 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKwai Keye-VL Technical Report
Jul 02, 2025While Multimodal Large Language Models (MLLMs) demonstrate remarkable capabilities on static images, they often fall short in comprehending dynamic, information-dense short-form videos, a dominant medium in today's digital landscape. To bridge this gap, we introduce \textbf{Kwai Keye-VL}, an 8-billion-parameter multimodal foundation model engineered for leading-edge performance in short-video understanding while maintaining robust general-purpose vision-language abilities. The development of Keye-VL rests on two core pillars: a massive, high-quality dataset exceeding 600 billion tokens with a strong emphasis on video, and an innovative training recipe. This recipe features a four-stage pre-training process for solid vision-language alignment, followed by a meticulous two-phase post-training process. The first post-training stage enhances foundational capabilities like instruction following, while the second phase focuses on stimulating advanced reasoning. In this second phase, a key innovation is our five-mode ``cold-start'' data mixture, which includes ``thinking'', ``non-thinking'', ``auto-think'', ``think with image'', and high-quality video data. This mixture teaches the model to decide when and how to reason. Subsequent reinforcement learning (RL) and alignment steps further enhance these reasoning capabilities and correct abnormal model behaviors, such as repetitive outputs. To validate our approach, we conduct extensive evaluations, showing that Keye-VL achieves state-of-the-art results on public video benchmarks and remains highly competitive on general image-based tasks (Figure 1). Furthermore, we develop and release the \textbf{KC-MMBench}, a new benchmark tailored for real-world short-video scenarios, where Keye-VL shows a significant advantage.
Imitation Learning for Satellite Attitude Control under Unknown Perturbations
Jul 01, 2025



This paper presents a novel satellite attitude control framework that integrates Soft Actor-Critic (SAC) reinforcement learning with Generative Adversarial Imitation Learning (GAIL) to achieve robust performance under various unknown perturbations. Traditional control techniques often rely on precise system models and are sensitive to parameter uncertainties and external perturbations. To overcome these limitations, we first develop a SAC-based expert controller that demonstrates improved resilience against actuator failures, sensor noise, and attitude misalignments, outperforming our previous results in several challenging scenarios. We then use GAIL to train a learner policy that imitates the expert's trajectories, thereby reducing training costs and improving generalization through expert demonstrations. Preliminary experiments under single and combined perturbations show that the SAC expert can rotate the antenna to a specified direction and keep the antenna orientation reliably stable in most of the listed perturbations. Additionally, the GAIL learner can imitate most of the features from the trajectories generated by the SAC expert. Comparative evaluations and ablation studies confirm the effectiveness of the SAC algorithm and reward shaping. The integration of GAIL further reduces sample complexity and demonstrates promising imitation capabilities, paving the way for more intelligent and autonomous spacecraft control systems.
VerIF: Verification Engineering for Reinforcement Learning in Instruction Following
Jun 11, 2025Reinforcement learning with verifiable rewards (RLVR) has become a key technique for enhancing large language models (LLMs), with verification engineering playing a central role. However, best practices for RL in instruction following remain underexplored. In this work, we explore the verification challenge in RL for instruction following and propose VerIF, a verification method that combines rule-based code verification with LLM-based verification from a large reasoning model (e.g., QwQ-32B). To support this approach, we construct a high-quality instruction-following dataset, VerInstruct, containing approximately 22,000 instances with associated verification signals. We apply RL training with VerIF to two models, achieving significant improvements across several representative instruction-following benchmarks. The trained models reach state-of-the-art performance among models of comparable size and generalize well to unseen constraints. We further observe that their general capabilities remain unaffected, suggesting that RL with VerIF can be integrated into existing RL recipes to enhance overall model performance. We have released our datasets, codes, and models to facilitate future research at https://github.com/THU-KEG/VerIF.
