 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYoutu-VL: Unleashing Visual Potential via Unified Vision-Language Supervision
Jan 27, 2026Despite the significant advancements represented by Vision-Language Models (VLMs), current architectures often exhibit limitations in retaining fine-grained visual information, leading to coarse-grained multimodal comprehension. We attribute this deficiency to a suboptimal training paradigm inherent in prevailing VLMs, which exhibits a text-dominant optimization bias by conceptualizing visual signals merely as passive conditional inputs rather than supervisory targets. To mitigate this, we introduce Youtu-VL, a framework leveraging the Vision-Language Unified Autoregressive Supervision (VLUAS) paradigm, which fundamentally shifts the optimization objective from ``vision-as-input'' to ``vision-as-target.'' By integrating visual tokens directly into the prediction stream, Youtu-VL applies unified autoregressive supervision to both visual details and linguistic content. Furthermore, we extend this paradigm to encompass vision-centric tasks, enabling a standard VLM to perform vision-centric tasks without task-specific additions. Extensive empirical evaluations demonstrate that Youtu-VL achieves competitive performance on both general multimodal tasks and vision-centric tasks, establishing a robust foundation for the development of comprehensive generalist visual agents.
TACO: Think-Answer Consistency for Optimized Long-Chain Reasoning and Efficient Data Learning via Reinforcement Learning in LVLMs
May 27, 2025DeepSeek R1 has significantly advanced complex reasoning for large language models (LLMs). While recent methods have attempted to replicate R1's reasoning capabilities in multimodal settings, they face limitations, including inconsistencies between reasoning and final answers, model instability and crashes during long-chain exploration, and low data learning efficiency. To address these challenges, we propose TACO, a novel reinforcement learning algorithm for visual reasoning. Building on Generalized Reinforcement Policy Optimization (GRPO), TACO introduces Think-Answer Consistency, which tightly couples reasoning with answer consistency to ensure answers are grounded in thoughtful reasoning. We also introduce the Rollback Resample Strategy, which adaptively removes problematic samples and reintroduces them to the sampler, enabling stable long-chain exploration and future learning opportunities. Additionally, TACO employs an adaptive learning schedule that focuses on moderate difficulty samples to optimize data efficiency. Furthermore, we propose the Test-Time-Resolution-Scaling scheme to address performance degradation due to varying resolutions during reasoning while balancing computational overhead. Extensive experiments on in-distribution and out-of-distribution benchmarks for REC and VQA tasks show that fine-tuning LVLMs leads to significant performance improvements.
HRVDA: High-Resolution Visual Document Assistant
Apr 10, 2024



Leveraging vast training data, multimodal large language models (MLLMs) have demonstrated formidable general visual comprehension capabilities and achieved remarkable performance across various tasks. However, their performance in visual document understanding still leaves much room for improvement. This discrepancy is primarily attributed to the fact that visual document understanding is a fine-grained prediction task. In natural scenes, MLLMs typically use low-resolution images, leading to a substantial loss of visual information. Furthermore, general-purpose MLLMs do not excel in handling document-oriented instructions. In this paper, we propose a High-Resolution Visual Document Assistant (HRVDA), which bridges the gap between MLLMs and visual document understanding. This model employs a content filtering mechanism and an instruction filtering module to separately filter out the content-agnostic visual tokens and instruction-agnostic visual tokens, thereby achieving efficient model training and inference for high-resolution images. In addition, we construct a document-oriented visual instruction tuning dataset and apply a multi-stage training strategy to enhance the model's document modeling capabilities. Extensive experiments demonstrate that our model achieves state-of-the-art performance across multiple document understanding datasets, while maintaining training efficiency and inference speed comparable to low-resolution models.
Enhancing Visual Document Understanding with Contrastive Learning in Large Visual-Language Models
Feb 29, 2024



Recently, the advent of Large Visual-Language Models (LVLMs) has received increasing attention across various domains, particularly in the field of visual document understanding (VDU). Different from conventional vision-language tasks, VDU is specifically concerned with text-rich scenarios containing abundant document elements. Nevertheless, the importance of fine-grained features remains largely unexplored within the community of LVLMs, leading to suboptimal performance in text-rich scenarios. In this paper, we abbreviate it as the fine-grained feature collapse issue. With the aim of filling this gap, we propose a contrastive learning framework, termed Document Object COntrastive learning (DoCo), specifically tailored for the downstream tasks of VDU. DoCo leverages an auxiliary multimodal encoder to obtain the features of document objects and align them to the visual features generated by the vision encoder of LVLM, which enhances visual representation in text-rich scenarios. It can represent that the contrastive learning between the visual holistic representations and the multimodal fine-grained features of document objects can assist the vision encoder in acquiring more effective visual cues, thereby enhancing the comprehension of text-rich documents in LVLMs. We also demonstrate that the proposed DoCo serves as a plug-and-play pre-training method, which can be employed in the pre-training of various LVLMs without inducing any increase in computational complexity during the inference process. Extensive experimental results on multiple benchmarks of VDU reveal that LVLMs equipped with our proposed DoCo can achieve superior performance and mitigate the gap between VDU and generic vision-language tasks.
