 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast and Accurate Causal Parallel Decoding using Jacobi Forcing
Dec 16, 2025Multi-token generation has emerged as a promising paradigm for accelerating transformer-based large model inference. Recent efforts primarily explore diffusion Large Language Models (dLLMs) for parallel decoding to reduce inference latency. To achieve AR-level generation quality, many techniques adapt AR models into dLLMs to enable parallel decoding. However, they suffer from limited speedup compared to AR models due to a pretrain-to-posttrain mismatch. Specifically, the masked data distribution in post-training deviates significantly from the real-world data distribution seen during pretraining, and dLLMs rely on bidirectional attention, which conflicts with the causal prior learned during pretraining and hinders the integration of exact KV cache reuse. To address this, we introduce Jacobi Forcing, a progressive distillation paradigm where models are trained on their own generated parallel decoding trajectories, smoothly shifting AR models into efficient parallel decoders while preserving their pretrained causal inference property. The models trained under this paradigm, Jacobi Forcing Model, achieves 3.8x wall-clock speedup on coding and math benchmarks with minimal loss in performance. Based on Jacobi Forcing Models' trajectory characteristics, we introduce multi-block decoding with rejection recycling, which enables up to 4.5x higher token acceptance count per iteration and nearly 4.0x wall-clock speedup, effectively trading additional compute for lower inference latency. Our code is available at https://github.com/hao-ai-lab/JacobiForcing.
Zero-shot 3D Map Generation with LLM Agents: A Dual-Agent Architecture for Procedural Content Generation
Dec 12, 2025