STAMImputer: Spatio-Temporal Attention MoE for Traffic Data Imputation
Jun 11, 2025Traffic data imputation is fundamentally important to support various applications in intelligent transportation systems such as traffic flow prediction. However, existing time-to-space sequential methods often fail to effectively extract features in block-wise missing data scenarios. Meanwhile, the static graph structure for spatial feature propagation significantly constrains the models flexibility in handling the distribution shift issue for the nonstationary traffic data. To address these issues, this paper proposes a SpatioTemporal Attention Mixture of experts network named STAMImputer for traffic data imputation. Specifically, we introduce a Mixture of Experts (MoE) framework to capture latent spatio-temporal features and their influence weights, effectively imputing block missing. A novel Low-rank guided Sampling Graph ATtention (LrSGAT) mechanism is designed to dynamically balance the local and global correlations across road networks. The sampled attention vectors are utilized to generate dynamic graphs that capture real-time spatial correlations. Extensive experiments are conducted on four traffic datasets for evaluation. The result shows STAMImputer achieves significantly performance improvement compared with existing SOTA approaches. Our codes are available at https://github.com/RingBDStack/STAMImupter.
The Entropy Mechanism of Reinforcement Learning for Reasoning Language Models
May 28, 2025



This paper aims to overcome a major obstacle in scaling RL for reasoning with LLMs, namely the collapse of policy entropy. Such phenomenon is consistently observed across vast RL runs without entropy intervention, where the policy entropy dropped sharply at the early training stage, this diminished exploratory ability is always accompanied with the saturation of policy performance. In practice, we establish a transformation equation R=-a*e^H+b between entropy H and downstream performance R. This empirical law strongly indicates that, the policy performance is traded from policy entropy, thus bottlenecked by its exhaustion, and the ceiling is fully predictable H=0, R=-a+b. Our finding necessitates entropy management for continuous exploration toward scaling compute for RL. To this end, we investigate entropy dynamics both theoretically and empirically. Our derivation highlights that, the change in policy entropy is driven by the covariance between action probability and the change in logits, which is proportional to its advantage when using Policy Gradient-like algorithms. Empirical study shows that, the values of covariance term and entropy differences matched exactly, supporting the theoretical conclusion. Moreover, the covariance term stays mostly positive throughout training, further explaining why policy entropy would decrease monotonically. Through understanding the mechanism behind entropy dynamics, we motivate to control entropy by restricting the update of high-covariance tokens. Specifically, we propose two simple yet effective techniques, namely Clip-Cov and KL-Cov, which clip and apply KL penalty to tokens with high covariances respectively. Experiments show that these methods encourage exploration, thus helping policy escape entropy collapse and achieve better downstream performance.
AGENTIF: Benchmarking Instruction Following of Large Language Models in Agentic Scenarios
May 22, 2025Large Language Models (LLMs) have demonstrated advanced capabilities in real-world agentic applications. Growing research efforts aim to develop LLM-based agents to address practical demands, introducing a new challenge: agentic scenarios often involve lengthy instructions with complex constraints, such as extended system prompts and detailed tool specifications. While adherence to such instructions is crucial for agentic applications, whether LLMs can reliably follow them remains underexplored. In this paper, we introduce AgentIF, the first benchmark for systematically evaluating LLM instruction following ability in agentic scenarios. AgentIF features three key characteristics: (1) Realistic, constructed from 50 real-world agentic applications. (2) Long, averaging 1,723 words with a maximum of 15,630 words. (3) Complex, averaging 11.9 constraints per instruction, covering diverse constraint types, such as tool specifications and condition constraints. To construct AgentIF, we collect 707 human-annotated instructions across 50 agentic tasks from industrial application agents and open-source agentic systems. For each instruction, we annotate the associated constraints and corresponding evaluation metrics, including code-based evaluation, LLM-based evaluation, and hybrid code-LLM evaluation. We use AgentIF to systematically evaluate existing advanced LLMs. We observe that current models generally perform poorly, especially in handling complex constraint structures and tool specifications. We further conduct error analysis and analytical experiments on instruction length and meta constraints, providing some findings about the failure modes of existing LLMs. We have released the code and data to facilitate future research.
