 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePC-Talk: Precise Facial Animation Control for Audio-Driven Talking Face Generation
Mar 20, 2025Recent advancements in audio-driven talking face generation have made great progress in lip synchronization. However, current methods often lack sufficient control over facial animation such as speaking style and emotional expression, resulting in uniform outputs. In this paper, we focus on improving two key factors: lip-audio alignment and emotion control, to enhance the diversity and user-friendliness of talking videos. Lip-audio alignment control focuses on elements like speaking style and the scale of lip movements, whereas emotion control is centered on generating realistic emotional expressions, allowing for modifications in multiple attributes such as intensity. To achieve precise control of facial animation, we propose a novel framework, PC-Talk, which enables lip-audio alignment and emotion control through implicit keypoint deformations. First, our lip-audio alignment control module facilitates precise editing of speaking styles at the word level and adjusts lip movement scales to simulate varying vocal loudness levels, maintaining lip synchronization with the audio. Second, our emotion control module generates vivid emotional facial features with pure emotional deformation. This module also enables the fine modification of intensity and the combination of multiple emotions across different facial regions. Our method demonstrates outstanding control capabilities and achieves state-of-the-art performance on both HDTF and MEAD datasets in extensive experiments.
UniHOPE: A Unified Approach for Hand-Only and Hand-Object Pose Estimation
Mar 17, 2025

Estimating the 3D pose of hand and potential hand-held object from monocular images is a longstanding challenge. Yet, existing methods are specialized, focusing on either bare-hand or hand interacting with object. No method can flexibly handle both scenarios and their performance degrades when applied to the other scenario. In this paper, we propose UniHOPE, a unified approach for general 3D hand-object pose estimation, flexibly adapting both scenarios. Technically, we design a grasp-aware feature fusion module to integrate hand-object features with an object switcher to dynamically control the hand-object pose estimation according to grasping status. Further, to uplift the robustness of hand pose estimation regardless of object presence, we generate realistic de-occluded image pairs to train the model to learn object-induced hand occlusions, and formulate multi-level feature enhancement techniques for learning occlusion-invariant features. Extensive experiments on three commonly-used benchmarks demonstrate UniHOPE's SOTA performance in addressing hand-only and hand-object scenarios. Code will be released on https://github.com/JoyboyWang/UniHOPE_Pytorch.
Simulating Dual-Pixel Images From Ray Tracing For Depth Estimation
Mar 14, 2025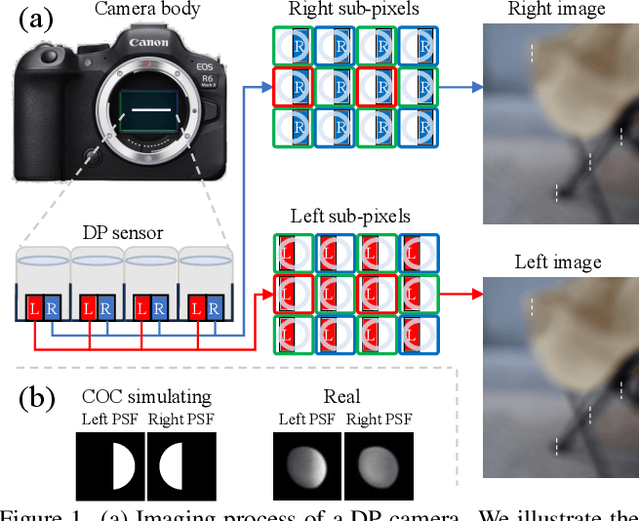
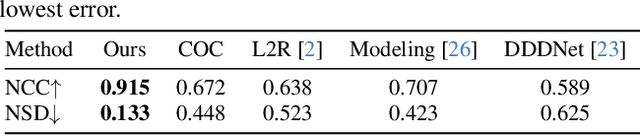
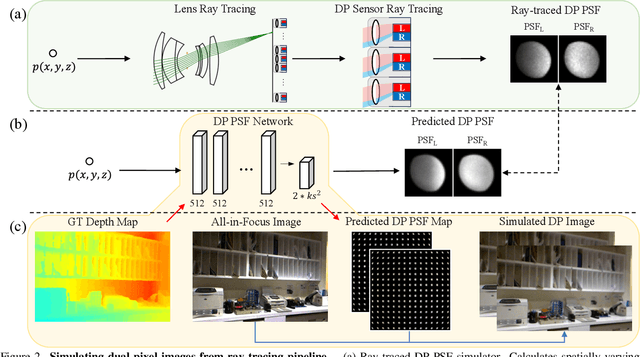
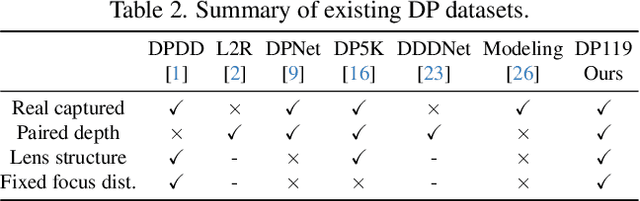
Many studies utilize dual-pixel (DP) sensor phase characteristics for various applications, such as depth estimation and deblurring. However, since the DP image features are entirely determined by the camera hardware, DP-depth paired datasets are very scarce, especially when performing depth estimation on customized cameras. To overcome this, studies simulate DP images using ideal optical system models. However, these simulations often violate real optical propagation laws,leading to poor generalization to real DP data. To address this, we investigate the domain gap between simulated and real DP data, and propose solutions using the Simulating DP images from ray tracing (Sdirt) scheme. The Sdirt generates realistic DP images via ray tracing and integrates them into the depth estimation training pipeline. Experimental results show that models trained with Sdirt-simulated images generalize better to real DP data.
