 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoder as Editor: Code-driven Interpretable Molecular Optimization
Oct 16, 2025Molecular optimization is a central task in drug discovery that requires precise structural reasoning and domain knowledge. While large language models (LLMs) have shown promise in generating high-level editing intentions in natural language, they often struggle to faithfully execute these modifications-particularly when operating on non-intuitive representations like SMILES. We introduce MECo, a framework that bridges reasoning and execution by translating editing actions into executable code. MECo reformulates molecular optimization for LLMs as a cascaded framework: generating human-interpretable editing intentions from a molecule and property goal, followed by translating those intentions into executable structural edits via code generation. Our approach achieves over 98% accuracy in reproducing held-out realistic edits derived from chemical reactions and target-specific compound pairs. On downstream optimization benchmarks spanning physicochemical properties and target activities, MECo substantially improves consistency by 38-86 percentage points to 90%+ and achieves higher success rates over SMILES-based baselines while preserving structural similarity. By aligning intention with execution, MECo enables consistent, controllable and interpretable molecular design, laying the foundation for high-fidelity feedback loops and collaborative human-AI workflows in drug discovery.
AANet: Virtual Screening under Structural Uncertainty via Alignment and Aggregation
Jun 06, 2025Virtual screening (VS) is a critical component of modern drug discovery, yet most existing methods--whether physics-based or deep learning-based--are developed around holo protein structures with known ligand-bound pockets. Consequently, their performance degrades significantly on apo or predicted structures such as those from AlphaFold2, which are more representative of real-world early-stage drug discovery, where pocket information is often missing. In this paper, we introduce an alignment-and-aggregation framework to enable accurate virtual screening under structural uncertainty. Our method comprises two core components: (1) a tri-modal contrastive learning module that aligns representations of the ligand, the holo pocket, and cavities detected from structures, thereby enhancing robustness to pocket localization error; and (2) a cross-attention based adapter for dynamically aggregating candidate binding sites, enabling the model to learn from activity data even without precise pocket annotations. We evaluated our method on a newly curated benchmark of apo structures, where it significantly outperforms state-of-the-art methods in blind apo setting, improving the early enrichment factor (EF1%) from 11.75 to 37.19. Notably, it also maintains strong performance on holo structures. These results demonstrate the promise of our approach in advancing first-in-class drug discovery, particularly in scenarios lacking experimentally resolved protein-ligand complexes.
Twin Co-Adaptive Dialogue for Progressive Image Generation
Apr 21, 2025



Modern text-to-image generation systems have enabled the creation of remarkably realistic and high-quality visuals, yet they often falter when handling the inherent ambiguities in user prompts. In this work, we present Twin-Co, a framework that leverages synchronized, co-adaptive dialogue to progressively refine image generation. Instead of a static generation process, Twin-Co employs a dynamic, iterative workflow where an intelligent dialogue agent continuously interacts with the user. Initially, a base image is generated from the user's prompt. Then, through a series of synchronized dialogue exchanges, the system adapts and optimizes the image according to evolving user feedback. The co-adaptive process allows the system to progressively narrow down ambiguities and better align with user intent. Experiments demonstrate that Twin-Co not only enhances user experience by reducing trial-and-error iterations but also improves the quality of the generated images, streamlining the creative process across various applications.
Towards reliable respiratory disease diagnosis based on cough sounds and vision transformers
Sep 03, 2024Recent advancements in deep learning techniques have sparked performance boosts in various real-world applications including disease diagnosis based on multi-modal medical data. Cough sound data-based respiratory disease (e.g., COVID-19 and Chronic Obstructive Pulmonary Disease) diagnosis has also attracted much attention. However, existing works usually utilise traditional machine learning or deep models of moderate scales. On the other hand, the developed approaches are trained and evaluated on small-scale data due to the difficulty of curating and annotating clinical data on scale. To address these issues in prior works, we create a unified framework to evaluate various deep models from lightweight Convolutional Neural Networks (e.g., ResNet18) to modern vision transformers and compare their performance in respiratory disease classification. Based on the observations from such an extensive empirical study, we propose a novel approach to cough-based disease classification based on both self-supervised and supervised learning on a large-scale cough data set. Experimental results demonstrate our proposed approach outperforms prior arts consistently on two benchmark datasets for COVID-19 diagnosis and a proprietary dataset for COPD/non-COPD classification with an AUROC of 92.5%.
