 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Multimodal Representation in Contrastive Learning: From Patch and Token Embeddings to Finite Discrete Tokens
Mar 27, 2023



Contrastive learning-based vision-language pre-training approaches, such as CLIP, have demonstrated great success in many vision-language tasks. These methods achieve cross-modal alignment by encoding a matched image-text pair with similar feature embeddings, which are generated by aggregating information from visual patches and language tokens. However, direct aligning cross-modal information using such representations is challenging, as visual patches and text tokens differ in semantic levels and granularities. To alleviate this issue, we propose a Finite Discrete Tokens (FDT) based multimodal representation. FDT is a set of learnable tokens representing certain visual-semantic concepts. Both images and texts are embedded using shared FDT by first grounding multimodal inputs to FDT space and then aggregating the activated FDT representations. The matched visual and semantic concepts are enforced to be represented by the same set of discrete tokens by a sparse activation constraint. As a result, the granularity gap between the two modalities is reduced. Through both quantitative and qualitative analyses, we demonstrate that using FDT representations in CLIP-style models improves cross-modal alignment and performance in visual recognition and vision-language downstream tasks. Furthermore, we show that our method can learn more comprehensive representations, and the learned FDT capture meaningful cross-modal correspondence, ranging from objects to actions and attributes.
MetaNetwork: A Task-agnostic Network Parameters Generation Framework for Improving Device Model Generalization
Sep 12, 2022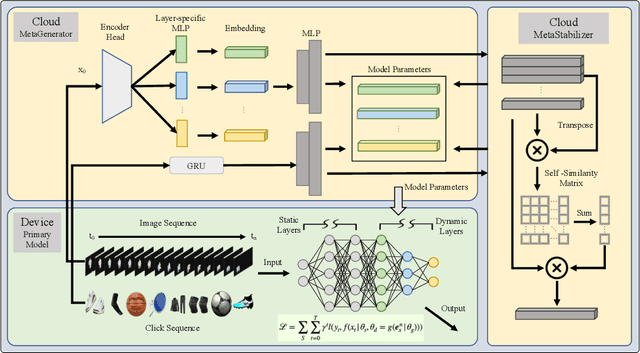
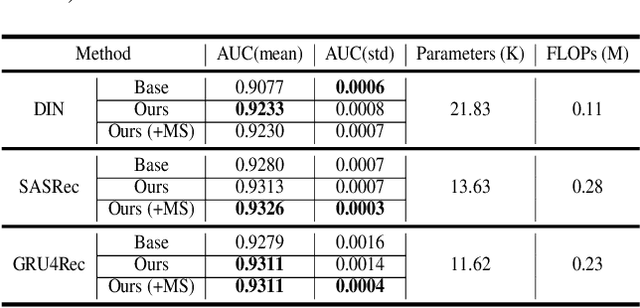
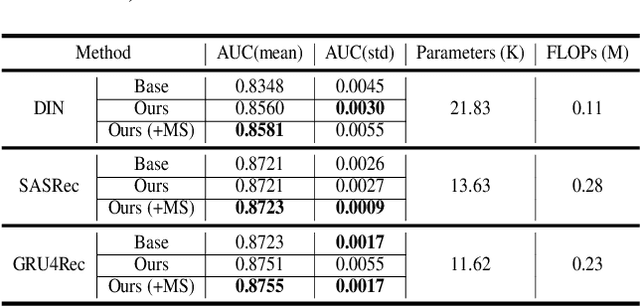

Deploying machine learning models on mobile devices has gained increasing attention. To tackle the model generalization problem with the limitations of hardware resources on the device, the device model needs to be lightweight by techniques such as model compression from the cloud model. However, the major obstacle to improve the device model generalization is the distribution shift between the data of cloud and device models, since the data distribution on device model often changes over time (e.g., users might have different preferences in recommendation system). Although real-time fine-tuning and distillation method take this situation into account, these methods require on-device training, which are practically infeasible due to the low computational power and a lack of real-time labeled samples on the device. In this paper, we propose a novel task-agnostic framework, named MetaNetwork, for generating adaptive device model parameters from cloud without on-device training. Specifically, our MetaNetwork is deployed on cloud and consists of MetaGenerator and MetaStabilizer modules. The MetaGenerator is designed to learn a mapping function from samples to model parameters, and it can generate and deliver the adaptive parameters to the device based on samples uploaded from the device to the cloud. The MetaStabilizer aims to reduce the oscillation of the MetaGenerator, accelerate the convergence and improve the model performance during both training and inference. We evaluate our method on two tasks with three datasets. Extensive experiments show that MetaNetwork can achieve competitive performances in different modalities.
