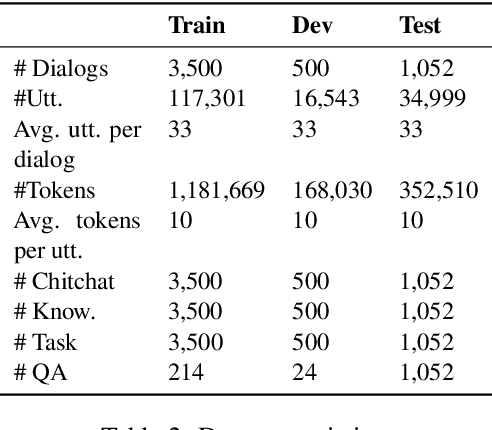
Most dialog systems posit that users have figured out clear and specific goals before starting an interaction. For example, users have determined the departure, the destination, and the travel time for booking a flight. However, in many scenarios, limited by experience and knowledge, users may know what they need, but still struggle to figure out clear and specific goals by determining all the necessary slots. In this paper, we identify this challenge and make a step forward by collecting a new human-to-human mixed-type dialog corpus. It contains 5k dialog sessions and 168k utterances for 4 dialog types and 5 domains. Within each session, an agent first provides user-goal-related knowledge to help figure out clear and specific goals, and then help achieve them. Furthermore, we propose a mixed-type dialog model with a novel Prompt-based continual learning mechanism. Specifically, the mechanism enables the model to continually strengthen its ability on any specific type by utilizing existing dialog corpora effectively.
Unified Structure Generation for Universal Information Extraction
Mar 23, 2022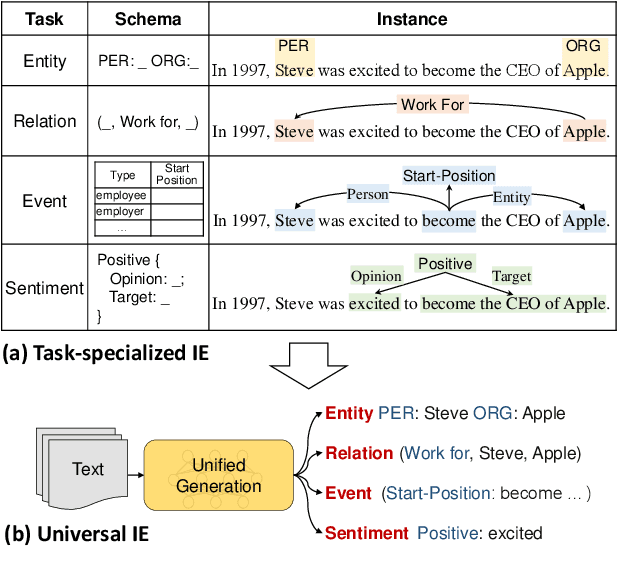


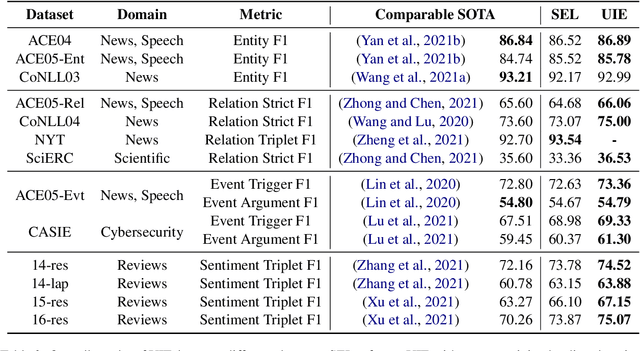
Information extraction suffers from its varying targets, heterogeneous structures, and demand-specific schemas. In this paper, we propose a unified text-to-structure generation framework, namely UIE, which can universally model different IE tasks, adaptively generate targeted structures, and collaboratively learn general IE abilities from different knowledge sources. Specifically, UIE uniformly encodes different extraction structures via a structured extraction language, adaptively generates target extractions via a schema-based prompt mechanism - structural schema instructor, and captures the common IE abilities via a large-scale pre-trained text-to-structure model. Experiments show that UIE achieved the state-of-the-art performance on 4 IE tasks, 13 datasets, and on all supervised, low-resource, and few-shot settings for a wide range of entity, relation, event and sentiment extraction tasks and their unification. These results verified the effectiveness, universality, and transferability of UIE.