The Unreasonable Effectiveness of Entropy Minimization in LLM Reasoning
May 21, 2025



Entropy minimization (EM) trains the model to concentrate even more probability mass on its most confident outputs. We show that this simple objective alone, without any labeled data, can substantially improve large language models' (LLMs) performance on challenging math, physics, and coding tasks. We explore three approaches: (1) EM-FT minimizes token-level entropy similarly to instruction finetuning, but on unlabeled outputs drawn from the model; (2) EM-RL: reinforcement learning with negative entropy as the only reward to maximize; (3) EM-INF: inference-time logit adjustment to reduce entropy without any training data or parameter updates. On Qwen-7B, EM-RL, without any labeled data, achieves comparable or better performance than strong RL baselines such as GRPO and RLOO that are trained on 60K labeled examples. Furthermore, EM-INF enables Qwen-32B to match or exceed the performance of proprietary models like GPT-4o, Claude 3 Opus, and Gemini 1.5 Pro on the challenging SciCode benchmark, while being 3x more efficient than self-consistency and sequential refinement. Our findings reveal that many pretrained LLMs possess previously underappreciated reasoning capabilities that can be effectively elicited through entropy minimization alone, without any labeled data or even any parameter updates.
Unsupervised Graph Clustering with Deep Structural Entropy
May 20, 2025Research on Graph Structure Learning (GSL) provides key insights for graph-based clustering, yet current methods like Graph Neural Networks (GNNs), Graph Attention Networks (GATs), and contrastive learning often rely heavily on the original graph structure. Their performance deteriorates when the original graph's adjacency matrix is too sparse or contains noisy edges unrelated to clustering. Moreover, these methods depend on learning node embeddings and using traditional techniques like k-means to form clusters, which may not fully capture the underlying graph structure between nodes. To address these limitations, this paper introduces DeSE, a novel unsupervised graph clustering framework incorporating Deep Structural Entropy. It enhances the original graph with quantified structural information and deep neural networks to form clusters. Specifically, we first propose a method for calculating structural entropy with soft assignment, which quantifies structure in a differentiable form. Next, we design a Structural Learning layer (SLL) to generate an attributed graph from the original feature data, serving as a target to enhance and optimize the original structural graph, thereby mitigating the issue of sparse connections between graph nodes. Finally, our clustering assignment method (ASS), based on GNNs, learns node embeddings and a soft assignment matrix to cluster on the enhanced graph. The ASS layer can be stacked to meet downstream task requirements, minimizing structural entropy for stable clustering and maximizing node consistency with edge-based cross-entropy loss. Extensive comparative experiments are conducted on four benchmark datasets against eight representative unsupervised graph clustering baselines, demonstrating the superiority of the DeSE in both effectiveness and interpretability.