Personalizing Intervened Network for Long-tailed Sequential User Behavior Modeling
Aug 19, 2022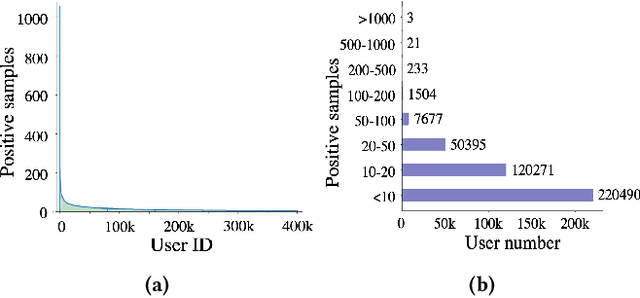


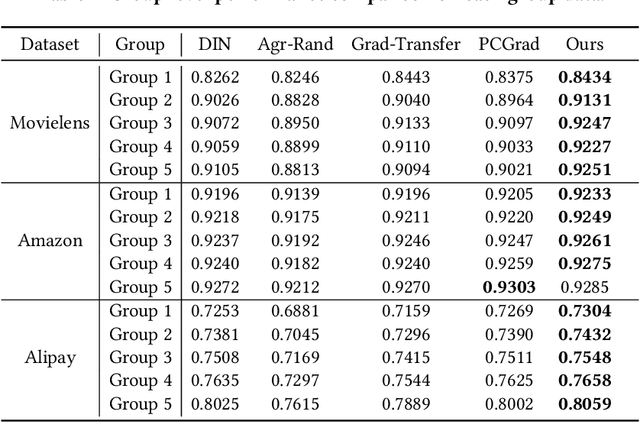
In an era of information explosion, recommendation systems play an important role in people's daily life by facilitating content exploration. It is known that user activeness, i.e., number of behaviors, tends to follow a long-tail distribution, where the majority of users are with low activeness. In practice, we observe that tail users suffer from significantly lower-quality recommendation than the head users after joint training. We further identify that a model trained on tail users separately still achieve inferior results due to limited data. Though long-tail distributions are ubiquitous in recommendation systems, improving the recommendation performance on the tail users still remains challenge in both research and industry. Directly applying related methods on long-tail distribution might be at risk of hurting the experience of head users, which is less affordable since a small portion of head users with high activeness contribute a considerate portion of platform revenue. In this paper, we propose a novel approach that significantly improves the recommendation performance of the tail users while achieving at least comparable performance for the head users over the base model. The essence of this approach is a novel Gradient Aggregation technique that learns common knowledge shared by all users into a backbone model, followed by separate plugin prediction networks for the head users and the tail users personalization. As for common knowledge learning, we leverage the backward adjustment from the causality theory for deconfounding the gradient estimation and thus shielding off the backbone training from the confounder, i.e., user activeness. We conduct extensive experiments on two public recommendation benchmark datasets and a large-scale industrial datasets collected from the Alipay platform. Empirical studies validate the rationality and effectiveness of our approach.
