 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring the Design Space of Visual Context Representation in Video MLLMs
Oct 17, 2024



Video Multimodal Large Language Models (MLLMs) have shown remarkable capability of understanding the video semantics on various downstream tasks. Despite the advancements, there is still a lack of systematic research on visual context representation, which refers to the scheme to select frames from a video and further select the tokens from a frame. In this paper, we explore the design space for visual context representation, and aim to improve the performance of video MLLMs by finding more effective representation schemes. Firstly, we formulate the task of visual context representation as a constrained optimization problem, and model the language modeling loss as a function of the number of frames and the number of embeddings (or tokens) per frame, given the maximum visual context window size. Then, we explore the scaling effects in frame selection and token selection respectively, and fit the corresponding function curve by conducting extensive empirical experiments. We examine the effectiveness of typical selection strategies and present empirical findings to determine the two factors. Furthermore, we study the joint effect of frame selection and token selection, and derive the optimal formula for determining the two factors. We demonstrate that the derived optimal settings show alignment with the best-performed results of empirical experiments. Our code and model are available at: https://github.com/RUCAIBox/Opt-Visor.
Towards Event-oriented Long Video Understanding
Jun 20, 2024



With the rapid development of video Multimodal Large Language Models (MLLMs), numerous benchmarks have been proposed to assess their video understanding capability. However, due to the lack of rich events in the videos, these datasets may suffer from the short-cut bias that the answers can be deduced from a few frames, without the need to watch the entire video. To address this issue, we introduce Event-Bench, an event-oriented long video understanding benchmark built on existing datasets and human annotations. Event-Bench includes six event-related tasks and 2,190 test instances to comprehensively evaluate video event understanding ability. Additionally, we propose Video Instruction Merging~(VIM), a cost-effective method that enhances video MLLMs using merged, event-intensive video instructions, addressing the scarcity of human-annotated, event-intensive data. Extensive experiments show that the best-performing model, GPT-4o, achieves an overall accuracy of 53.33, significantly outperforming the best open-source model by 41.42%. Leveraging an effective instruction synthesis method and an adaptive model architecture, VIM surpasses both state-of-the-art open-source models and GPT-4V on the Event-Bench. All code, data, and models are publicly available at https://github.com/RUCAIBox/Event-Bench.
Needle In A Video Haystack: A Scalable Synthetic Framework for Benchmarking Video MLLMs
Jun 13, 2024



Video understanding is a crucial next step for multimodal large language models (MLLMs). To probe specific aspects of video understanding ability, existing video benchmarks typically require careful video selection based on the target capability, along with laborious annotation of query-response pairs to match the specific video content. This process is both challenging and resource-intensive. In this paper, we propose VideoNIAH (Video Needle In A Haystack), a benchmark construction framework through synthetic video generation. VideoNIAH decouples test video content from their query-responses by inserting unrelated image/text 'needles' into original videos. It generates annotations solely from these needles, ensuring diversity in video sources and a variety of query-responses. Additionally, by inserting multiple needles, VideoNIAH rigorously evaluates the temporal understanding capabilities of models. We utilized VideoNIAH to compile a video benchmark VNBench, including tasks such as retrieval, ordering, and counting. VNBench can efficiently evaluate the fine-grained understanding ability and spatio-temporal modeling ability of a video model, while also supporting the long-context evaluation. Additionally, we evaluated recent video-centric multimodal large language models (MLLMs), both open-source and proprietary, providing a comprehensive analysis. We found that although proprietary models have significant advantages over open-source models, all existing video models still perform poorly on long-distance dependency tasks. VideoNIAH is a simple yet highly scalable benchmark construction framework, and we believe it will inspire future video benchmark works. The code and data are available at https://github.com/joez17/VideoNIAH.
DeepSeek-VL: Towards Real-World Vision-Language Understanding
Mar 11, 2024