CLAP: Learning Transferable Binary Code Representations with Natural Language Supervision
Feb 26, 2024Binary code representation learning has shown significant performance in binary analysis tasks. But existing solutions often have poor transferability, particularly in few-shot and zero-shot scenarios where few or no training samples are available for the tasks. To address this problem, we present CLAP (Contrastive Language-Assembly Pre-training), which employs natural language supervision to learn better representations of binary code (i.e., assembly code) and get better transferability. At the core, our approach boosts superior transfer learning capabilities by effectively aligning binary code with their semantics explanations (in natural language), resulting a model able to generate better embeddings for binary code. To enable this alignment training, we then propose an efficient dataset engine that could automatically generate a large and diverse dataset comprising of binary code and corresponding natural language explanations. We have generated 195 million pairs of binary code and explanations and trained a prototype of CLAP. The evaluations of CLAP across various downstream tasks in binary analysis all demonstrate exceptional performance. Notably, without any task-specific training, CLAP is often competitive with a fully supervised baseline, showing excellent transferability. We release our pre-trained model and code at https://github.com/Hustcw/CLAP.
How Far Have We Gone in Vulnerability Detection Using Large Language Models
Nov 21, 2023As software becomes increasingly complex and prone to vulnerabilities, automated vulnerability detection is critically important, yet challenging. Given the significant successes of Large Language Models (LLMs) in various tasks, there is growing anticipation of their efficacy in vulnerability detection. However, a quantitative understanding of their potential in vulnerability detection is still missing. To bridge this gap, we introduce a comprehensive vulnerability benchmark VulBench. This benchmark aggregates high-quality data from a wide range of CTF (Capture-the-Flag) challenges and real-world applications, with annotations for each vulnerable function detailing the vulnerability type and its root cause. Through our experiments encompassing 16 LLMs and 6 state-of-the-art (SOTA) deep learning-based models and static analyzers, we find that several LLMs outperform traditional deep learning approaches in vulnerability detection, revealing an untapped potential in LLMs. This work contributes to the understanding and utilization of LLMs for enhanced software security.
kTrans: Knowledge-Aware Transformer for Binary Code Embedding
Aug 24, 2023Binary Code Embedding (BCE) has important applications in various reverse engineering tasks such as binary code similarity detection, type recovery, control-flow recovery and data-flow analysis. Recent studies have shown that the Transformer model can comprehend the semantics of binary code to support downstream tasks. However, existing models overlooked the prior knowledge of assembly language. In this paper, we propose a novel Transformer-based approach, namely kTrans, to generate knowledge-aware binary code embedding. By feeding explicit knowledge as additional inputs to the Transformer, and fusing implicit knowledge with a novel pre-training task, kTrans provides a new perspective to incorporating domain knowledge into a Transformer framework. We inspect the generated embeddings with outlier detection and visualization, and also apply kTrans to 3 downstream tasks: Binary Code Similarity Detection (BCSD), Function Type Recovery (FTR) and Indirect Call Recognition (ICR). Evaluation results show that kTrans can generate high-quality binary code embeddings, and outperforms state-of-the-art (SOTA) approaches on downstream tasks by 5.2%, 6.8%, and 12.6% respectively. kTrans is publicly available at: https://github.com/Learner0x5a/kTrans-release
VQNet 2.0: A New Generation Machine Learning Framework that Unifies Classical and Quantum
Jan 09, 2023With the rapid development of classical and quantum machine learning, a large number of machine learning frameworks have been proposed. However, existing machine learning frameworks usually only focus on classical or quantum, rather than both. Therefore, based on VQNet 1.0, we further propose VQNet 2.0, a new generation of unified classical and quantum machine learning framework that supports hybrid optimization. The core library of the framework is implemented in C++, and the user level is implemented in Python, and it supports deployment on quantum and classical hardware. In this article, we analyze the development trend of the new generation machine learning framework and introduce the design principles of VQNet 2.0 in detail: unity, practicality, efficiency, and compatibility, as well as full particulars of implementation. We illustrate the functions of VQNet 2.0 through several basic applications, including classical convolutional neural networks, quantum autoencoders, hybrid classical-quantum networks, etc. After that, through extensive experiments, we demonstrate that the operation speed of VQNet 2.0 is higher than the comparison method. Finally, through extensive experiments, we demonstrate that VQNet 2.0 can deploy on different hardware platforms, the overall calculation speed is faster than the comparison method. It also can be mixed and optimized with quantum circuits composed of multiple quantum computing libraries.