Prompt Tuning for Generative Multimodal Pretrained Models
Aug 04, 2022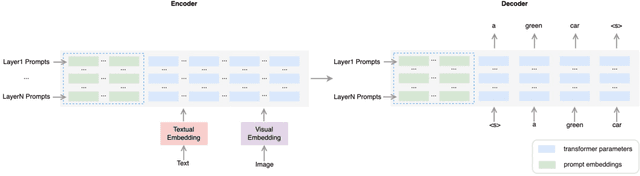


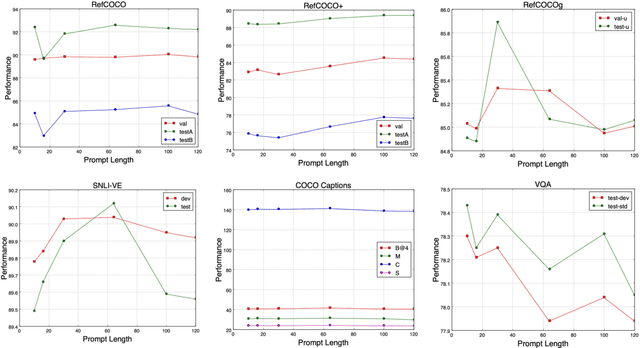
Prompt tuning has become a new paradigm for model tuning and it has demonstrated success in natural language pretraining and even vision pretraining. In this work, we explore the transfer of prompt tuning to multimodal pretraining, with a focus on generative multimodal pretrained models, instead of contrastive ones. Specifically, we implement prompt tuning on the unified sequence-to-sequence pretrained model adaptive to both understanding and generation tasks. Experimental results demonstrate that the light-weight prompt tuning can achieve comparable performance with finetuning and surpass other light-weight tuning methods. Besides, in comparison with finetuned models, the prompt-tuned models demonstrate improved robustness against adversarial attacks. We further figure out that experimental factors, including the prompt length, prompt depth, and reparameteratization, have great impacts on the model performance, and thus we empirically provide a recommendation for the setups of prompt tuning. Despite the observed advantages, we still find some limitations in prompt tuning, and we correspondingly point out the directions for future studies. Codes are available at \url{https://github.com/OFA-Sys/OFA}
Single Stage Virtual Try-on via Deformable Attention Flows
Jul 19, 2022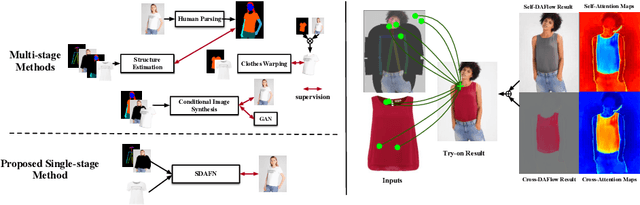

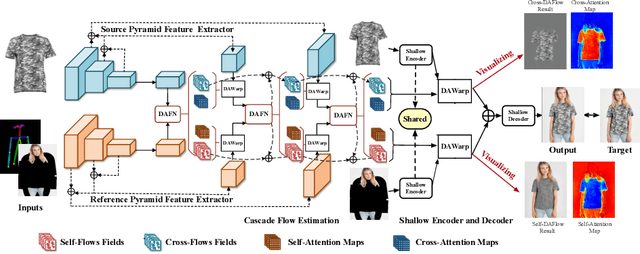
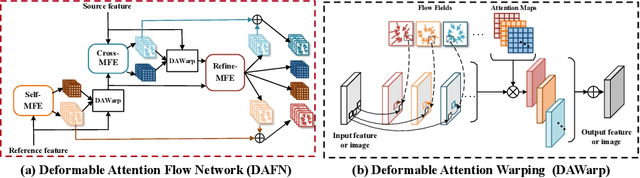
Virtual try-on aims to generate a photo-realistic fitting result given an in-shop garment and a reference person image. Existing methods usually build up multi-stage frameworks to deal with clothes warping and body blending respectively, or rely heavily on intermediate parser-based labels which may be noisy or even inaccurate. To solve the above challenges, we propose a single-stage try-on framework by developing a novel Deformable Attention Flow (DAFlow), which applies the deformable attention scheme to multi-flow estimation. With pose keypoints as the guidance only, the self- and cross-deformable attention flows are estimated for the reference person and the garment images, respectively. By sampling multiple flow fields, the feature-level and pixel-level information from different semantic areas are simultaneously extracted and merged through the attention mechanism. It enables clothes warping and body synthesizing at the same time which leads to photo-realistic results in an end-to-end manner. Extensive experiments on two try-on datasets demonstrate that our proposed method achieves state-of-the-art performance both qualitatively and quantitatively. Furthermore, additional experiments on the other two image editing tasks illustrate the versatility of our method for multi-view synthesis and image animation.