We present DeepSeek-VL, an open-source Vision-Language (VL) Model designed for real-world vision and language understanding applications. Our approach is structured around three key dimensions: We strive to ensure our data is diverse, scalable, and extensively covers real-world scenarios including web screenshots, PDFs, OCR, charts, and knowledge-based content, aiming for a comprehensive representation of practical contexts. Further, we create a use case taxonomy from real user scenarios and construct an instruction tuning dataset accordingly. The fine-tuning with this dataset substantially improves the model's user experience in practical applications. Considering efficiency and the demands of most real-world scenarios, DeepSeek-VL incorporates a hybrid vision encoder that efficiently processes high-resolution images (1024 x 1024), while maintaining a relatively low computational overhead. This design choice ensures the model's ability to capture critical semantic and detailed information across various visual tasks. We posit that a proficient Vision-Language Model should, foremost, possess strong language abilities. To ensure the preservation of LLM capabilities during pretraining, we investigate an effective VL pretraining strategy by integrating LLM training from the beginning and carefully managing the competitive dynamics observed between vision and language modalities. The DeepSeek-VL family (both 1.3B and 7B models) showcases superior user experiences as a vision-language chatbot in real-world applications, achieving state-of-the-art or competitive performance across a wide range of visual-language benchmarks at the same model size while maintaining robust performance on language-centric benchmarks. We have made both 1.3B and 7B models publicly accessible to foster innovations based on this foundation model.
DeepSeek LLM: Scaling Open-Source Language Models with Longtermism
Jan 05, 2024



The rapid development of open-source large language models (LLMs) has been truly remarkable. However, the scaling law described in previous literature presents varying conclusions, which casts a dark cloud over scaling LLMs. We delve into the study of scaling laws and present our distinctive findings that facilitate scaling of large scale models in two commonly used open-source configurations, 7B and 67B. Guided by the scaling laws, we introduce DeepSeek LLM, a project dedicated to advancing open-source language models with a long-term perspective. To support the pre-training phase, we have developed a dataset that currently consists of 2 trillion tokens and is continuously expanding. We further conduct supervised fine-tuning (SFT) and Direct Preference Optimization (DPO) on DeepSeek LLM Base models, resulting in the creation of DeepSeek Chat models. Our evaluation results demonstrate that DeepSeek LLM 67B surpasses LLaMA-2 70B on various benchmarks, particularly in the domains of code, mathematics, and reasoning. Furthermore, open-ended evaluations reveal that DeepSeek LLM 67B Chat exhibits superior performance compared to GPT-3.5.
speech and noise dual-stream spectrogram refine network with speech distortion loss for robust speech recognition
May 30, 2023In recent years, the joint training of speech enhancement front-end and automatic speech recognition (ASR) back-end has been widely used to improve the robustness of ASR systems. Traditional joint training methods only use enhanced speech as input for the backend. However, it is difficult for speech enhancement systems to directly separate speech from input due to the diverse types of noise with different intensities. Furthermore, speech distortion and residual noise are often observed in enhanced speech, and the distortion of speech and noise is different. Most existing methods focus on fusing enhanced and noisy features to address this issue. In this paper, we propose a dual-stream spectrogram refine network to simultaneously refine the speech and noise and decouple the noise from the noisy input. Our proposed method can achieve better performance with a relative 8.6% CER reduction.
VDT: An Empirical Study on Video Diffusion with Transformers
May 22, 2023This work introduces Video Diffusion Transformer (VDT), which pioneers the use of transformers in diffusion-based video generation. It features transformer blocks with modularized temporal and spatial attention modules, allowing separate optimization of each component and leveraging the rich spatial-temporal representation inherited from transformers. VDT offers several appealing benefits. 1) It excels at capturing temporal dependencies to produce temporally consistent video frames and even simulate the dynamics of 3D objects over time. 2) It enables flexible conditioning information through simple concatenation in the token space, effectively unifying video generation and prediction tasks. 3) Its modularized design facilitates a spatial-temporal decoupled training strategy, leading to improved efficiency. Extensive experiments on video generation, prediction, and dynamics modeling (i.e., physics-based QA) tasks have been conducted to demonstrate the effectiveness of VDT in various scenarios, including autonomous driving, human action, and physics-based simulation. We hope our study on the capabilities of transformer-based video diffusion in capturing accurate temporal dependencies, handling conditioning information, and achieving efficient training will benefit future research and advance the field. Codes and models are available at https://github.com/RERV/VDT.
UniAdapter: Unified Parameter-Efficient Transfer Learning for Cross-modal Modeling
Feb 13, 2023Large-scale vision-language pre-trained models have shown promising transferability to various downstream tasks. As the size of these foundation models and the number of downstream tasks grow, the standard full fine-tuning paradigm becomes unsustainable due to heavy computational and storage costs. This paper proposes UniAdapter, which unifies unimodal and multimodal adapters for parameter-efficient cross-modal adaptation on pre-trained vision-language models. Specifically, adapters are distributed to different modalities and their interactions, with the total number of tunable parameters reduced by partial weight sharing. The unified and knowledge-sharing design enables powerful cross-modal representations that can benefit various downstream tasks, requiring only 1.0%-2.0% tunable parameters of the pre-trained model. Extensive experiments on 6 cross-modal downstream benchmarks (including video-text retrieval, image-text retrieval, VideoQA, and VQA) show that in most cases, UniAdapter not only outperforms the state-of-the-arts, but even beats the full fine-tuning strategy. Particularly, on the MSRVTT retrieval task, UniAdapter achieves 49.7% recall@1 with 2.2% model parameters, outperforming the latest competitors by 2.0%. The code and models are available at https://github.com/RERV/UniAdapter.
Monolingual Recognizers Fusion for Code-switching Speech Recognition
Nov 02, 2022