Procedural Content Generation (PCG) offers scalable methods for algorithmically creating complex, customizable worlds. However, controlling these pipelines requires the precise configuration of opaque technical parameters. We propose a training-free architecture that utilizes LLM agents for zero-shot PCG parameter configuration. While Large Language Models (LLMs) promise a natural language interface for PCG tools, off-the-shelf models often fail to bridge the semantic gap between abstract user instructions and strict parameter specifications. Our system pairs an Actor agent with a Critic agent, enabling an iterative workflow where the system autonomously reasons over tool parameters and refines configurations to progressively align with human design preferences. We validate this approach on the generation of various 3D maps, establishing a new benchmark for instruction-following in PCG. Experiments demonstrate that our approach outperforms single-agent baselines, producing diverse and structurally valid environments from natural language descriptions. These results demonstrate that off-the-shelf LLMs can be effectively repurposed as generalized agents for arbitrary PCG tools. By shifting the burden from model training to architectural reasoning, our method offers a scalable framework for mastering complex software without task-specific fine-tuning.
TSkel-Mamba: Temporal Dynamic Modeling via State Space Model for Human Skeleton-based Action Recognition
Dec 12, 2025Skeleton-based action recognition has garnered significant attention in the computer vision community. Inspired by the recent success of the selective state-space model (SSM) Mamba in modeling 1D temporal sequences, we propose TSkel-Mamba, a hybrid Transformer-Mamba framework that effectively captures both spatial and temporal dynamics. In particular, our approach leverages Spatial Transformer for spatial feature learning while utilizing Mamba for temporal modeling. Mamba, however, employs separate SSM blocks for individual channels, which inherently limits its ability to model inter-channel dependencies. To better adapt Mamba for skeleton data and enhance Mamba`s ability to model temporal dependencies, we introduce a Temporal Dynamic Modeling (TDM) block, which is a versatile plug-and-play component that integrates a novel Multi-scale Temporal Interaction (MTI) module. The MTI module employs multi-scale Cycle operators to capture cross-channel temporal interactions, a critical factor in action recognition. Extensive experiments on NTU-RGB+D 60, NTU-RGB+D 120, NW-UCLA and UAV-Human datasets demonstrate that TSkel-Mamba achieves state-of-the-art performance while maintaining low inference time, making it both efficient and highly effective.
VP-AutoTest: A Virtual-Physical Fusion Autonomous Driving Testing Platform
Dec 08, 2025The rapid development of autonomous vehicles has led to a surge in testing demand. Traditional testing methods, such as virtual simulation, closed-course, and public road testing, face several challenges, including unrealistic vehicle states, limited testing capabilities, and high costs. These issues have prompted increasing interest in virtual-physical fusion testing. However, despite its potential, virtual-physical fusion testing still faces challenges, such as limited element types, narrow testing scope, and fixed evaluation metrics. To address these challenges, we propose the Virtual-Physical Testing Platform for Autonomous Vehicles (VP-AutoTest), which integrates over ten types of virtual and physical elements, including vehicles, pedestrians, and roadside infrastructure, to replicate the diversity of real-world traffic participants. The platform also supports both single-vehicle interaction and multi-vehicle cooperation testing, employing adversarial testing and parallel deduction to accelerate fault detection and explore algorithmic limits, while OBU and Redis communication enable seamless vehicle-to-vehicle (V2V) and vehicle-to-infrastructure (V2I) cooperation across all levels of cooperative automation. Furthermore, VP-AutoTest incorporates a multidimensional evaluation framework and AI-driven expert systems to conduct comprehensive performance assessment and defect diagnosis. Finally, by comparing virtual-physical fusion test results with real-world experiments, the platform performs credibility self-evaluation to ensure both the fidelity and efficiency of autonomous driving testing. Please refer to the website for the full testing functionalities on the autonomous driving public service platform OnSite:https://www.onsite.com.cn.
Auden-Voice: General-Purpose Voice Encoder for Speech and Language Understanding
Nov 19, 2025Human voice encodes both identity and paralinguistic cues, yet encoders in large audio-language models (LALMs) rarely balance both aspects. In this work, we present a study toward building a general-purpose voice encoder that captures nuanced voice cues. Through a comprehensive evaluation, we find that multi-task training yields the most balanced representations, whereas contrastive language-audio pretraining (CLAP) primarily improves retrieval without enhancing paralinguistic understanding. Our final encoder, Auden-Voice, also demonstrates strong performance when integrated with LLMs. The code and training recipes will be released with the audio understanding toolkit Auden.
Hierarchical Transformers for Unsupervised 3D Shape Abstraction
Oct 31, 2025We introduce HiT, a novel hierarchical neural field representation for 3D shapes that learns general hierarchies in a coarse-to-fine manner across different shape categories in an unsupervised setting. Our key contribution is a hierarchical transformer (HiT), where each level learns parent-child relationships of the tree hierarchy using a compressed codebook. This codebook enables the network to automatically identify common substructures across potentially diverse shape categories. Unlike previous works that constrain the task to a fixed hierarchical structure (e.g., binary), we impose no such restriction, except for limiting the total number of nodes at each tree level. This flexibility allows our method to infer the hierarchical structure directly from data, over multiple shape categories, and representing more general and complex hierarchies than prior approaches. When trained at scale with a reconstruction loss, our model captures meaningful containment relationships between parent and child nodes. We demonstrate its effectiveness through an unsupervised shape segmentation task over all 55 ShapeNet categories, where our method successfully segments shapes into multiple levels of granularity.
Real Deep Research for AI, Robotics and Beyond
Oct 23, 2025