AudioFormer: Audio Transformer learns audio feature representations from discrete acoustic codes
Aug 25, 2023



We propose a method named AudioFormer,which learns audio feature representations through the acquisition of discrete acoustic codes and subsequently fine-tunes them for audio classification tasks. Initially,we introduce a novel perspective by considering the audio classification task as a form of natural language understanding (NLU). Leveraging an existing neural audio codec model,we generate discrete acoustic codes and utilize them to train a masked language model (MLM),thereby obtaining audio feature representations. Furthermore,we pioneer the integration of a Multi-Positive sample Contrastive (MPC) learning approach. This method enables the learning of joint representations among multiple discrete acoustic codes within the same audio input. In our experiments,we treat discrete acoustic codes as textual data and train a masked language model using a cloze-like methodology,ultimately deriving high-quality audio representations. Notably,the MPC learning technique effectively captures collaborative representations among distinct positive samples. Our research outcomes demonstrate that AudioFormer attains significantly improved performance compared to prevailing monomodal audio classification models across multiple datasets,and even outperforms audio-visual multimodal classification models on select datasets. Specifically,our approach achieves remarkable results on datasets including AudioSet (2M,20K),and FSD50K,with performance scores of 53.9,45.1,and 65.6,respectively. We have openly shared both the code and models: https://github.com/LZH-0225/AudioFormer.git.
OS-MSL: One Stage Multimodal Sequential Link Framework for Scene Segmentation and Classification
Jul 04, 2022
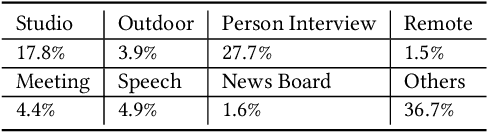
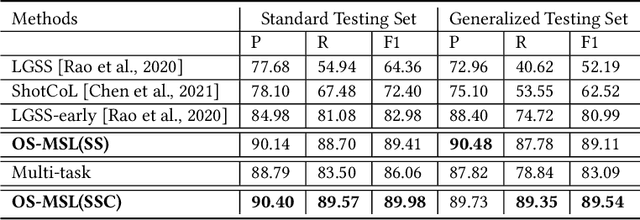
Scene segmentation and classification (SSC) serve as a critical step towards the field of video structuring analysis. Intuitively, jointly learning of these two tasks can promote each other by sharing common information. However, scene segmentation concerns more on the local difference between adjacent shots while classification needs the global representation of scene segments, which probably leads to the model dominated by one of the two tasks in the training phase. In this paper, from an alternate perspective to overcome the above challenges, we unite these two tasks into one task by a new form of predicting shots link: a link connects two adjacent shots, indicating that they belong to the same scene or category. To the end, we propose a general One Stage Multimodal Sequential Link Framework (OS-MSL) to both distinguish and leverage the two-fold semantics by reforming the two learning tasks into a unified one. Furthermore, we tailor a specific module called DiffCorrNet to explicitly extract the information of differences and correlations among shots. Extensive experiments on a brand-new large scale dataset collected from real-world applications, and MovieScenes are conducted. Both the results demonstrate the effectiveness of our proposed method against strong baselines.
