 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYoutu-Agent: Scaling Agent Productivity with Automated Generation and Hybrid Policy Optimization
Dec 31, 2025Existing Large Language Model (LLM) agent frameworks face two significant challenges: high configuration costs and static capabilities. Building a high-quality agent often requires extensive manual effort in tool integration and prompt engineering, while deployed agents struggle to adapt to dynamic environments without expensive fine-tuning. To address these issues, we propose \textbf{Youtu-Agent}, a modular framework designed for the automated generation and continuous evolution of LLM agents. Youtu-Agent features a structured configuration system that decouples execution environments, toolkits, and context management, enabling flexible reuse and automated synthesis. We introduce two generation paradigms: a \textbf{Workflow} mode for standard tasks and a \textbf{Meta-Agent} mode for complex, non-standard requirements, capable of automatically generating tool code, prompts, and configurations. Furthermore, Youtu-Agent establishes a hybrid policy optimization system: (1) an \textbf{Agent Practice} module that enables agents to accumulate experience and improve performance through in-context optimization without parameter updates; and (2) an \textbf{Agent RL} module that integrates with distributed training frameworks to enable scalable and stable reinforcement learning of any Youtu-Agents in an end-to-end, large-scale manner. Experiments demonstrate that Youtu-Agent achieves state-of-the-art performance on WebWalkerQA (71.47\%) and GAIA (72.8\%) using open-weight models. Our automated generation pipeline achieves over 81\% tool synthesis success rate, while the Practice module improves performance on AIME 2024/2025 by +2.7\% and +5.4\% respectively. Moreover, our Agent RL training achieves 40\% speedup with steady performance improvement on 7B LLMs, enhancing coding/reasoning and searching capabilities respectively up to 35\% and 21\% on Maths and general/multi-hop QA benchmarks.
Brain-inspired automated visual object discovery and detection
Sep 30, 2019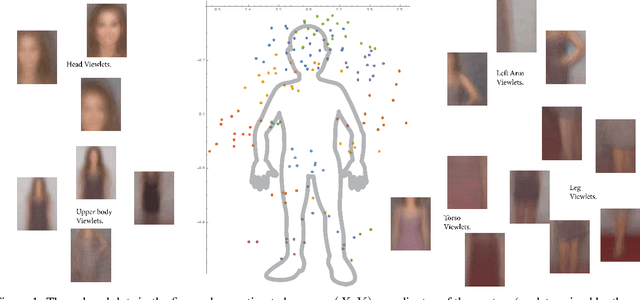
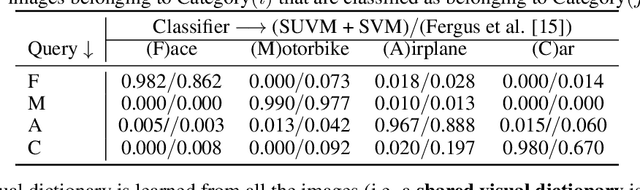
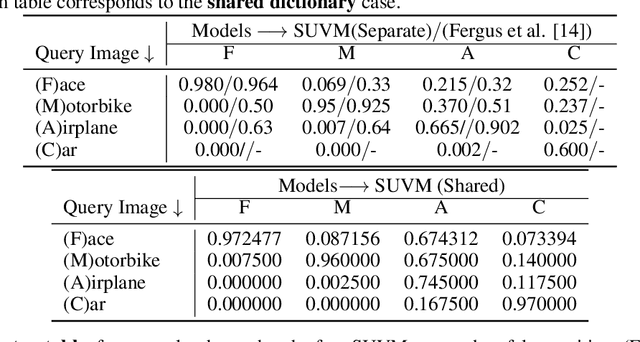

Despite significant recent progress, machine vision systems lag considerably behind their biological counterparts in performance, scalability, and robustness. A distinctive hallmark of the brain is its ability to automatically discover and model objects, at multiscale resolutions, from repeated exposures to unlabeled contextual data and then to be able to robustly detect the learned objects under various nonideal circumstances, such as partial occlusion and different view angles. Replication of such capabilities in a machine would require three key ingredients: (i) access to large-scale perceptual data of the kind that humans experience, (ii) flexible representations of objects, and (iii) an efficient unsupervised learning algorithm. The Internet fortunately provides unprecedented access to vast amounts of visual data. This paper leverages the availability of such data to develop a scalable framework for unsupervised learning of object prototypes--brain-inspired flexible, scale, and shift invariant representations of deformable objects (e.g., humans, motorcycles, cars, airplanes) comprised of parts, their different configurations and views, and their spatial relationships. Computationally, the object prototypes are represented as geometric associative networks using probabilistic constructs such as Markov random fields. We apply our framework to various datasets and show that our approach is computationally scalable and can construct accurate and operational part-aware object models much more efficiently than in much of the recent computer vision literature. We also present efficient algorithms for detection and localization in new scenes of objects and their partial views.