 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHao Wang
A Density-Guided Temporal Attention Transformer for Indiscernible Object Counting in Underwater Video
Mar 06, 2024

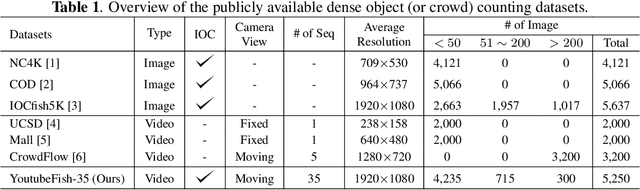
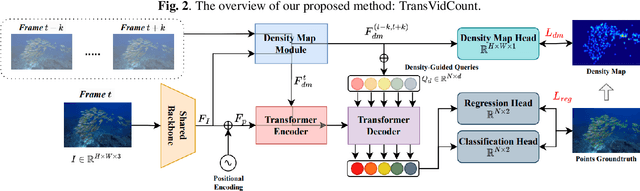

Dense object counting or crowd counting has come a long way thanks to the recent development in the vision community. However, indiscernible object counting, which aims to count the number of targets that are blended with respect to their surroundings, has been a challenge. Image-based object counting datasets have been the mainstream of the current publicly available datasets. Therefore, we propose a large-scale dataset called YoutubeFish-35, which contains a total of 35 sequences of high-definition videos with high frame-per-second and more than 150,000 annotated center points across a selected variety of scenes. For benchmarking purposes, we select three mainstream methods for dense object counting and carefully evaluate them on the newly collected dataset. We propose TransVidCount, a new strong baseline that combines density and regression branches along the temporal domain in a unified framework and can effectively tackle indiscernible object counting with state-of-the-art performance on YoutubeFish-35 dataset.
Mixture-of-LoRAs: An Efficient Multitask Tuning for Large Language Models
Mar 06, 2024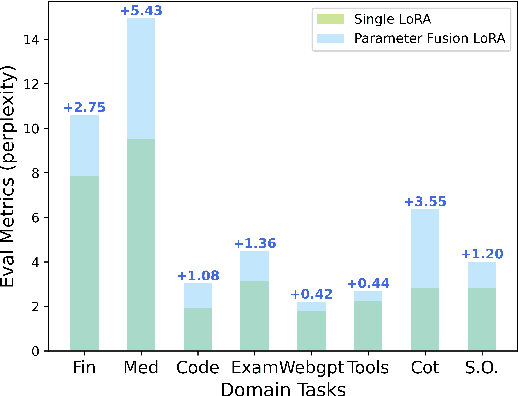

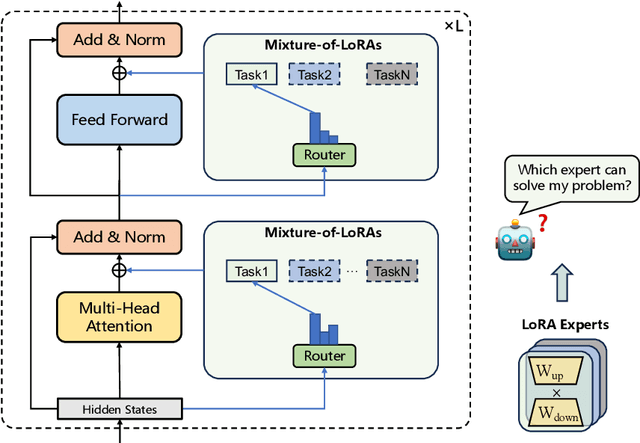
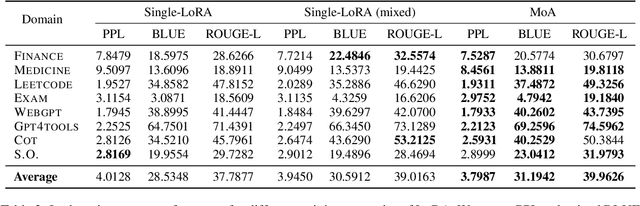
Instruction Tuning has the potential to stimulate or enhance specific capabilities of large language models (LLMs). However, achieving the right balance of data is crucial to prevent catastrophic forgetting and interference between tasks. To address these limitations and enhance training flexibility, we propose the Mixture-of-LoRAs (MoA) architecture which is a novel and parameter-efficient tuning method designed for multi-task learning with LLMs. In this paper, we start by individually training multiple domain-specific LoRA modules using corresponding supervised corpus data. These LoRA modules can be aligned with the expert design principles observed in Mixture-of-Experts (MoE). Subsequently, we combine the multiple LoRAs using an explicit routing strategy and introduce domain labels to facilitate multi-task learning, which help prevent interference between tasks and ultimately enhances the performance of each individual task. Furthermore, each LoRA model can be iteratively adapted to a new domain, allowing for quick domain-specific adaptation. Experiments on diverse tasks demonstrate superior and robust performance, which can further promote the wide application of domain-specific LLMs.
