 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking LoRA for Data Heterogeneous Federated Learning: Subspace and State Alignment
Feb 02, 2026Low-Rank Adaptation (LoRA) is widely used for federated fine-tuning. Yet under non-IID settings, it can substantially underperform full-parameter fine-tuning. Through with-high-probability robustness analysis, we uncover that this gap can be attributed to two coupled mismatches: (i) update-space mismatch, where clients optimize in a low-rank subspace but aggregation occurs in the full space; and (ii) optimizer-state mismatch, where unsynchronized adaptive states amplify drift across rounds. We propose FedGaLore, which combines client-side GaLore-style gradient-subspace optimization with server-side drift-robust synchronization of projected second-moment states via spectral shared-signal extraction, to address this challenge. Across NLU, vision, and NLG benchmarks, FedGaLore improves robustness and accuracy over state-of-the-art federated LoRA baselines in non-IID settings.
Robust and Generalized Humanoid Motion Tracking
Jan 30, 2026Learning a general humanoid whole-body controller is challenging because practical reference motions can exhibit noise and inconsistencies after being transferred to the robot domain, and local defects may be amplified by closed-loop execution, causing drift or failure in highly dynamic and contact-rich behaviors. We propose a dynamics-conditioned command aggregation framework that uses a causal temporal encoder to summarize recent proprioception and a multi-head cross-attention command encoder to selectively aggregate a context window based on the current dynamics. We further integrate a fall recovery curriculum with random unstable initialization and an annealed upward assistance force to improve robustness and disturbance rejection. The resulting policy requires only about 3.5 hours of motion data and supports single-stage end-to-end training without distillation. The proposed method is evaluated under diverse reference inputs and challenging motion regimes, demonstrating zero-shot transfer to unseen motions as well as robust sim-to-real transfer on a physical humanoid robot.
A Federated and Parameter-Efficient Framework for Large Language Model Training in Medicine
Jan 29, 2026Large language models (LLMs) have demonstrated strong performance on medical benchmarks, including question answering and diagnosis. To enable their use in clinical settings, LLMs are typically further adapted through continued pretraining or post-training using clinical data. However, most medical LLMs are trained on data from a single institution, which faces limitations in generalizability and safety in heterogeneous systems. Federated learning (FL) is a promising solution for enabling collaborative model development across healthcare institutions. Yet applying FL to LLMs in medicine remains fundamentally limited. First, conventional FL requires transmitting the full model during each communication round, which becomes impractical for multi-billion-parameter LLMs given the limited computational resources. Second, many FL algorithms implicitly assume data homogeneity, whereas real-world clinical data are highly heterogeneous across patients, diseases, and institutional practices. We introduce the model-agnostic and parameter-efficient federated learning framework for adapting LLMs to medical applications. Fed-MedLoRA transmits only low-rank adapter parameters, reducing communication and computation overhead, while Fed-MedLoRA+ further incorporates adaptive, data-aware aggregation to improve convergence under cross-site heterogeneity. We apply the framework to clinical information extraction (IE), which transforms patient narratives into structured medical entities and relations. Accuracy was assessed across five patient cohorts through comparisons with BERT models, and LLaMA-3 and DeepSeek-R1, GPT-4o models. Evaluation settings included (1) in-domain training and testing, (2) external validation on independent cohorts, and (3) a low-resource new-site adaptation scenario using real-world clinical notes from the Yale New Haven Health System.
Textual Equilibrium Propagation for Deep Compound AI Systems
Jan 28, 2026Large language models (LLMs) are increasingly deployed as part of compound AI systems that coordinate multiple modules (e.g., retrievers, tools, verifiers) over long-horizon workflows. Recent approaches that propagate textual feedback globally (e.g., TextGrad) make it feasible to optimize such pipelines, but we find that performance degrades as system depth grows. In particular, long-horizon agentic workflows exhibit two depth-scaling failure modes: 1) exploding textual gradient, where textual feedback grows exponentially with depth, leading to prohibitively long message and amplifies evaluation biases; and 2) vanishing textual gradient, where limited long-context ability causes models overemphasize partial feedback and compression of lengthy feedback causes downstream messages to lose specificity gradually as they propagate many hops upstream. To mitigate these issues, we introduce Textual Equilibrium Propagation (TEP), a local learning principle inspired by Equilibrium Propagation in energy-based models. TEP includes two phases: 1) a free phase where a local LLM critics iteratively refine prompts until reaching equilibrium (no further improvements are suggested); and 2) a nudged phase which applies proximal prompt edits with bounded modification intensity, using task-level objectives that propagate via forward signaling rather than backward feedback chains. This design supports local prompt optimization followed by controlled adaptation toward global goals without the computational burden and signal degradation of global textual backpropagation. Across long-horizon QA benchmarks and multi-agent tool-use dataset, TEP consistently improves accuracy and efficiency over global propagation methods such as TextGrad. The gains grows with depth, while preserving the practicality of black-box LLM components in deep compound AI system.