The bi-encoder structure has been intensively investigated in code-switching (CS) automatic speech recognition (ASR). However, most existing methods require the structures of two monolingual ASR models (MAMs) should be the same and only use the encoder of MAMs. This leads to the problem that pre-trained MAMs cannot be timely and fully used for CS ASR. In this paper, we propose a monolingual recognizers fusion method for CS ASR. It has two stages: the speech awareness (SA) stage and the language fusion (LF) stage. In the SA stage, acoustic features are mapped to two language-specific predictions by two independent MAMs. To keep the MAMs focused on their own language, we further extend the language-aware training strategy for the MAMs. In the LF stage, the BELM fuses two language-specific predictions to get the final prediction. Moreover, we propose a text simulation strategy to simplify the training process of the BELM and reduce reliance on CS data. Experiments on a Mandarin-English corpus show the efficiency of the proposed method. The mix error rate is significantly reduced on the test set after using open-source pre-trained MAMs.
LGDN: Language-Guided Denoising Network for Video-Language Modeling
Oct 03, 2022
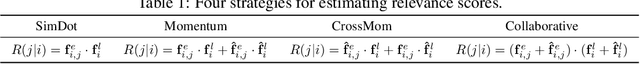
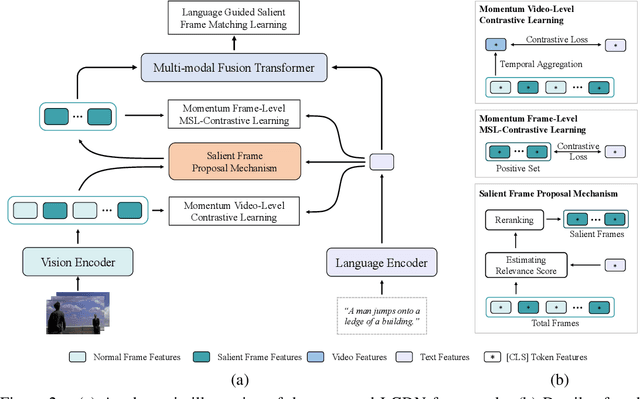
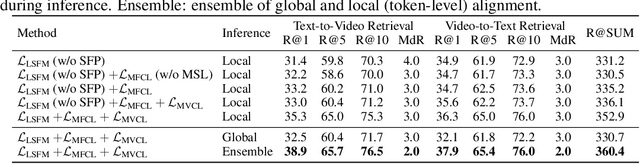
Video-language modeling has attracted much attention with the rapid growth of web videos. Most existing methods assume that the video frames and text description are semantically correlated, and focus on video-language modeling at video level. However, this hypothesis often fails for two reasons: (1) With the rich semantics of video contents, it is difficult to cover all frames with a single video-level description; (2) A raw video typically has noisy/meaningless information (e.g., scenery shot, transition or teaser). Although a number of recent works deploy attention mechanism to alleviate this problem, the irrelevant/noisy information still makes it very difficult to address. To overcome such challenge, we thus propose an efficient and effective model, termed Language-Guided Denoising Network (LGDN), for video-language modeling. Different from most existing methods that utilize all extracted video frames, LGDN dynamically filters out the misaligned or redundant frames under the language supervision and obtains only 2--4 salient frames per video for cross-modal token-level alignment. Extensive experiments on five public datasets show that our LGDN outperforms the state-of-the-arts by large margins. We also provide detailed ablation study to reveal the critical importance of solving the noise issue, in hope of inspiring future video-language work.