 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFVD: Inference-Time Alignment of Diffusion Models via Fleming-Viot Resampling
Apr 08, 2026We introduce Fleming-Viot Diffusion (FVD), an inference-time alignment method that resolves the diversity collapse commonly observed in Sequential Monte Carlo (SMC) based diffusion samplers. Existing SMC-based diffusion samplers often rely on multinomial resampling or closely related resampling schemes, which can still reduce diversity and lead to lineage collapse under strong selection pressure. Inspired by Fleming-Viot population dynamics, FVD replaces multinomial resampling with a specialized birth-death mechanism designed for diffusion alignment. To handle cases where rewards are only approximately available and naive rebirth would collapse deterministic trajectories, FVD integrates independent reward-based survival decisions with stochastic rebirth noise. This yields flexible population dynamics that preserve broader trajectory support while effectively exploring reward-tilted distributions, all without requiring value function approximation or costly rollouts. FVD is fully parallelizable and scales efficiently with inference compute. Empirically, it achieves substantial gains across settings: on DrawBench it outperforms prior methods by 7% in ImageReward, while on class-conditional tasks it improves FID by roughly 14-20% over strong baselines and is up to 66 times faster than value-based approaches.
Do We Need Adam? Surprisingly Strong and Sparse Reinforcement Learning with SGD in LLMs
Feb 07, 2026Reinforcement learning (RL), particularly RL from verifiable reward (RLVR), has become a crucial phase of training large language models (LLMs) and a key focus of current scaling efforts. However, optimization practices in RL largely follow those of next-token prediction stages (e.g., pretraining and supervised fine-tuning), despite fundamental differences between RL and these stages highlighted by recent work. One such practice is the use of the AdamW optimizer, which is widely adopted for training large-scale transformers despite its high memory overhead. Our analysis shows that both momentum and adaptive learning rates in AdamW are less influential in RL than in SFT, leading us to hypothesize that RL benefits less from Adam-style per-parameter adaptive learning rates and momentum. Confirming this hypothesis, our experiments demonstrate that the substantially more memory-efficient SGD, which is known to perform poorly in supervised learning of large-scale transformers, matches or even outperforms AdamW in RL for LLMs. Remarkably, full fine-tuning with SGD updates fewer than 0.02% of model parameters without any sparsity-promoting regularization, more than 1000 times fewer than AdamW. Our analysis offers potential reasons for this update sparsity. These findings provide new insights into the optimization dynamics of RL in LLMs and show that RL can be substantially more parameter-efficient than previously recognized.
Graph Neural Network Assisted Genetic Algorithm for Structural Dynamic Response and Parameter Optimization
Oct 26, 2025The optimization of structural parameters, such as mass(m), stiffness(k), and damping coefficient(c), is critical for designing efficient, resilient, and stable structures. Conventional numerical approaches, including Finite Element Method (FEM) and Computational Fluid Dynamics (CFD) simulations, provide high-fidelity results but are computationally expensive for iterative optimization tasks, as each evaluation requires solving the governing equations for every parameter combination. This study proposes a hybrid data-driven framework that integrates a Graph Neural Network (GNN) surrogate model with a Genetic Algorithm (GA) optimizer to overcome these challenges. The GNN is trained to accurately learn the nonlinear mapping between structural parameters and dynamic displacement responses, enabling rapid predictions without repeatedly solving the system equations. A dataset of single-degree-of-freedom (SDOF) system responses is generated using the Newmark Beta method across diverse mass, stiffness, and damping configurations. The GA then searches for globally optimal parameter sets by minimizing predicted displacements and enhancing dynamic stability. Results demonstrate that the GNN and GA framework achieves strong convergence, robust generalization, and significantly reduced computational cost compared to conventional simulations. This approach highlights the effectiveness of combining machine learning surrogates with evolutionary optimization for automated and intelligent structural design.
Reinforcement Learning Finetunes Small Subnetworks in Large Language Models
May 16, 2025