Device-Cloud Collaborative Recommendation via Meta Controller
Jul 07, 2022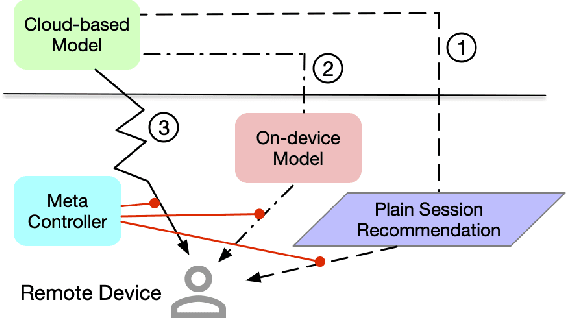
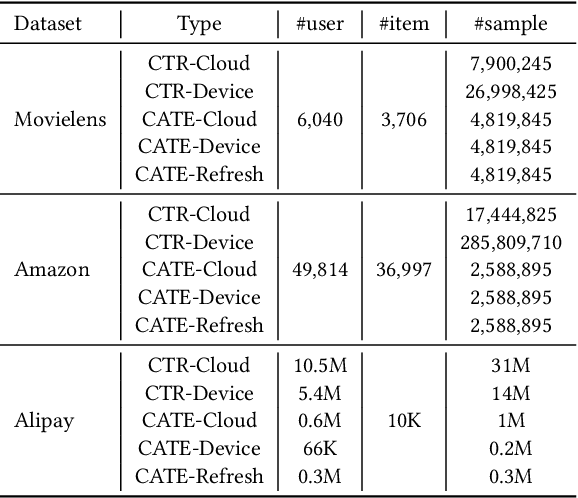
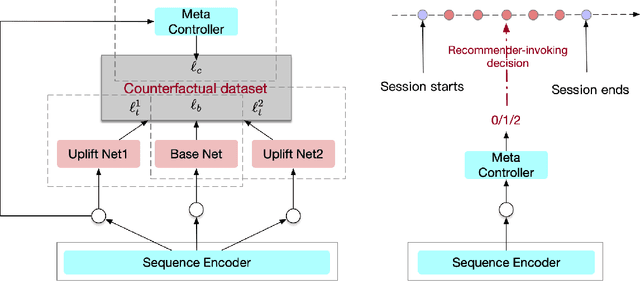
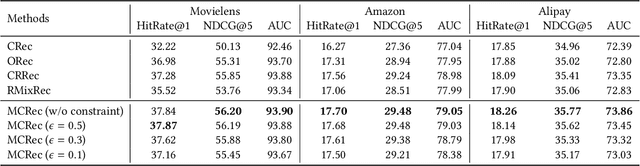
On-device machine learning enables the lightweight deployment of recommendation models in local clients, which reduces the burden of the cloud-based recommenders and simultaneously incorporates more real-time user features. Nevertheless, the cloud-based recommendation in the industry is still very important considering its powerful model capacity and the efficient candidate generation from the billion-scale item pool. Previous attempts to integrate the merits of both paradigms mainly resort to a sequential mechanism, which builds the on-device recommender on top of the cloud-based recommendation. However, such a design is inflexible when user interests dramatically change: the on-device model is stuck by the limited item cache while the cloud-based recommendation based on the large item pool do not respond without the new re-fresh feedback. To overcome this issue, we propose a meta controller to dynamically manage the collaboration between the on-device recommender and the cloud-based recommender, and introduce a novel efficient sample construction from the causal perspective to solve the dataset absence issue of meta controller. On the basis of the counterfactual samples and the extended training, extensive experiments in the industrial recommendation scenarios show the promise of meta controller in the device-cloud collaboration.
Knowledge Distillation of Transformer-based Language Models Revisited
Jun 30, 2022
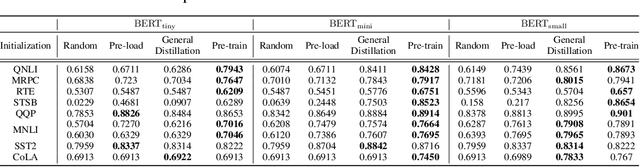
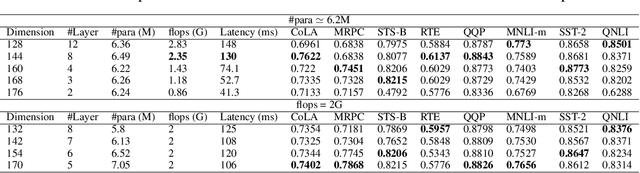
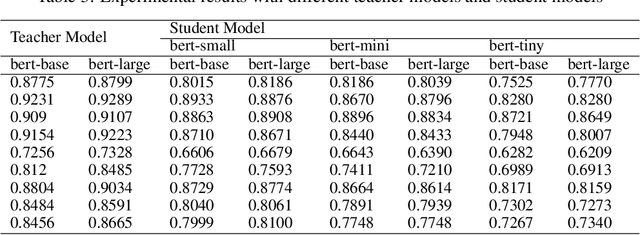
In the past few years, transformer-based pre-trained language models have achieved astounding success in both industry and academia. However, the large model size and high run-time latency are serious impediments to applying them in practice, especially on mobile phones and Internet of Things (IoT) devices. To compress the model, considerable literature has grown up around the theme of knowledge distillation (KD) recently. Nevertheless, how KD works in transformer-based models is still unclear. We tease apart the components of KD and propose a unified KD framework. Through the framework, systematic and extensive experiments that spent over 23,000 GPU hours render a comprehensive analysis from the perspectives of knowledge types, matching strategies, width-depth trade-off, initialization, model size, etc. Our empirical results shed light on the distillation in the pre-train language model and with relative significant improvement over previous state-of-the-arts(SOTA). Finally, we provide a best-practice guideline for the KD in transformer-based models.