Generating Risky Samples with Conformity Constraints via Diffusion Models
Dec 21, 2025Although neural networks achieve promising performance in many tasks, they may still fail when encountering some examples and bring about risks to applications. To discover risky samples, previous literature attempts to search for patterns of risky samples within existing datasets or inject perturbation into them. Yet in this way the diversity of risky samples is limited by the coverage of existing datasets. To overcome this limitation, recent works adopt diffusion models to produce new risky samples beyond the coverage of existing datasets. However, these methods struggle in the conformity between generated samples and expected categories, which could introduce label noise and severely limit their effectiveness in applications. To address this issue, we propose RiskyDiff that incorporates the embeddings of both texts and images as implicit constraints of category conformity. We also design a conformity score to further explicitly strengthen the category conformity, as well as introduce the mechanisms of embedding screening and risky gradient guidance to boost the risk of generated samples. Extensive experiments reveal that RiskyDiff greatly outperforms existing methods in terms of the degree of risk, generation quality, and conformity with conditioned categories. We also empirically show the generalization ability of the models can be enhanced by augmenting training data with generated samples of high conformity.
Hybrid Iterative Detection for OTFS: Interplay between Local L-MMSE and Global Message Passing
Dec 16, 2025



Orthogonal time frequency space (OTFS) modulation has emerged as a robust solution for high-mobility wireless communications. However, conventional detection algorithms, such as linear equalizers and message passing (MP) methods, either suffer from noise enhancement or fail under complex doubly-selective channels, especially in the presence of fractional delay and Doppler shifts. In this paper, we propose a hybrid low-complexity iterative detection framework that combines linear minimum mean square error (L-MMSE) estimation with MP-based probabilistic inference. The key idea is to apply a new delay-Doppler (DD) commutation precoder (DDCP) to the DD domain signal vector, such that the resulting effective channel matrix exhibits a structured form with several locally dense blocks that are sparsely inter-connected. This precoding structure enables a hybrid iterative detection strategy, where a low-dimensional L-MMSE estimation is applied to the dense blocks, while MP is utilized to exploit the sparse inter-block connections. Furthermore, we provide a detailed complexity analysis, which shows that the proposed scheme incurs lower computational cost compared to the full-size L-MMSE detection. The simulation results of convergence performance confirm that the proposed hybrid MP detection achieves fast and reliable convergence with controlled complexity. In terms of error performance, simulation results demonstrate that our scheme achieves significantly better bit error rate (BER) under various channel conditions. Particularly in multipath scenarios, the BER performance of the proposed method closely approaches the matched filter bound (MFB), indicating its near-optimal error performance.
Enhancing Logical Expressiveness in Graph Neural Networks via Path-Neighbor Aggregation
Nov 13, 2025



Graph neural networks (GNNs) can effectively model structural information of graphs, making them widely used in knowledge graph (KG) reasoning. However, existing studies on the expressive power of GNNs mainly focuses on simple single-relation graphs, and there is still insufficient discussion on the power of GNN to express logical rules in KGs. How to enhance the logical expressive power of GNNs is still a key issue. Motivated by this, we propose Path-Neighbor enhanced GNN (PN-GNN), a method to enhance the logical expressive power of GNN by aggregating node-neighbor embeddings on the reasoning path. First, we analyze the logical expressive power of existing GNN-based methods and point out the shortcomings of the expressive power of these methods. Then, we theoretically investigate the logical expressive power of PN-GNN, showing that it not only has strictly stronger expressive power than C-GNN but also that its $(k+1)$-hop logical expressiveness is strictly superior to that of $k$-hop. Finally, we evaluate the logical expressive power of PN-GNN on six synthetic datasets and two real-world datasets. Both theoretical analysis and extensive experiments confirm that PN-GNN enhances the expressive power of logical rules without compromising generalization, as evidenced by its competitive performance in KG reasoning tasks.
ODP-Bench: Benchmarking Out-of-Distribution Performance Prediction
Oct 31, 2025Recently, there has been gradually more attention paid to Out-of-Distribution (OOD) performance prediction, whose goal is to predict the performance of trained models on unlabeled OOD test datasets, so that we could better leverage and deploy off-the-shelf trained models in risk-sensitive scenarios. Although progress has been made in this area, evaluation protocols in previous literature are inconsistent, and most works cover only a limited number of real-world OOD datasets and types of distribution shifts. To provide convenient and fair comparisons for various algorithms, we propose Out-of-Distribution Performance Prediction Benchmark (ODP-Bench), a comprehensive benchmark that includes most commonly used OOD datasets and existing practical performance prediction algorithms. We provide our trained models as a testbench for future researchers, thus guaranteeing the consistency of comparison and avoiding the burden of repeating the model training process. Furthermore, we also conduct in-depth experimental analyses to better understand their capability boundary.