HybridReg: Robust 3D Point Cloud Registration with Hybrid Motions
Mar 10, 2025



Scene-level point cloud registration is very challenging when considering dynamic foregrounds. Existing indoor datasets mostly assume rigid motions, so the trained models cannot robustly handle scenes with non-rigid motions. On the other hand, non-rigid datasets are mainly object-level, so the trained models cannot generalize well to complex scenes. This paper presents HybridReg, a new approach to 3D point cloud registration, learning uncertainty mask to account for hybrid motions: rigid for backgrounds and non-rigid/rigid for instance-level foregrounds. First, we build a scene-level 3D registration dataset, namely HybridMatch, designed specifically with strategies to arrange diverse deforming foregrounds in a controllable manner. Second, we account for different motion types and formulate a mask-learning module to alleviate the interference of deforming outliers. Third, we exploit a simple yet effective negative log-likelihood loss to adopt uncertainty to guide the feature extraction and correlation computation. To our best knowledge, HybridReg is the first work that exploits hybrid motions for robust point cloud registration. Extensive experiments show HybridReg's strengths, leading it to achieve state-of-the-art performance on both widely-used indoor and outdoor datasets.
MultiCo3D: Multi-Label Voxel Contrast for One-Shot Incremental Segmentation of 3D Neuroimages
Mar 09, 20253D neuroimages provide a comprehensive view of brain structure and function, aiding in precise localization and functional connectivity analysis. Segmentation of white matter (WM) tracts using 3D neuroimages is vital for understanding the brain's structural connectivity in both healthy and diseased states. One-shot Class Incremental Semantic Segmentation (OCIS) refers to effectively segmenting new (novel) classes using only a single sample while retaining knowledge of old (base) classes without forgetting. Voxel-contrastive OCIS methods adjust the feature space to alleviate the feature overlap problem between the base and novel classes. However, since WM tract segmentation is a multi-label segmentation task, existing single-label voxel contrastive-based methods may cause inherent contradictions. To address this, we propose a new multi-label voxel contrast framework called MultiCo3D for one-shot class incremental tract segmentation. Our method utilizes uncertainty distillation to preserve base tract segmentation knowledge while adjusting the feature space with multi-label voxel contrast to alleviate feature overlap when learning novel tracts and dynamically weighting multi losses to balance overall loss. We compare our method against several state-of-the-art (SOTA) approaches. The experimental results show that our method significantly enhances one-shot class incremental tract segmentation accuracy across five different experimental setups on HCP and Preto datasets.
Fluid Antenna System Empowering 5G NR
Mar 07, 2025Fluid antenna system (FAS) is an emerging technology that uses the new form of shape- and position-reconfigurable antennas to empower the physical layer for wireless communications. Prior studies on FAS were however limited to narrowband channels. Motivated by this, this paper addresses the integration of FAS in the fifth generation (5G) orthogonal frequency division multiplexing (OFDM) framework to address the challenges posed by wideband communications. We propose the framework of the wideband FAS OFDM system that includes a novel port selection matrix. Then we derive the achievable rate expression and design the adaptive modulation and coding (AMC) scheme based on the rate. Extensive link-level simulation results demonstrate striking improvements of FAS in the wideband channels, underscoring the potential of FAS in future wireless communications.
