 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking Large Language Models via Random Variables
Jan 20, 2025With the continuous advancement of large language models (LLMs) in mathematical reasoning, evaluating their performance in this domain has become a prominent research focus. Recent studies have raised concerns about the reliability of current mathematical benchmarks, highlighting issues such as simplistic design and potential data leakage. Therefore, creating a reliable benchmark that effectively evaluates the genuine capabilities of LLMs in mathematical reasoning remains a significant challenge. To address this, we propose RV-Bench, a framework for Benchmarking LLMs via Random Variables in mathematical reasoning. Specifically, the background content of a random variable question (RV question) mirrors the original problem in existing standard benchmarks, but the variable combinations are randomized into different values. LLMs must fully understand the problem-solving process for the original problem to correctly answer RV questions with various combinations of variable values. As a result, the LLM's genuine capability in mathematical reasoning is reflected by its accuracy on RV-Bench. Extensive experiments are conducted with 29 representative LLMs across 900+ RV questions. A leaderboard for RV-Bench ranks the genuine capability of these LLMs. Further analysis of accuracy dropping indicates that current LLMs still struggle with complex mathematical reasoning problems.
InfiGUIAgent: A Multimodal Generalist GUI Agent with Native Reasoning and Reflection
Jan 08, 2025Graphical User Interface (GUI) Agents, powered by multimodal large language models (MLLMs), have shown great potential for task automation on computing devices such as computers and mobile phones. However, existing agents face challenges in multi-step reasoning and reliance on textual annotations, limiting their effectiveness. We introduce \textit{InfiGUIAgent}, an MLLM-based GUI Agent trained with a two-stage supervised fine-tuning pipeline. Stage 1 enhances fundamental skills such as GUI understanding and grounding, while Stage 2 integrates hierarchical reasoning and expectation-reflection reasoning skills using synthesized data to enable native reasoning abilities of the agents. \textit{InfiGUIAgent} achieves competitive performance on several GUI benchmarks, highlighting the impact of native reasoning skills in enhancing GUI interaction for automation tasks. Resources are available at \url{https://github.com/Reallm-Labs/InfiGUIAgent}.
InfiFusion: A Unified Framework for Enhanced Cross-Model Reasoning via LLM Fusion
Jan 06, 2025
Large Language Models (LLMs) have demonstrated strong performance across various reasoning tasks, yet building a single model that consistently excels across all domains remains challenging. This paper addresses this problem by exploring strategies to integrate multiple domain-specialized models into an efficient pivot model.We propose two fusion strategies to combine the strengths of multiple LLMs: (1) a pairwise, multi-step fusion approach that sequentially distills each source model into the pivot model, followed by a weight merging step to integrate the distilled models into the final model. This method achieves strong performance but requires substantial training effort; and (2) a unified fusion approach that aggregates all source models' outputs simultaneously.To improve the fusion process, we introduce a novel Rate-Skewness Adaptive Fusion (RSAF) technique, which dynamically adjusts top-K ratios during parameter merging for enhanced flexibility and stability.Furthermore, we propose an uncertainty-based weighting method for the unified approach, which dynamically balances the contributions of source models and outperforms other logits/distribution ensemble methods.We achieved accuracy improvements of 9.27%, 8.80%, and 8.89% on the GSM8K, MATH, and HumanEval tasks, respectively.
Quantization Meets Reasoning: Exploring LLM Low-Bit Quantization Degradation for Mathematical Reasoning
Jan 06, 2025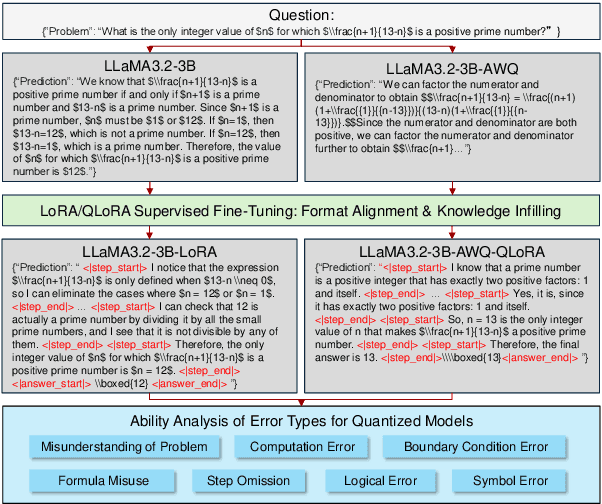
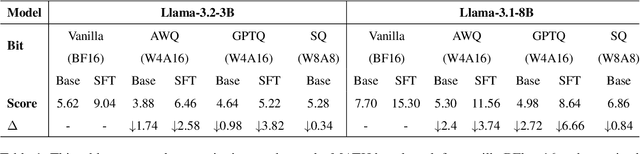