ERNIE-SPARSE: Learning Hierarchical Efficient Transformer Through Regularized Self-Attention
Mar 23, 2022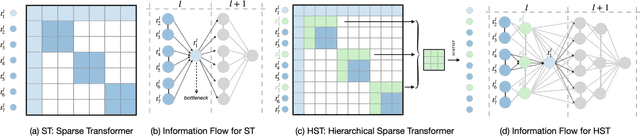
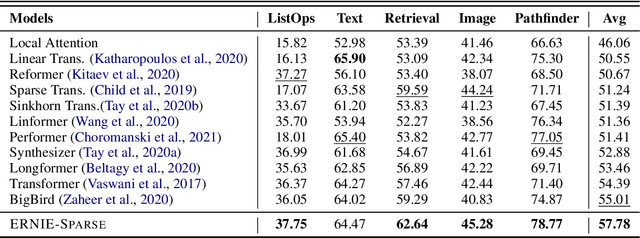
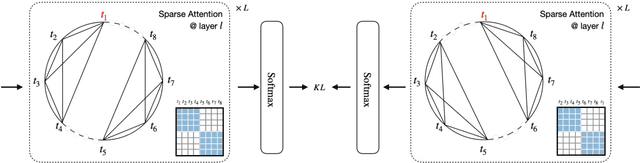
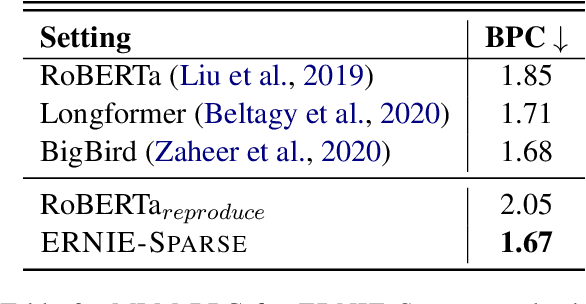
Sparse Transformer has recently attracted a lot of attention since the ability for reducing the quadratic dependency on the sequence length. We argue that two factors, information bottleneck sensitivity and inconsistency between different attention topologies, could affect the performance of the Sparse Transformer. This paper proposes a well-designed model named ERNIE-Sparse. It consists of two distinctive parts: (i) Hierarchical Sparse Transformer (HST) to sequentially unify local and global information. (ii) Self-Attention Regularization (SAR) method, a novel regularization designed to minimize the distance for transformers with different attention topologies. To evaluate the effectiveness of ERNIE-Sparse, we perform extensive evaluations. Firstly, we perform experiments on a multi-modal long sequence modeling task benchmark, Long Range Arena (LRA). Experimental results demonstrate that ERNIE-Sparse significantly outperforms a variety of strong baseline methods including the dense attention and other efficient sparse attention methods and achieves improvements by 2.77% (57.78% vs. 55.01%). Secondly, to further show the effectiveness of our method, we pretrain ERNIE-Sparse and verified it on 3 text classification and 2 QA downstream tasks, achieve improvements on classification benchmark by 0.83% (92.46% vs. 91.63%), on QA benchmark by 3.24% (74.67% vs. 71.43%). Experimental results continue to demonstrate its superior performance.
