 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDenoising Time Cycle Modeling for Recommendation
Feb 05, 2024



Recently, modeling temporal patterns of user-item interactions have attracted much attention in recommender systems. We argue that existing methods ignore the variety of temporal patterns of user behaviors. We define the subset of user behaviors that are irrelevant to the target item as noises, which limits the performance of target-related time cycle modeling and affect the recommendation performance. In this paper, we propose Denoising Time Cycle Modeling (DiCycle), a novel approach to denoise user behaviors and select the subset of user behaviors that are highly related to the target item. DiCycle is able to explicitly model diverse time cycle patterns for recommendation. Extensive experiments are conducted on both public benchmarks and a real-world dataset, demonstrating the superior performance of DiCycle over the state-of-the-art recommendation methods.
Prototypical Contrastive Learning and Adaptive Interest Selection for Candidate Generation in Recommendations
Nov 23, 2022



Deep Candidate Generation plays an important role in large-scale recommender systems. It takes user history behaviors as inputs and learns user and item latent embeddings for candidate generation. In the literature, conventional methods suffer from two problems. First, a user has multiple embeddings to reflect various interests, and such number is fixed. However, taking into account different levels of user activeness, a fixed number of interest embeddings is sub-optimal. For example, for less active users, they may need fewer embeddings to represent their interests compared to active users. Second, the negative samples are often generated by strategies with unobserved supervision, and similar items could have different labels. Such a problem is termed as class collision. In this paper, we aim to advance the typical two-tower DNN candidate generation model. Specifically, an Adaptive Interest Selection Layer is designed to learn the number of user embeddings adaptively in an end-to-end way, according to the level of their activeness. Furthermore, we propose a Prototypical Contrastive Learning Module to tackle the class collision problem introduced by negative sampling. Extensive experimental evaluations show that the proposed scheme remarkably outperforms competitive baselines on multiple benchmarks.
Device-Cloud Collaborative Recommendation via Meta Controller
Jul 07, 2022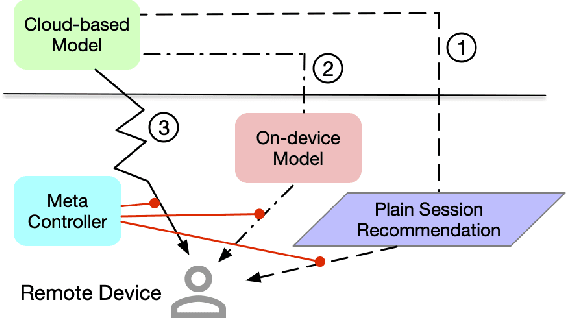
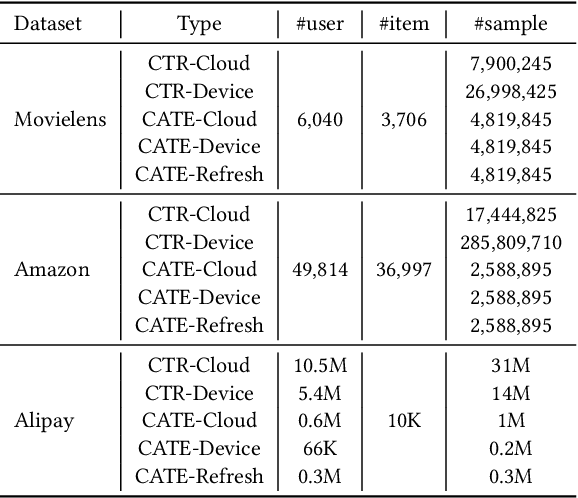
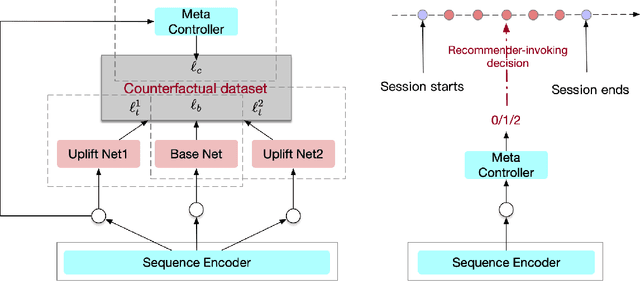
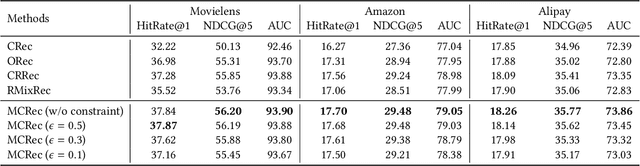
On-device machine learning enables the lightweight deployment of recommendation models in local clients, which reduces the burden of the cloud-based recommenders and simultaneously incorporates more real-time user features. Nevertheless, the cloud-based recommendation in the industry is still very important considering its powerful model capacity and the efficient candidate generation from the billion-scale item pool. Previous attempts to integrate the merits of both paradigms mainly resort to a sequential mechanism, which builds the on-device recommender on top of the cloud-based recommendation. However, such a design is inflexible when user interests dramatically change: the on-device model is stuck by the limited item cache while the cloud-based recommendation based on the large item pool do not respond without the new re-fresh feedback. To overcome this issue, we propose a meta controller to dynamically manage the collaboration between the on-device recommender and the cloud-based recommender, and introduce a novel efficient sample construction from the causal perspective to solve the dataset absence issue of meta controller. On the basis of the counterfactual samples and the extended training, extensive experiments in the industrial recommendation scenarios show the promise of meta controller in the device-cloud collaboration.