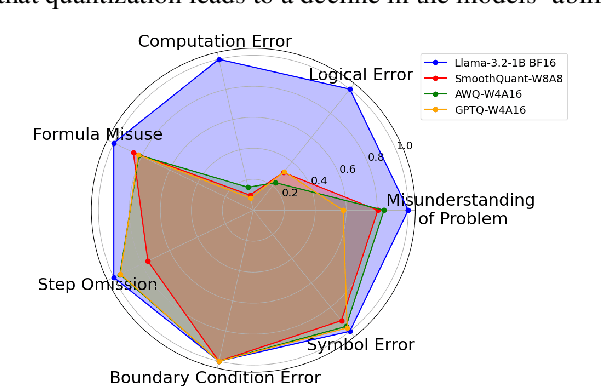
Large language models have achieved significant advancements in complex mathematical reasoning benchmarks, such as MATH. However, their substantial computational requirements present challenges for practical deployment. Model quantization has emerged as an effective strategy to reduce memory usage and computational costs by employing lower precision and bit-width representations. In this study, we systematically evaluate the impact of quantization on mathematical reasoning tasks. We introduce a multidimensional evaluation framework that qualitatively assesses specific capability dimensions and conduct quantitative analyses on the step-by-step outputs of various quantization methods. Our results demonstrate that quantization differentially affects numerical computation and reasoning planning abilities, identifying key areas where quantized models experience performance degradation.
Autoregressive Models in Vision: A Survey
Nov 08, 2024



Autoregressive modeling has been a huge success in the field of natural language processing (NLP). Recently, autoregressive models have emerged as a significant area of focus in computer vision, where they excel in producing high-quality visual content. Autoregressive models in NLP typically operate on subword tokens. However, the representation strategy in computer vision can vary in different levels, \textit{i.e.}, pixel-level, token-level, or scale-level, reflecting the diverse and hierarchical nature of visual data compared to the sequential structure of language. This survey comprehensively examines the literature on autoregressive models applied to vision. To improve readability for researchers from diverse research backgrounds, we start with preliminary sequence representation and modeling in vision. Next, we divide the fundamental frameworks of visual autoregressive models into three general sub-categories, including pixel-based, token-based, and scale-based models based on the strategy of representation. We then explore the interconnections between autoregressive models and other generative models. Furthermore, we present a multi-faceted categorization of autoregressive models in computer vision, including image generation, video generation, 3D generation, and multi-modal generation. We also elaborate on their applications in diverse domains, including emerging domains such as embodied AI and 3D medical AI, with about 250 related references. Finally, we highlight the current challenges to autoregressive models in vision with suggestions about potential research directions. We have also set up a Github repository to organize the papers included in this survey at: \url{https://github.com/ChaofanTao/Autoregressive-Models-in-Vision-Survey}.
DreamClear: High-Capacity Real-World Image Restoration with Privacy-Safe Dataset Curation
Oct 24, 2024



Image restoration (IR) in real-world scenarios presents significant challenges due to the lack of high-capacity models and comprehensive datasets. To tackle these issues, we present a dual strategy: GenIR, an innovative data curation pipeline, and DreamClear, a cutting-edge Diffusion Transformer (DiT)-based image restoration model. GenIR, our pioneering contribution, is a dual-prompt learning pipeline that overcomes the limitations of existing datasets, which typically comprise only a few thousand images and thus offer limited generalizability for larger models. GenIR streamlines the process into three stages: image-text pair construction, dual-prompt based fine-tuning, and data generation & filtering. This approach circumvents the laborious data crawling process, ensuring copyright compliance and providing a cost-effective, privacy-safe solution for IR dataset construction. The result is a large-scale dataset of one million high-quality images. Our second contribution, DreamClear, is a DiT-based image restoration model. It utilizes the generative priors of text-to-image (T2I) diffusion models and the robust perceptual capabilities of multi-modal large language models (MLLMs) to achieve photorealistic restoration. To boost the model's adaptability to diverse real-world degradations, we introduce the Mixture of Adaptive Modulator (MoAM). It employs token-wise degradation priors to dynamically integrate various restoration experts, thereby expanding the range of degradations the model can address. Our exhaustive experiments confirm DreamClear's superior performance, underlining the efficacy of our dual strategy for real-world image restoration. Code and pre-trained models will be available at: https://github.com/shallowdream204/DreamClear.
Unconstrained Model Merging for Enhanced LLM Reasoning
Oct 17, 2024