With the rapid growth of research in AI and robotics now producing over 10,000 papers annually it has become increasingly difficult for researchers to stay up to date. Fast evolving trends, the rise of interdisciplinary work, and the need to explore domains beyond one's expertise all contribute to this challenge. To address these issues, we propose a generalizable pipeline capable of systematically analyzing any research area: identifying emerging trends, uncovering cross domain opportunities, and offering concrete starting points for new inquiry. In this work, we present Real Deep Research (RDR) a comprehensive framework applied to the domains of AI and robotics, with a particular focus on foundation models and robotics advancements. We also briefly extend our analysis to other areas of science. The main paper details the construction of the RDR pipeline, while the appendix provides extensive results across each analyzed topic. We hope this work sheds light for researchers working in the field of AI and beyond.
Advances in 4D Representation: Geometry, Motion, and Interaction
Oct 22, 2025We present a survey on 4D generation and reconstruction, a fast-evolving subfield of computer graphics whose developments have been propelled by recent advances in neural fields, geometric and motion deep learning, as well 3D generative artificial intelligence (GenAI). While our survey is not the first of its kind, we build our coverage of the domain from a unique and distinctive perspective of 4D representations\/}, to model 3D geometry evolving over time while exhibiting motion and interaction. Specifically, instead of offering an exhaustive enumeration of many works, we take a more selective approach by focusing on representative works to highlight both the desirable properties and ensuing challenges of each representation under different computation, application, and data scenarios. The main take-away message we aim to convey to the readers is on how to select and then customize the appropriate 4D representations for their tasks. Organizationally, we separate the 4D representations based on three key pillars: geometry, motion, and interaction. Our discourse will not only encompass the most popular representations of today, such as neural radiance fields (NeRFs) and 3D Gaussian Splatting (3DGS), but also bring attention to relatively under-explored representations in the 4D context, such as structured models and long-range motions. Throughout our survey, we will reprise the role of large language models (LLMs) and video foundational models (VFMs) in a variety of 4D applications, while steering our discussion towards their current limitations and how they can be addressed. We also provide a dedicated coverage on what 4D datasets are currently available, as well as what is lacking, in driving the subfield forward. Project page:https://mingrui-zhao.github.io/4DRep-GMI/
Maritime Communication in Evaporation Duct Environment with Ship Trajectory Optimization
Oct 08, 2025



In maritime wireless networks, the evaporation duct effect has been known as a preferable condition for long-range transmissions. However, how to effectively utilize the duct effect for efficient communication design is still open for investigation. In this paper, we consider a typical scenario of ship-to-shore data transmission, where a ship collects data from multiple oceanographic buoys, sails from one to another, and transmits the collected data back to a terrestrial base station during its voyage. A novel framework, which exploits priori information of the channel gain map in the presence of evaporation duct, is proposed to minimize the data transmission time and the sailing time by optimizing the ship's trajectory. To this end, a multi-objective optimization problem is formulated and is further solved by a dynamic population PSO-integrated NSGA-II algorithm. Through simulations, it is demonstrated that, compared to the benchmark scheme which ignores useful information of the evaporation duct, the proposed scheme can effectively reduce both the data transmission time and the sailing time.
Towards Interpretable and Inference-Optimal COT Reasoning with Sparse Autoencoder-Guided Generation
Oct 02, 2025

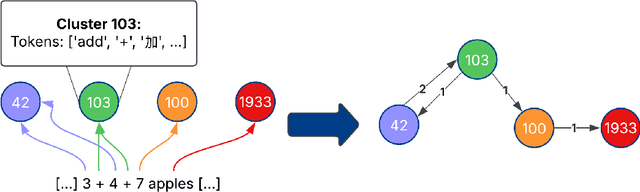

We propose a novel method that leverages sparse autoencoders (SAEs) and clustering techniques to analyze the internal token representations of large language models (LLMs) and guide generations in mathematical reasoning tasks. Our approach first trains an SAE to generate sparse vector representations for training tokens, then applies k-means clustering to construct a graph where vertices represent token clusters and weighted edges capture sequential token transitions. Using this graph, we define an edge-weight based reward function to quantify adherence to established reasoning traces, thereby identifying exploitative reasoning trajectories. Additionally, we measure generation diversity from clustering to assess the extent of exploration. Our findings indicate that balancing both exploitation and exploration is crucial for achieving high accuracy in mathematical reasoning tasks. During generation, the SAE can serve as a scalable reward model to guide generations, ensuring a balanced trade-off between exploitation and exploration. This prevents extreme behaviors in either direction, ultimately fostering a higher-quality reasoning process in LLMs.