iCallee: Recovering Call Graphs for Binaries
Nov 03, 2021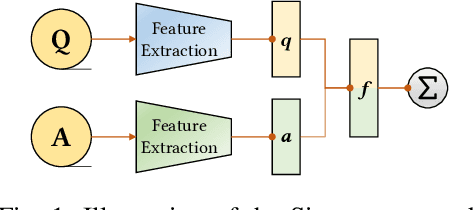
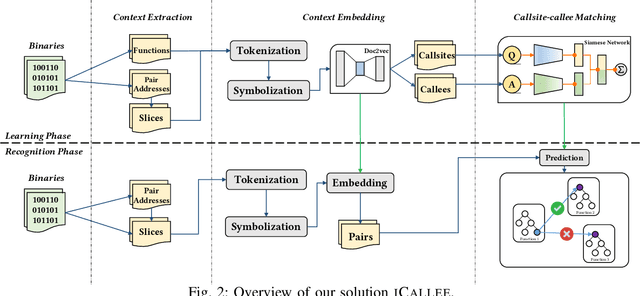
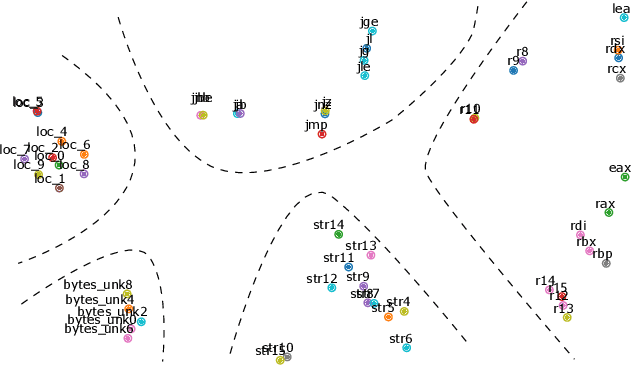
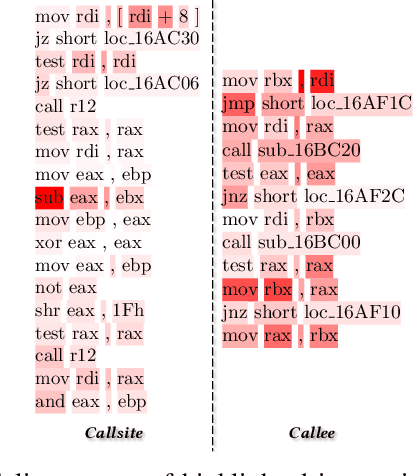
Recovering programs' call graphs is crucial for inter-procedural analysis tasks and applications based on them. The core challenge is recognizing targets of indirect calls (i.e., indirect callees). It becomes more challenging if target programs are in binary forms, due to information loss in binaries. Existing indirect callee recognition solutions for binaries all have high false positives and negatives, making call graphs inaccurate. In this paper, we propose a new solution iCallee based on the Siamese Neural Network, inspired by the advances in question-answering applications. The key insight is that, neural networks can learn to answer whether a callee function is a potential target of an indirect callsite by comprehending their contexts, i.e., instructions nearby callsites and of callees. Following this insight, we first preprocess target binaries to extract contexts of callsites and callees. Then, we build a customized Natural Language Processing (NLP) model applicable to assembly language. Further, we collect abundant pairs of callsites and callees, and embed their contexts with the NLP model, then train a Siamese network and a classifier to answer the callsite-callee question. We have implemented a prototype of iCallee and evaluated it on several groups of targets. Evaluation results showed that, our solution could match callsites to callees with an F1-Measure of 93.7%, recall of 93.8%, and precision of 93.5%, much better than state-of-the-art solutions. To show its usefulness, we apply iCallee to two specific applications - binary code similarity detection and binary program hardening, and found that it could greatly improve state-of-the-art solutions.