Temporal-Aware Deep Reinforcement Learning for Energy Storage Bidding in Energy and Contingency Reserve Markets
Feb 29, 2024The battery energy storage system (BESS) has immense potential for enhancing grid reliability and security through its participation in the electricity market. BESS often seeks various revenue streams by taking part in multiple markets to unlock its full potential, but effective algorithms for joint-market participation under price uncertainties are insufficiently explored in the existing research. To bridge this gap, we develop a novel BESS joint bidding strategy that utilizes deep reinforcement learning (DRL) to bid in the spot and contingency frequency control ancillary services (FCAS) markets. Our approach leverages a transformer-based temporal feature extractor to effectively respond to price fluctuations in seven markets simultaneously and helps DRL learn the best BESS bidding strategy in joint-market participation. Additionally, unlike conventional "black-box" DRL model, our approach is more interpretable and provides valuable insights into the temporal bidding behavior of BESS in the dynamic electricity market. We validate our method using realistic market prices from the Australian National Electricity Market. The results show that our strategy outperforms benchmarks, including both optimization-based and other DRL-based strategies, by substantial margins. Our findings further suggest that effective temporal-aware bidding can significantly increase profits in the spot and contingency FCAS markets compared to individual market participation.
* 15 pages
DOZE: A Dataset for Open-Vocabulary Zero-Shot Object Navigation in Dynamic Environments
Feb 29, 2024Zero-Shot Object Navigation (ZSON) requires agents to autonomously locate and approach unseen objects in unfamiliar environments and has emerged as a particularly challenging task within the domain of Embodied AI. Existing datasets for developing ZSON algorithms lack consideration of dynamic obstacles, object attribute diversity, and scene texts, thus exhibiting noticeable discrepancy from real-world situations. To address these issues, we propose a Dataset for Open-Vocabulary Zero-Shot Object Navigation in Dynamic Environments (DOZE) that comprises ten high-fidelity 3D scenes with over 18k tasks, aiming to mimic complex, dynamic real-world scenarios. Specifically, DOZE scenes feature multiple moving humanoid obstacles, a wide array of open-vocabulary objects, diverse distinct-attribute objects, and valuable textual hints. Besides, different from existing datasets that only provide collision checking between the agent and static obstacles, we enhance DOZE by integrating capabilities for detecting collisions between the agent and moving obstacles. This novel functionality enables evaluation of the agents' collision avoidance abilities in dynamic environments. We test four representative ZSON methods on DOZE, revealing substantial room for improvement in existing approaches concerning navigation efficiency, safety, and object recognition accuracy. Our dataset could be found at https://DOZE-Dataset.github.io/.
All in a Single Image: Large Multimodal Models are In-Image Learners
Feb 28, 2024This paper introduces a new in-context learning (ICL) mechanism called In-Image Learning (I$^2$L) that combines demonstration examples, visual cues, and instructions into a single image to enhance the capabilities of GPT-4V. Unlike previous approaches that rely on converting images to text or incorporating visual input into language models, I$^2$L consolidates all information into one image and primarily leverages image processing, understanding, and reasoning abilities. This has several advantages: it avoids inaccurate textual descriptions of complex images, provides flexibility in positioning demonstration examples, reduces the input burden, and avoids exceeding input limits by eliminating the need for multiple images and lengthy text. To further combine the strengths of different ICL methods, we introduce an automatic strategy to select the appropriate ICL method for a data example in a given task. We conducted experiments on MathVista and Hallusionbench to test the effectiveness of I$^2$L in complex multimodal reasoning tasks and mitigating language hallucination and visual illusion. Additionally, we explored the impact of image resolution, the number of demonstration examples, and their positions on the effectiveness of I$^2$L. Our code is publicly available at https://github.com/AGI-Edgerunners/IIL.
CLAP: Learning Transferable Binary Code Representations with Natural Language Supervision
Feb 26, 2024Binary code representation learning has shown significant performance in binary analysis tasks. But existing solutions often have poor transferability, particularly in few-shot and zero-shot scenarios where few or no training samples are available for the tasks. To address this problem, we present CLAP (Contrastive Language-Assembly Pre-training), which employs natural language supervision to learn better representations of binary code (i.e., assembly code) and get better transferability. At the core, our approach boosts superior transfer learning capabilities by effectively aligning binary code with their semantics explanations (in natural language), resulting a model able to generate better embeddings for binary code. To enable this alignment training, we then propose an efficient dataset engine that could automatically generate a large and diverse dataset comprising of binary code and corresponding natural language explanations. We have generated 195 million pairs of binary code and explanations and trained a prototype of CLAP. The evaluations of CLAP across various downstream tasks in binary analysis all demonstrate exceptional performance. Notably, without any task-specific training, CLAP is often competitive with a fully supervised baseline, showing excellent transferability. We release our pre-trained model and code at https://github.com/Hustcw/CLAP.