Reinforcement learning (RL) yields substantial improvements in large language models (LLMs) downstream task performance and alignment with human values. Surprisingly, such large gains result from updating only a small subnetwork comprising just 5 percent to 30 percent of the parameters, with the rest effectively unchanged. We refer to this phenomenon as parameter update sparsity induced by RL. It is observed across all 7 widely used RL algorithms (e.g., PPO, GRPO, DPO) and all 10 LLMs from different families in our experiments. This sparsity is intrinsic and occurs without any explicit sparsity promoting regularizations or architectural constraints. Finetuning the subnetwork alone recovers the test accuracy, and, remarkably, produces a model nearly identical to the one obtained via full finetuning. The subnetworks from different random seeds, training data, and even RL algorithms show substantially greater overlap than expected by chance. Our analysis suggests that this sparsity is not due to updating only a subset of layers, instead, nearly all parameter matrices receive similarly sparse updates. Moreover, the updates to almost all parameter matrices are nearly full-rank, suggesting RL updates a small subset of parameters that nevertheless span almost the full subspaces that the parameter matrices can represent. We conjecture that the this update sparsity can be primarily attributed to training on data that is near the policy distribution, techniques that encourage the policy to remain close to the pretrained model, such as the KL regularization and gradient clipping, have limited impact.
PIPA: A Unified Evaluation Protocol for Diagnosing Interactive Planning Agents
May 02, 2025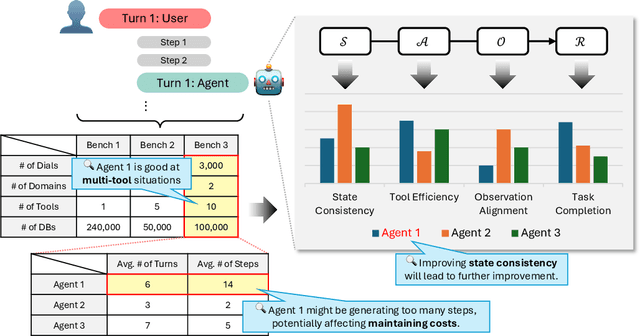

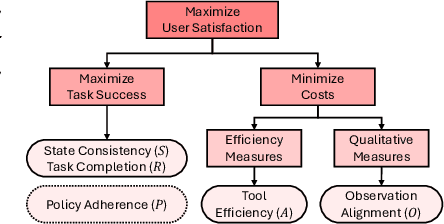

The growing capabilities of large language models (LLMs) in instruction-following and context-understanding lead to the era of agents with numerous applications. Among these, task planning agents have become especially prominent in realistic scenarios involving complex internal pipelines, such as context understanding, tool management, and response generation. However, existing benchmarks predominantly evaluate agent performance based on task completion as a proxy for overall effectiveness. We hypothesize that merely improving task completion is misaligned with maximizing user satisfaction, as users interact with the entire agentic process and not only the end result. To address this gap, we propose PIPA, a unified evaluation protocol that conceptualizes the behavioral process of interactive task planning agents within a partially observable Markov Decision Process (POMDP) paradigm. The proposed protocol offers a comprehensive assessment of agent performance through a set of atomic evaluation criteria, allowing researchers and practitioners to diagnose specific strengths and weaknesses within the agent's decision-making pipeline. Our analyses show that agents excel in different behavioral stages, with user satisfaction shaped by both outcomes and intermediate behaviors. We also highlight future directions, including systems that leverage multiple agents and the limitations of user simulators in task planning.
Premise-Augmented Reasoning Chains Improve Error Identification in Math reasoning with LLMs
Feb 06, 2025