Instance-wise Prompt Tuning for Pretrained Language Models
Jun 04, 2022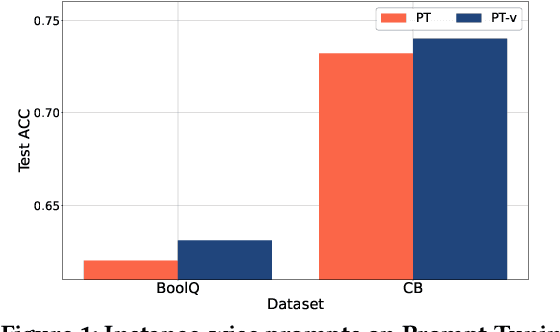

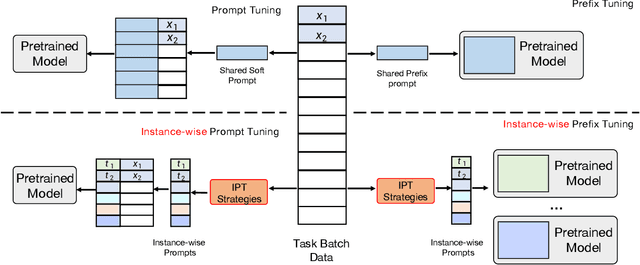
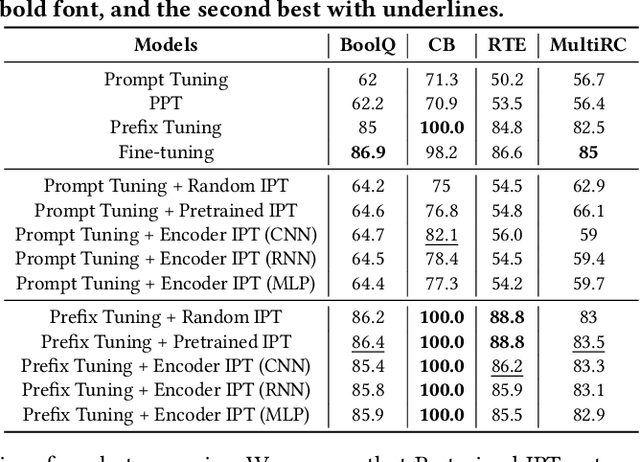
Prompt Learning has recently gained great popularity in bridging the gap between pretraining tasks and various downstream tasks. It freezes Pretrained Language Models (PLMs) and only tunes a few task-related parameters (prompts) for downstream tasks, greatly reducing the cost of tuning giant models. The key enabler of this is the idea of querying PLMs with task-specific knowledge implicated in prompts. This paper reveals a major limitation of existing methods that the indiscriminate prompts for all input data in a task ignore the intrinsic knowledge from input data, resulting in sub-optimal performance. We introduce Instance-wise Prompt Tuning (IPT), the first prompt learning paradigm that injects knowledge from the input data instances to the prompts, thereby providing PLMs with richer and more concrete context information. We devise a series of strategies to produce instance-wise prompts, addressing various concerns like model quality and cost-efficiency. Across multiple tasks and resource settings, IPT significantly outperforms task-based prompt learning methods, and achieves comparable performance to conventional finetuning with only 0.5% - 1.5% of tuned parameters.