Gradient-Guided Modality Decoupling for Missing-Modality Robustness
Feb 26, 2024Multimodal learning with incomplete input data (missing modality) is practical and challenging. In this work, we conduct an in-depth analysis of this challenge and find that modality dominance has a significant negative impact on the model training, greatly degrading the missing modality performance. Motivated by Grad-CAM, we introduce a novel indicator, gradients, to monitor and reduce modality dominance which widely exists in the missing-modality scenario. In aid of this indicator, we present a novel Gradient-guided Modality Decoupling (GMD) method to decouple the dependency on dominating modalities. Specifically, GMD removes the conflicted gradient components from different modalities to achieve this decoupling, significantly improving the performance. In addition, to flexibly handle modal-incomplete data, we design a parameter-efficient Dynamic Sharing (DS) framework which can adaptively switch on/off the network parameters based on whether one modality is available. We conduct extensive experiments on three popular multimodal benchmarks, including BraTS 2018 for medical segmentation, CMU-MOSI, and CMU-MOSEI for sentiment analysis. The results show that our method can significantly outperform the competitors, showing the effectiveness of the proposed solutions. Our code is released here: https://github.com/HaoWang420/Gradient-guided-Modality-Decoupling.
Building Flexible Machine Learning Models for Scientific Computing at Scale
Feb 25, 2024Foundation models have revolutionized knowledge acquisition across domains, and our study introduces OmniArch, a paradigm-shifting approach designed for building foundation models in multi-physics scientific computing. OmniArch's pre-training involves a versatile pipeline that processes multi-physics spatio-temporal data, casting forward problem learning into scalable auto-regressive tasks, while our novel Physics-Informed Reinforcement Learning (PIRL) technique during fine-tuning ensures alignment with physical laws. Pre-trained on the comprehensive PDEBench dataset, OmniArch not only sets new performance benchmarks for 1D, 2D and 3D PDEs but also demonstrates exceptional adaptability to new physics via few-shot and zero-shot learning approaches. The model's representations further extend to inverse problem-solving, highlighting the transformative potential of AI-enabled Scientific Computing(AI4SC) foundation models for engineering applications and physics discovery.
From Noise to Clarity: Unraveling the Adversarial Suffix of Large Language Model Attacks via Translation of Text Embeddings
Feb 25, 2024The safety defense methods of Large language models(LLMs) stays limited because the dangerous prompts are manually curated to just few known attack types, which fails to keep pace with emerging varieties. Recent studies found that attaching suffixes to harmful instructions can hack the defense of LLMs and lead to dangerous outputs. This method, while effective, leaves a gap in understanding the underlying mechanics of such adversarial suffix due to the non-readability and it can be relatively easily seen through by common defense methods such as perplexity filters.To cope with this challenge, in this paper, we propose an Adversarial Suffixes Embedding Translation Framework(ASETF) that are able to translate the unreadable adversarial suffixes into coherent, readable text, which makes it easier to understand and analyze the reasons behind harmful content generation by large language models. We conducted experiments on LLMs such as LLaMa2, Vicuna and using the Advbench dataset's harmful instructions. The results indicate that our method achieves a much better attack success rate to existing techniques, while significantly enhancing the textual fluency of the prompts. In addition, our approach can be generalized into a broader method for generating transferable adversarial suffixes that can successfully attack multiple LLMs, even black-box LLMs, such as ChatGPT and Gemini. As a result, the prompts generated through our method exhibit enriched semantic diversity, which potentially provides more adversarial examples for LLM defense methods.
Should We Respect LLMs? A Cross-Lingual Study on the Influence of Prompt Politeness on LLM Performance
Feb 22, 2024We investigate the impact of politeness levels in prompts on the performance of large language models (LLMs). Polite language in human communications often garners more compliance and effectiveness, while rudeness can cause aversion, impacting response quality. We consider that LLMs mirror human communication traits, suggesting they align with human cultural norms. We assess the impact of politeness in prompts on LLMs across English, Chinese, and Japanese tasks. We observed that impolite prompts often result in poor performance, but overly polite language does not guarantee better outcomes. The best politeness level is different according to the language. This phenomenon suggests that LLMs not only reflect human behavior but are also influenced by language, particularly in different cultural contexts. Our findings highlight the need to factor in politeness for cross-cultural natural language processing and LLM usage.