Recent advancements in building domain-specific large language models (LLMs) have shown remarkable success, especially in tasks requiring reasoning abilities like logical inference over complex relationships and multi-step problem solving. However, creating a powerful all-in-one LLM remains challenging due to the need for proprietary data and vast computational resources. As a resource-friendly alternative, we explore the potential of merging multiple expert models into a single LLM. Existing studies on model merging mainly focus on generalist LLMs instead of domain experts, or the LLMs under the same architecture and size. In this work, we propose an unconstrained model merging framework that accommodates both homogeneous and heterogeneous model architectures with a focus on reasoning tasks. A fine-grained layer-wise weight merging strategy is designed for homogeneous models merging, while heterogeneous model merging is built upon the probabilistic distribution knowledge derived from instruction-response fine-tuning data. Across 7 benchmarks and 9 reasoning-optimized LLMs, we reveal key findings that combinatorial reasoning emerges from merging which surpasses simple additive effects. We propose that unconstrained model merging could serve as a foundation for decentralized LLMs, marking a notable progression from the existing centralized LLM framework. This evolution could enhance wider participation and stimulate additional advancement in the field of artificial intelligence, effectively addressing the constraints posed by centralized models.
BabelBench: An Omni Benchmark for Code-Driven Analysis of Multimodal and Multistructured Data
Oct 01, 2024



Large language models (LLMs) have become increasingly pivotal across various domains, especially in handling complex data types. This includes structured data processing, as exemplified by ChartQA and ChatGPT-Ada, and multimodal unstructured data processing as seen in Visual Question Answering (VQA). These areas have attracted significant attention from both industry and academia. Despite this, there remains a lack of unified evaluation methodologies for these diverse data handling scenarios. In response, we introduce BabelBench, an innovative benchmark framework that evaluates the proficiency of LLMs in managing multimodal multistructured data with code execution. BabelBench incorporates a dataset comprising 247 meticulously curated problems that challenge the models with tasks in perception, commonsense reasoning, logical reasoning, and so on. Besides the basic capabilities of multimodal understanding, structured data processing as well as code generation, these tasks demand advanced capabilities in exploration, planning, reasoning and debugging. Our experimental findings on BabelBench indicate that even cutting-edge models like ChatGPT 4 exhibit substantial room for improvement. The insights derived from our comprehensive analysis offer valuable guidance for future research within the community. The benchmark data can be found at https://github.com/FFD8FFE/babelbench.
Law of Vision Representation in MLLMs
Aug 29, 2024



We present the "Law of Vision Representation" in multimodal large language models (MLLMs). It reveals a strong correlation between the combination of cross-modal alignment, correspondence in vision representation, and MLLM performance. We quantify the two factors using the cross-modal Alignment and Correspondence score (AC score). Through extensive experiments involving thirteen different vision representation settings and evaluations across eight benchmarks, we find that the AC score is linearly correlated to model performance. By leveraging this relationship, we are able to identify and train the optimal vision representation only, which does not require finetuning the language model every time, resulting in a 99.7% reduction in computational cost.
Retrieval-Augmented Mixture of LoRA Experts for Uploadable Machine Learning
Jun 24, 2024



Low-Rank Adaptation (LoRA) offers an efficient way to fine-tune large language models (LLMs). Its modular and plug-and-play nature allows the integration of various domain-specific LoRAs, enhancing LLM capabilities. Open-source platforms like Huggingface and Modelscope have introduced a new computational paradigm, Uploadable Machine Learning (UML). In UML, contributors use decentralized data to train specialized adapters, which are then uploaded to a central platform to improve LLMs. This platform uses these domain-specific adapters to handle mixed-task requests requiring personalized service. Previous research on LoRA composition either focuses on specific tasks or fixes the LoRA selection during training. However, in UML, the pool of LoRAs is dynamically updated with new uploads, requiring a generalizable selection mechanism for unseen LoRAs. Additionally, the mixed-task nature of downstream requests necessitates personalized services. To address these challenges, we propose Retrieval-Augmented Mixture of LoRA Experts (RAMoLE), a framework that adaptively retrieves and composes multiple LoRAs based on input prompts. RAMoLE has three main components: LoraRetriever for identifying and retrieving relevant LoRAs, an on-the-fly MoLE mechanism for coordinating the retrieved LoRAs, and efficient batch inference for handling heterogeneous requests. Experimental results show that RAMoLE consistently outperforms baselines, highlighting its effectiveness and scalability.