DuReader_retrieval: A Large-scale Chinese Benchmark for Passage Retrieval from Web Search Engine
Mar 19, 2022
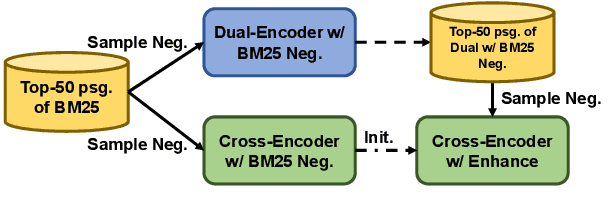
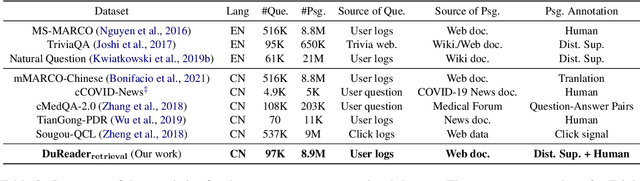
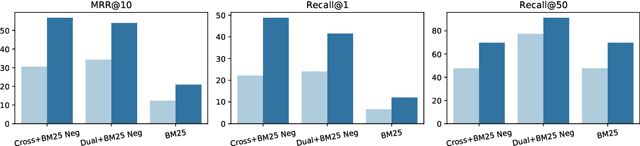
In this paper, we present DuReader_retrieval, a large-scale Chinese dataset for passage retrieval. DuReader_retrieval contains more than 90K queries and over 8M unique passages from Baidu search. To ensure the quality of our benchmark and address the shortcomings in other existing datasets, we (1) reduce the false negatives in development and testing sets by pooling the results from multiple retrievers with human annotations, (2) and remove the semantically similar questions between training with development and testing sets. We further introduce two extra out-of-domain testing sets for benchmarking the domain generalization capability. Our experiment results demonstrate that DuReader_retrieval is challenging and there is still plenty of room for the community to improve, e.g. the generalization across domains, salient phrase and syntax mismatch between query and paragraph and robustness. DuReader_retrieval will be publicly available at https://github.com/baidu/DuReader/tree/master/DuReader-Retrieval
PLANET: Dynamic Content Planning in Autoregressive Transformers for Long-form Text Generation
Mar 17, 2022

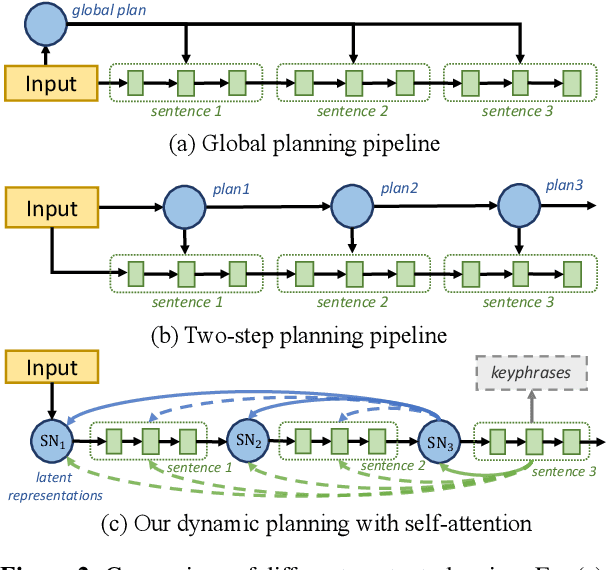
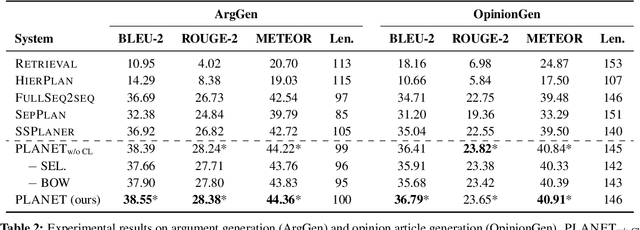
Despite recent progress of pre-trained language models on generating fluent text, existing methods still suffer from incoherence problems in long-form text generation tasks that require proper content control and planning to form a coherent high-level logical flow. In this work, we propose PLANET, a novel generation framework leveraging autoregressive self-attention mechanism to conduct content planning and surface realization dynamically. To guide the generation of output sentences, our framework enriches the Transformer decoder with latent representations to maintain sentence-level semantic plans grounded by bag-of-words. Moreover, we introduce a new coherence-based contrastive learning objective to further improve the coherence of output. Extensive experiments are conducted on two challenging long-form text generation tasks including counterargument generation and opinion article generation. Both automatic and human evaluations show that our method significantly outperforms strong baselines and generates more coherent texts with richer contents.