Chain-of-Thought (CoT) prompting enhances mathematical reasoning in large language models (LLMs) by enabling detailed step-by-step solutions. However, due to the verbosity of LLMs, the resulting reasoning chains can be long, making it harder to verify the reasoning steps and trace issues resulting from dependencies between the steps that may be farther away in the sequence of steps. Importantly, mathematical reasoning allows each step to be derived from a small set of premises, which are a subset of the preceding steps in the reasoning chain. In this paper, we present a framework that identifies the premises for each step, to improve the evaluation of reasoning. We restructure conventional linear reasoning chains into Premise Augmented Reasoning Chains (PARC) by introducing premise links, resulting in a directed acyclic graph where the nodes are the steps and the edges are the premise links. Through experiments with a PARC-based dataset that we built, namely PERL (Premises and ERrors identification in LLMs), we demonstrate that LLMs can reliably identify premises within complex reasoning chains. In particular, even open-source LLMs achieve 90% recall in premise identification. We also show that PARC helps to identify errors in reasoning chains more reliably. The accuracy of error identification improves by 6% to 16% absolute when step-by-step verification is carried out in PARC under the premises. Our findings highlight the utility of premise-centric representations in addressing complex problem-solving tasks and open new avenues for improving the reliability of LLM-based reasoning evaluations.
Infogent: An Agent-Based Framework for Web Information Aggregation
Oct 24, 2024



Despite seemingly performant web agents on the task-completion benchmarks, most existing methods evaluate the agents based on a presupposition: the web navigation task consists of linear sequence of actions with an end state that marks task completion. In contrast, our work focuses on web navigation for information aggregation, wherein the agent must explore different websites to gather information for a complex query. We consider web information aggregation from two different perspectives: (i) Direct API-driven Access relies on a text-only view of the Web, leveraging external tools such as Google Search API to navigate the web and a scraper to extract website contents. (ii) Interactive Visual Access uses screenshots of the webpages and requires interaction with the browser to navigate and access information. Motivated by these diverse information access settings, we introduce Infogent, a novel modular framework for web information aggregation involving three distinct components: Navigator, Extractor and Aggregator. Experiments on different information access settings demonstrate Infogent beats an existing SOTA multi-agent search framework by 7% under Direct API-Driven Access on FRAMES, and improves over an existing information-seeking web agent by 4.3% under Interactive Visual Access on AssistantBench.
Cultural Conditioning or Placebo? On the Effectiveness of Socio-Demographic Prompting
Jun 17, 2024



Socio-demographic prompting is a commonly employed approach to study cultural biases in LLMs as well as for aligning models to certain cultures. In this paper, we systematically probe four LLMs (Llama 3, Mistral v0.2, GPT-3.5 Turbo and GPT-4) with prompts that are conditioned on culturally sensitive and non-sensitive cues, on datasets that are supposed to be culturally sensitive (EtiCor and CALI) or neutral (MMLU and ETHICS). We observe that all models except GPT-4 show significant variations in their responses on both kinds of datasets for both kinds of prompts, casting doubt on the robustness of the culturally-conditioned prompting as a method for eliciting cultural bias in models or as an alignment strategy. The work also calls rethinking the control experiment design to tease apart the cultural conditioning of responses from "placebo effect", i.e., random perturbations of model responses due to arbitrary tokens in the prompt.
On the Robustness of Reading Comprehension Models to Entity Renaming
Oct 16, 2021
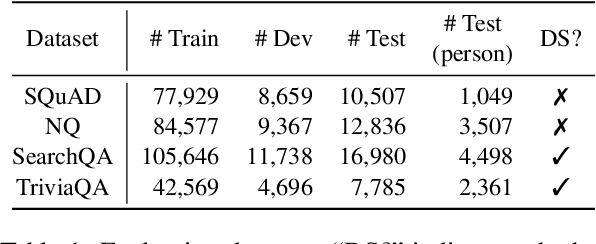
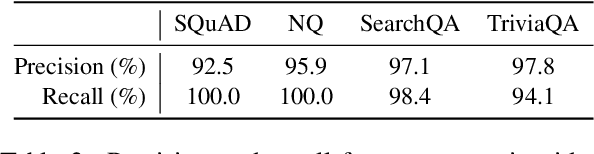