GraphMAE: Self-Supervised Masked Graph Autoencoders
May 24, 2022
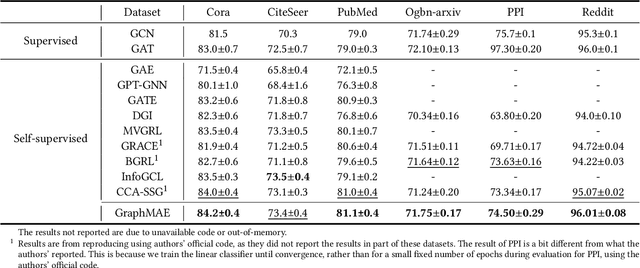
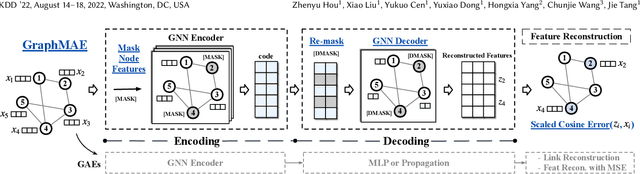
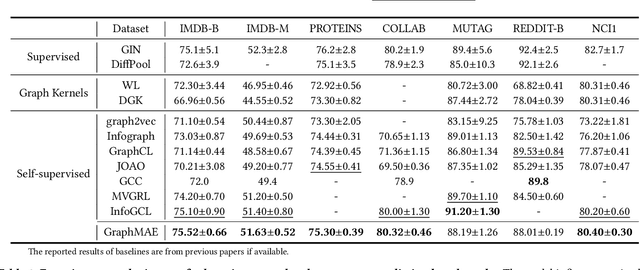
Self-supervised learning (SSL) has been extensively explored in recent years. Particularly, generative SSL has seen emerging success in natural language processing and other fields, such as the wide adoption of BERT and GPT. Despite this, contrastive learning--which heavily relies on structural data augmentation and complicated training strategies--has been the dominant approach in graph SSL, while the progress of generative SSL on graphs, especially graph autoencoders (GAEs), has thus far not reached the potential as promised in other fields. In this paper, we identify and examine the issues that negatively impact the development of GAEs, including their reconstruction objective, training robustness, and error metric. We present a masked graph autoencoder GraphMAE that mitigates these issues for generative self-supervised graph learning. Instead of reconstructing structures, we propose to focus on feature reconstruction with both a masking strategy and scaled cosine error that benefit the robust training of GraphMAE. We conduct extensive experiments on 21 public datasets for three different graph learning tasks. The results manifest that GraphMAE--a simple graph autoencoder with our careful designs--can consistently generate outperformance over both contrastive and generative state-of-the-art baselines. This study provides an understanding of graph autoencoders and demonstrates the potential of generative self-supervised learning on graphs.
M6-Fashion: High-Fidelity Multi-modal Image Generation and Editing
May 24, 2022
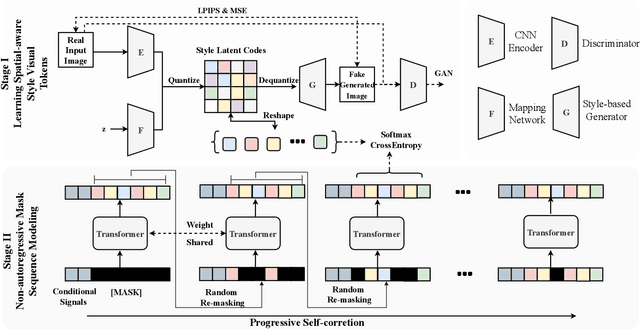
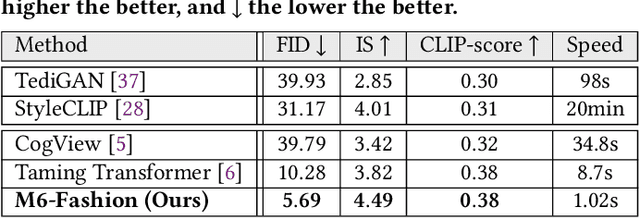

The fashion industry has diverse applications in multi-modal image generation and editing. It aims to create a desired high-fidelity image with the multi-modal conditional signal as guidance. Most existing methods learn different condition guidance controls by introducing extra models or ignoring the style prior knowledge, which is difficult to handle multiple signal combinations and faces a low-fidelity problem. In this paper, we adapt both style prior knowledge and flexibility of multi-modal control into one unified two-stage framework, M6-Fashion, focusing on the practical AI-aided Fashion design. It decouples style codes in both spatial and semantic dimensions to guarantee high-fidelity image generation in the first stage. M6-Fashion utilizes self-correction for the non-autoregressive generation to improve inference speed, enhance holistic consistency, and support various signal controls. Extensive experiments on a large-scale clothing dataset M2C-Fashion demonstrate superior performances on various image generation and editing tasks. M6-Fashion model serves as a highly potential AI designer for the fashion industry.