The Devil is in the Frequency: Geminated Gestalt Autoencoder for Self-Supervised Visual Pre-Training
Apr 18, 2022
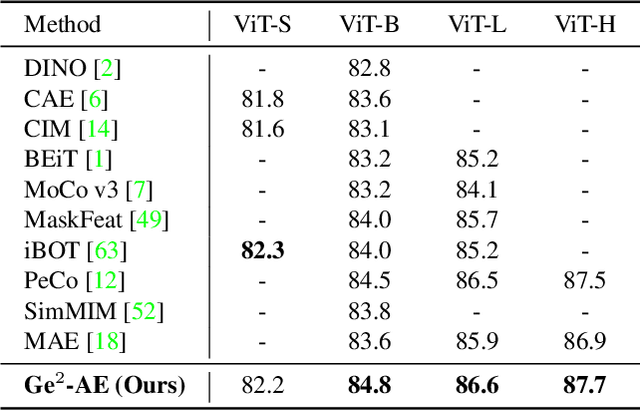
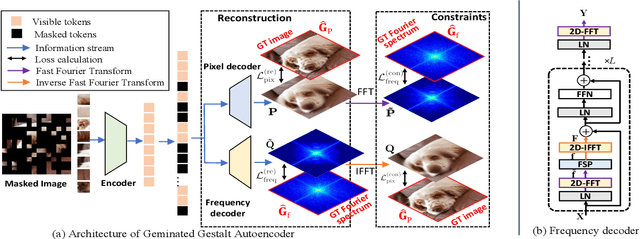
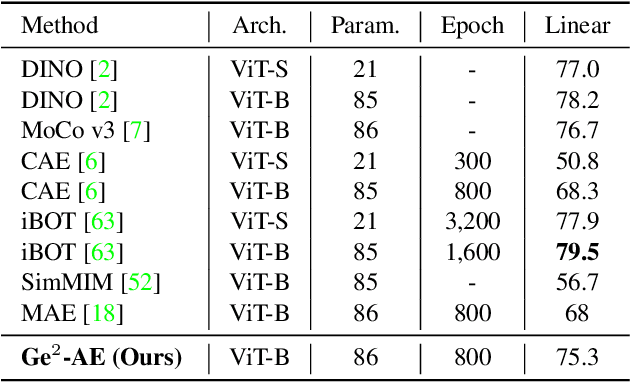
The self-supervised Masked Image Modeling (MIM) schema, following "mask-and-reconstruct" pipeline of recovering contents from masked image, has recently captured the increasing interest in the multimedia community, owing to the excellent ability of learning visual representation from unlabeled data. Aiming at learning representations with high semantics abstracted, a group of works attempts to reconstruct non-semantic pixels with large-ratio masking strategy, which may suffer from "over-smoothing" problem, while others directly infuse semantics into targets in off-line way requiring extra data. Different from them, we shift the perspective to the Fourier domain which naturally has global perspective and present a new Masked Image Modeling (MIM), termed Geminated Gestalt Autoencoder (Ge$^2$-AE) for visual pre-training. Specifically, we equip our model with geminated decoders in charge of reconstructing image contents from both pixel and frequency space, where each other serves as not only the complementation but also the reciprocal constraints. Through this way, more robust representations can be learned in the pre-trained encoders, of which the effectiveness is confirmed by the juxtaposing experimental results on downstream recognition tasks. We also conduct several quantitative and qualitative experiments to investigate the learning behavior of our method. To our best knowledge, this is the first MIM work to solve the visual pre-training through the lens of frequency domain.