We study the robustness of machine reading comprehension (MRC) models to entity renaming -- do models make more wrong predictions when answer entities have different names? Such failures would indicate that models are overly reliant on entity knowledge to answer questions, and therefore may generalize poorly when facts about the world change or questions are asked about novel entities. To systematically audit model robustness, we propose a general and scalable method to replace person names with names from a variety of sources, ranging from common English names to names from other languages to arbitrary strings. Across four datasets and three pretrained model architectures, MRC models consistently perform worse when entities are renamed, with particularly large accuracy drops on datasets constructed via distant supervision. We also find large differences between models: SpanBERT, which is pretrained with span-level masking, is more robust than RoBERTa, despite having similar accuracy on unperturbed test data. Inspired by this, we experiment with span-level and entity-level masking as a continual pretraining objective and find that they can further improve the robustness of MRC models.
WASSA@IITK at WASSA 2021: Multi-task Learning and Transformer Finetuning for Emotion Classification and Empathy Prediction
Apr 20, 2021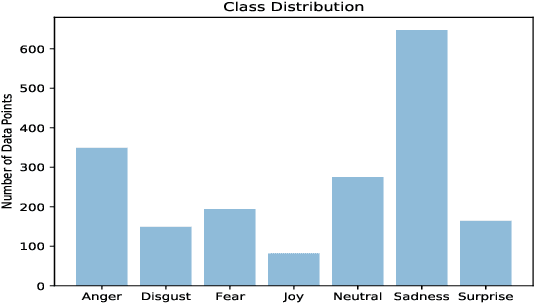
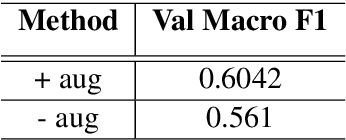
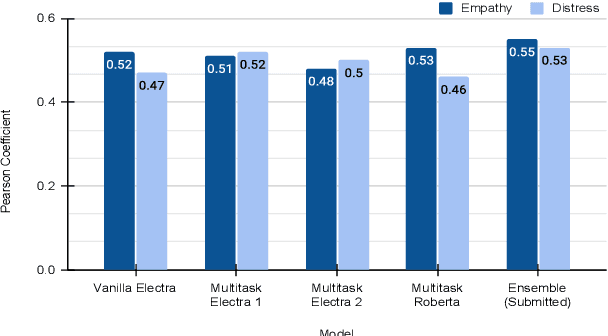
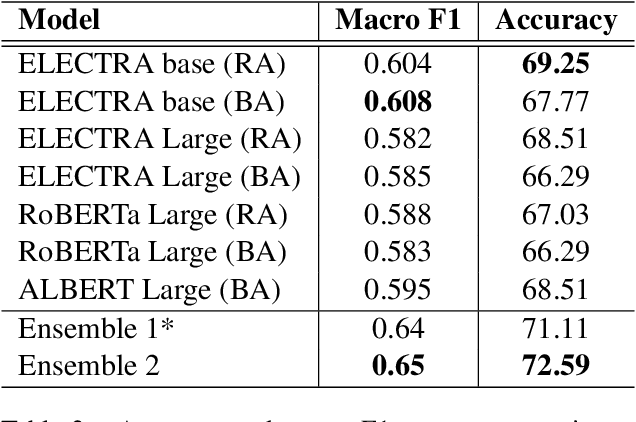
This paper describes our contribution to the WASSA 2021 shared task on Empathy Prediction and Emotion Classification. The broad goal of this task was to model an empathy score, a distress score and the overall level of emotion of an essay written in response to a newspaper article associated with harm to someone. We have used the ELECTRA model abundantly and also advanced deep learning approaches like multi-task learning. Additionally, we also leveraged standard machine learning techniques like ensembling. Our system achieves a Pearson Correlation Coefficient of 0.533 on sub-task I and a macro F1 score of 0.5528 on sub-task II. We ranked 1st in Emotion Classification sub-task and 3rd in Empathy Prediction sub-task