LimiX: Unleashing Structured-Data Modeling Capability for Generalist Intelligence
Sep 03, 2025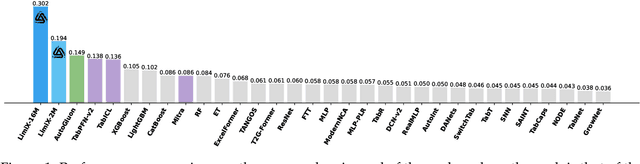
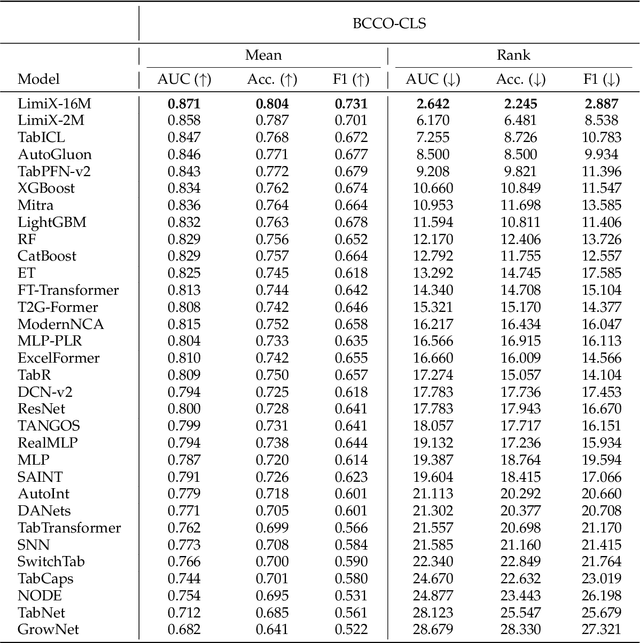
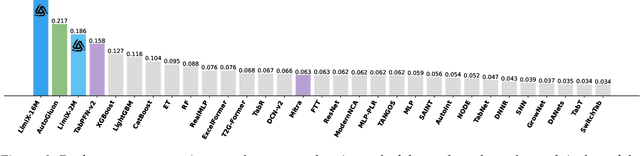
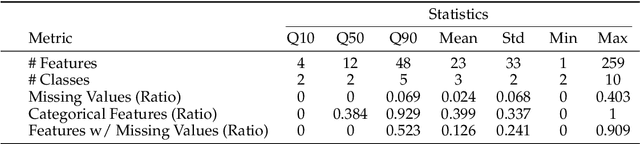
We argue that progress toward general intelligence requires complementary foundation models grounded in language, the physical world, and structured data. This report presents LimiX, the first installment of our large structured-data models (LDMs). LimiX treats structured data as a joint distribution over variables and missingness, thus capable of addressing a wide range of tabular tasks through query-based conditional prediction via a single model. LimiX is pretrained using masked joint-distribution modeling with an episodic, context-conditional objective, where the model predicts for query subsets conditioned on dataset-specific contexts, supporting rapid, training-free adaptation at inference. We evaluate LimiX across 10 large structured-data benchmarks with broad regimes of sample size, feature dimensionality, class number, categorical-to-numerical feature ratio, missingness, and sample-to-feature ratios. With a single model and a unified interface, LimiX consistently surpasses strong baselines including gradient-boosting trees, deep tabular networks, recent tabular foundation models, and automated ensembles, as shown in Figure 1 and Figure 2. The superiority holds across a wide range of tasks, such as classification, regression, missing value imputation, and data generation, often by substantial margins, while avoiding task-specific architectures or bespoke training per task. All LimiX models are publicly accessible under Apache 2.0.
DAG-AFL:Directed Acyclic Graph-based Asynchronous Federated Learning
Jul 28, 2025Due to the distributed nature of federated learning (FL), the vulnerability of the global model and the need for coordination among many client devices pose significant challenges. As a promising decentralized, scalable and secure solution, blockchain-based FL methods have attracted widespread attention in recent years. However, traditional consensus mechanisms designed for Proof of Work (PoW) similar to blockchain incur substantial resource consumption and compromise the efficiency of FL, particularly when participating devices are wireless and resource-limited. To address asynchronous client participation and data heterogeneity in FL, while limiting the additional resource overhead introduced by blockchain, we propose the Directed Acyclic Graph-based Asynchronous Federated Learning (DAG-AFL) framework. We develop a tip selection algorithm that considers temporal freshness, node reachability and model accuracy, with a DAG-based trusted verification strategy. Extensive experiments on 3 benchmarking datasets against eight state-of-the-art approaches demonstrate that DAG-AFL significantly improves training efficiency and model accuracy by 22.7% and 6.5% on average, respectively.