NomMer: Nominate Synergistic Context in Vision Transformer for Visual Recognition
Nov 25, 2021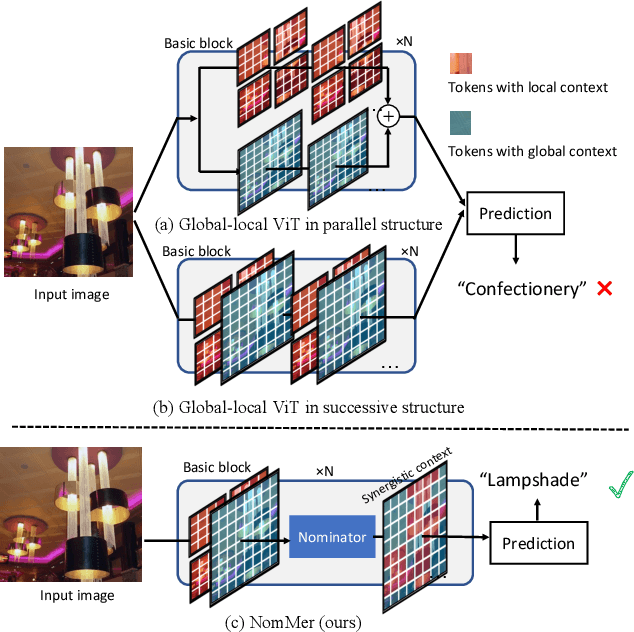
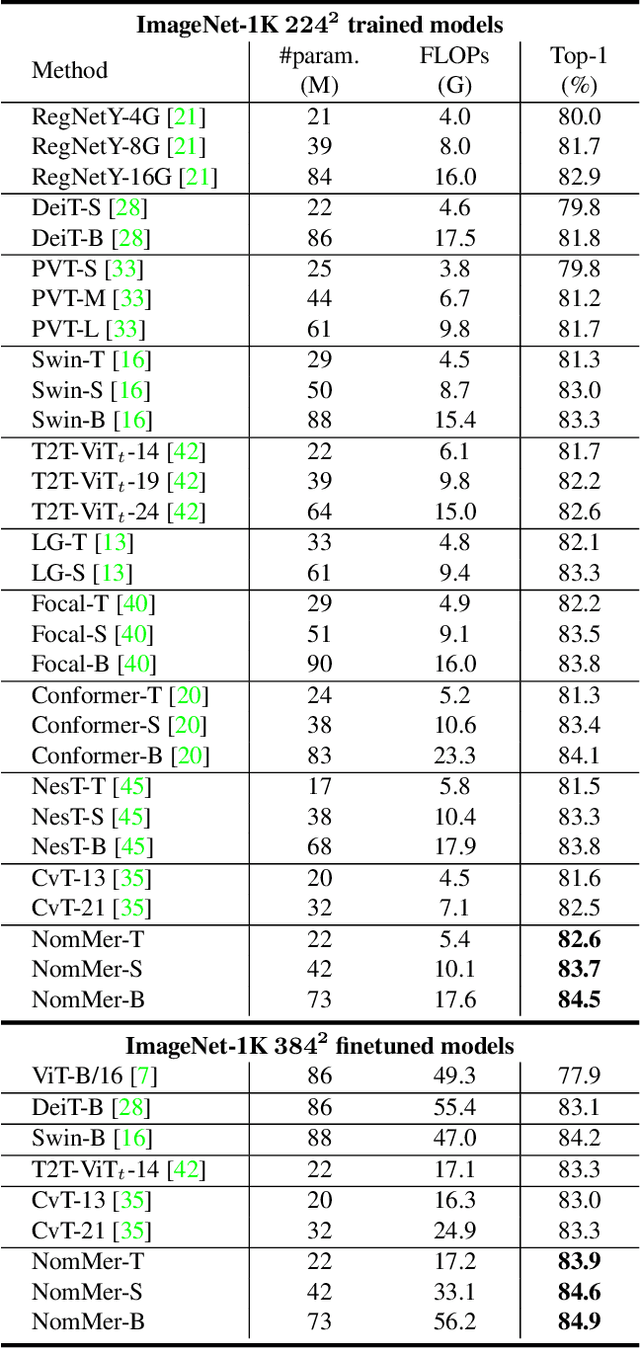
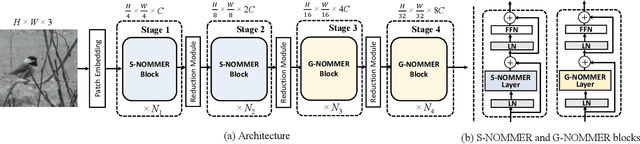
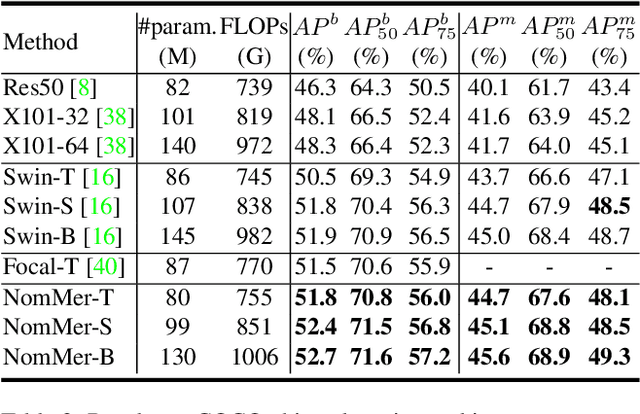
Recently, Vision Transformers (ViT), with the self-attention (SA) as the de facto ingredients, have demonstrated great potential in the computer vision community. For the sake of trade-off between efficiency and performance, a group of works merely perform SA operation within local patches, whereas the global contextual information is abandoned, which would be indispensable for visual recognition tasks. To solve the issue, the subsequent global-local ViTs take a stab at marrying local SA with global one in parallel or alternative way in the model. Nevertheless, the exhaustively combined local and global context may exist redundancy for various visual data, and the receptive field within each layer is fixed. Alternatively, a more graceful way is that global and local context can adaptively contribute per se to accommodate different visual data. To achieve this goal, we in this paper propose a novel ViT architecture, termed NomMer, which can dynamically Nominate the synergistic global-local context in vision transforMer. By investigating the working pattern of our proposed NomMer, we further explore what context information is focused. Beneficial from this "dynamic nomination" mechanism, without bells and whistles, the NomMer can not only achieve 84.5% Top-1 classification accuracy on ImageNet with only 73M parameters, but also show promising performance on dense prediction tasks, i.e., object detection and semantic segmentation. The code and models will be made publicly available at~\url{https://github.com/NomMer1125/NomMer.