Collab-Overcooked: Benchmarking and Evaluating Large Language Models as Collaborative Agents
Feb 27, 2025



Large language models (LLMs) based agent systems have made great strides in real-world applications beyond traditional NLP tasks. This paper proposes a new LLM-powered Multi-Agent System (LLM-MAS) benchmark, Collab-Overcooked, built on the popular Overcooked-AI game with more applicable and challenging tasks in interactive environments. Collab-Overcooked extends existing benchmarks from two novel perspectives. First, it provides a multi-agent framework supporting diverse tasks and objectives and encourages collaboration through natural language communication. Second, it introduces a spectrum of process-oriented evaluation metrics to assess the fine-grained collaboration capabilities of different LLM agents, a dimension often overlooked in prior work. We conduct extensive experiments over 10 popular LLMs and show that, while the LLMs present a strong ability in goal interpretation, there is a significant discrepancy in active collaboration and continuous adaption that are critical for efficiently fulfilling complicated tasks. Notably, we highlight the strengths and weaknesses in LLM-MAS and provide insights for improving and evaluating LLM-MAS on a unified and open-sourced benchmark. Environments, 30 open-ended tasks, and an integrated evaluation package are now publicly available at https://github.com/YusaeMeow/Collab-Overcooked.
Medical Image Registration Meets Vision Foundation Model: Prototype Learning and Contour Awareness
Feb 17, 2025Medical image registration is a fundamental task in medical image analysis, aiming to establish spatial correspondences between paired images. However, existing unsupervised deformable registration methods rely solely on intensity-based similarity metrics, lacking explicit anatomical knowledge, which limits their accuracy and robustness. Vision foundation models, such as the Segment Anything Model (SAM), can generate high-quality segmentation masks that provide explicit anatomical structure knowledge, addressing the limitations of traditional methods that depend only on intensity similarity. Based on this, we propose a novel SAM-assisted registration framework incorporating prototype learning and contour awareness. The framework includes: (1) Explicit anatomical information injection, where SAM-generated segmentation masks are used as auxiliary inputs throughout training and testing to ensure the consistency of anatomical information; (2) Prototype learning, which leverages segmentation masks to extract prototype features and aligns prototypes to optimize semantic correspondences between images; and (3) Contour-aware loss, a contour-aware loss is designed that leverages the edges of segmentation masks to improve the model's performance in fine-grained deformation fields. Extensive experiments demonstrate that the proposed framework significantly outperforms existing methods across multiple datasets, particularly in challenging scenarios with complex anatomical structures and ambiguous boundaries. Our code is available at https://github.com/HaoXu0507/IPMI25-SAM-Assisted-Registration.
Fast Inventory for 3GPP Ambient IoT Considering Device Unavailability due to Energy Harvesting
Jan 25, 2025



With the growing demand for massive internet of things (IoT), new IoT technology, namely ambient IoT (A-IoT), has been studied in the 3rd Generation Partnership Project (3GPP). A-IoT devices are batteryless and consume ultra-low power, relying on energy harvesting and energy storage to capture a small amount of energy for communication. A promising usecase of A-IoT is inventory, where a reader communicates with hundreds of A-IoT devices to identify them. However, energy harvesting required before communication can significantly delay or even fail inventory completion. In this work, solutions including duty cycled monitoring (DCM), device grouping and low-power receiving chain are proposed. Evaluation results show that the time required for a reader to complete an inventory procedure for hundreds of A-IoT devices can be reduced by 50% to 83% with the proposed methods.
How to Complete Domain Tuning while Keeping General Ability in LLM: Adaptive Layer-wise and Element-wise Regularization
Jan 23, 2025Large Language Models (LLMs) exhibit strong general-purpose language capabilities. However, fine-tuning these models on domain-specific tasks often leads to catastrophic forgetting, where the model overwrites or loses essential knowledge acquired during pretraining. This phenomenon significantly limits the broader applicability of LLMs. To address this challenge, we propose a novel approach to compute the element-wise importance of model parameters crucial for preserving general knowledge during fine-tuning. Our method utilizes a dual-objective optimization strategy: (1) regularization loss to retain the parameter crucial for general knowledge; (2) cross-entropy loss to adapt to domain-specific tasks. Additionally, we introduce layer-wise coefficients to account for the varying contributions of different layers, dynamically balancing the dual-objective optimization. Extensive experiments on scientific, medical, and physical tasks using GPT-J and LLaMA-3 demonstrate that our approach mitigates catastrophic forgetting while enhancing model adaptability. Compared to previous methods, our solution is approximately 20 times faster and requires only 10%-15% of the storage, highlighting the practical efficiency. The code will be released.