mCLM: A Function-Infused and Synthesis-Friendly Modular Chemical Language Model
May 18, 2025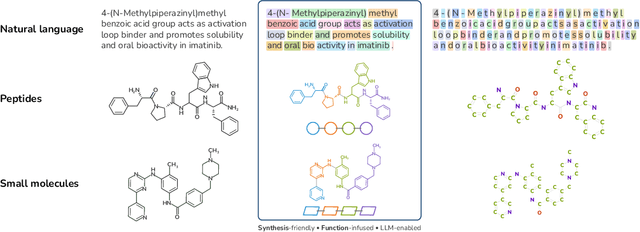
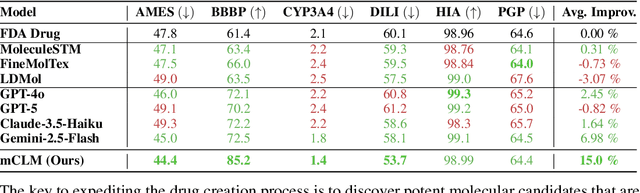
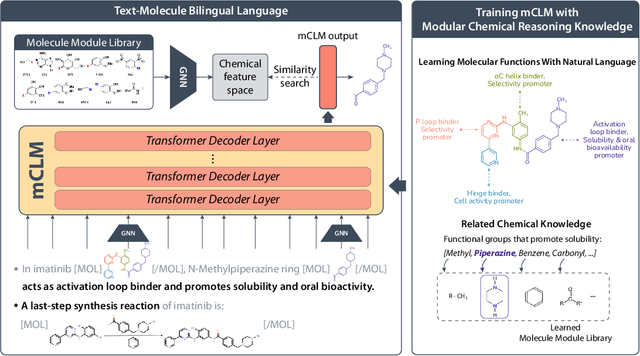
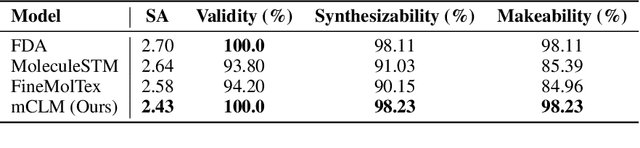
Despite their ability to understand chemical knowledge and accurately generate sequential representations, large language models (LLMs) remain limited in their capacity to propose novel molecules with drug-like properties. In addition, the molecules that LLMs propose can often be challenging to make in the lab. To more effectively enable the discovery of functional small molecules, LLMs need to learn a molecular language. However, LLMs are currently limited by encoding molecules from atoms. In this paper, we argue that just like tokenizing texts into (sub-)word tokens instead of characters, molecules should be decomposed and reassembled at the level of functional building blocks, i.e., parts of molecules that bring unique functions and serve as effective building blocks for real-world automated laboratory synthesis. This motivates us to propose mCLM, a modular Chemical-Language Model tokenizing molecules into building blocks and learning a bilingual language model of both natural language descriptions of functions and molecule building blocks. By reasoning on such functional building blocks, mCLM guarantees to generate efficiently synthesizable molecules thanks to recent progress in block-based chemistry, while also improving the functions of molecules in a principled manner. In experiments on 430 FDA-approved drugs, we find mCLM capable of significantly improving 5 out of 6 chemical functions critical to determining drug potentials. More importantly, mCLM can reason on multiple functions and improve the FDA-rejected drugs (``fallen angels'') over multiple iterations to greatly improve their shortcomings.
Reinforcement Learning Finetunes Small Subnetworks in Large Language Models
May 16, 2025Reinforcement learning (RL) yields substantial improvements in large language models (LLMs) downstream task performance and alignment with human values. Surprisingly, such large gains result from updating only a small subnetwork comprising just 5 percent to 30 percent of the parameters, with the rest effectively unchanged. We refer to this phenomenon as parameter update sparsity induced by RL. It is observed across all 7 widely used RL algorithms (e.g., PPO, GRPO, DPO) and all 10 LLMs from different families in our experiments. This sparsity is intrinsic and occurs without any explicit sparsity promoting regularizations or architectural constraints. Finetuning the subnetwork alone recovers the test accuracy, and, remarkably, produces a model nearly identical to the one obtained via full finetuning. The subnetworks from different random seeds, training data, and even RL algorithms show substantially greater overlap than expected by chance. Our analysis suggests that this sparsity is not due to updating only a subset of layers, instead, nearly all parameter matrices receive similarly sparse updates. Moreover, the updates to almost all parameter matrices are nearly full-rank, suggesting RL updates a small subset of parameters that nevertheless span almost the full subspaces that the parameter matrices can represent. We conjecture that the this update sparsity can be primarily attributed to training on data that is near the policy distribution, techniques that encourage the policy to remain close to the pretrained model, such as the KL regularization and gradient clipping, have limited impact.