 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Aesthetic Benchmark: Can Frontier Models Judge Beauty?
May 12, 2026Multimodal large language models (MLLMs) are now routinely deployed for visual understanding, generation, and curation. A substantial fraction of these applications require an explicit aesthetic judgment. Most existing solutions reduce this judgment to predicting a scalar score for a single image. We first ask whether such scores faithfully capture comparative preference: in a controlled study with eight expert annotators, score-derived rankings align poorly with the same annotators' direct comparisons, while direct ranking yields substantially higher inter-annotator agreement on best- and worst-image labels. Motivated by this finding, we introduce the Visual Aesthetic Benchmark (VAB), which casts aesthetic evaluation as comparative selection over candidate sets with matched subject matter. VAB contains 400 tasks and 1,195 images across fine art, photography, and illustration, with labels derived from the consensus of 10 independent expert judges per task. Evaluating 20 frontier MLLMs and six dedicated visual-quality reward models, we find that the strongest system identifies both the best and the worst image correctly across three random permutations of the candidate order in only 26.5% of tasks, far below the 68.9% achieved by human experts. Fine-tuning a 35B-parameter model on 2,000 expert examples brings its accuracy close to that of a 397B-parameter open-weight model, suggesting that the comparative signal in VAB is transferable. Together, these results expose a clear and measurable gap between current multimodal models and expert aesthetic judgment, and VAB provides the first set-based, expert-grounded testbed on which that gap can be tracked and closed.
LingLanMiDian: Systematic Evaluation of LLMs on TCM Knowledge and Clinical Reasoning
Feb 02, 2026Large language models (LLMs) are advancing rapidly in medical NLP, yet Traditional Chinese Medicine (TCM) with its distinctive ontology, terminology, and reasoning patterns requires domain-faithful evaluation. Existing TCM benchmarks are fragmented in coverage and scale and rely on non-unified or generation-heavy scoring that hinders fair comparison. We present the LingLanMiDian (LingLan) benchmark, a large-scale, expert-curated, multi-task suite that unifies evaluation across knowledge recall, multi-hop reasoning, information extraction, and real-world clinical decision-making. LingLan introduces a consistent metric design, a synonym-tolerant protocol for clinical labels, a per-dataset 400-item Hard subset, and a reframing of diagnosis and treatment recommendation into single-choice decision recognition. We conduct comprehensive, zero-shot evaluations on 14 leading open-source and proprietary LLMs, providing a unified perspective on their strengths and limitations in TCM commonsense knowledge understanding, reasoning, and clinical decision support; critically, the evaluation on Hard subset reveals a substantial gap between current models and human experts in TCM-specialized reasoning. By bridging fundamental knowledge and applied reasoning through standardized evaluation, LingLan establishes a unified, quantitative, and extensible foundation for advancing TCM LLMs and domain-specific medical AI research. All evaluation data and code are available at https://github.com/TCMAI-BJTU/LingLan and http://tcmnlp.com.
A Federated and Parameter-Efficient Framework for Large Language Model Training in Medicine
Jan 29, 2026Large language models (LLMs) have demonstrated strong performance on medical benchmarks, including question answering and diagnosis. To enable their use in clinical settings, LLMs are typically further adapted through continued pretraining or post-training using clinical data. However, most medical LLMs are trained on data from a single institution, which faces limitations in generalizability and safety in heterogeneous systems. Federated learning (FL) is a promising solution for enabling collaborative model development across healthcare institutions. Yet applying FL to LLMs in medicine remains fundamentally limited. First, conventional FL requires transmitting the full model during each communication round, which becomes impractical for multi-billion-parameter LLMs given the limited computational resources. Second, many FL algorithms implicitly assume data homogeneity, whereas real-world clinical data are highly heterogeneous across patients, diseases, and institutional practices. We introduce the model-agnostic and parameter-efficient federated learning framework for adapting LLMs to medical applications. Fed-MedLoRA transmits only low-rank adapter parameters, reducing communication and computation overhead, while Fed-MedLoRA+ further incorporates adaptive, data-aware aggregation to improve convergence under cross-site heterogeneity. We apply the framework to clinical information extraction (IE), which transforms patient narratives into structured medical entities and relations. Accuracy was assessed across five patient cohorts through comparisons with BERT models, and LLaMA-3 and DeepSeek-R1, GPT-4o models. Evaluation settings included (1) in-domain training and testing, (2) external validation on independent cohorts, and (3) a low-resource new-site adaptation scenario using real-world clinical notes from the Yale New Haven Health System.
Can Textual Gradient Work in Federated Learning?
Feb 27, 2025Recent studies highlight the promise of LLM-based prompt optimization, especially with TextGrad, which automates differentiation'' via texts and backpropagates textual feedback. This approach facilitates training in various real-world applications that do not support numerical gradient propagation or loss calculation. In this paper, we systematically explore the potential and challenges of incorporating textual gradient into Federated Learning (FL). Our contributions are fourfold. Firstly, we introduce a novel FL paradigm, Federated Textual Gradient (FedTextGrad), that allows clients to upload locally optimized prompts derived from textual gradients, while the server aggregates the received prompts. Unlike traditional FL frameworks, which are designed for numerical aggregation, FedTextGrad is specifically tailored for handling textual data, expanding the applicability of FL to a broader range of problems that lack well-defined numerical loss functions. Secondly, building on this design, we conduct extensive experiments to explore the feasibility of FedTextGrad. Our findings highlight the importance of properly tuning key factors (e.g., local steps) in FL training. Thirdly, we highlight a major challenge in FedTextGrad aggregation: retaining essential information from distributed prompt updates. Last but not least, in response to this issue, we improve the vanilla variant of FedTextGrad by providing actionable guidance to the LLM when summarizing client prompts by leveraging the Uniform Information Density principle. Through this principled study, we enable the adoption of textual gradients in FL for optimizing LLMs, identify important issues, and pinpoint future directions, thereby opening up a new research area that warrants further investigation.
Federated Graph Learning with Adaptive Importance-based Sampling
Sep 23, 2024



For privacy-preserving graph learning tasks involving distributed graph datasets, federated learning (FL)-based GCN (FedGCN) training is required. A key challenge for FedGCN is scaling to large-scale graphs, which typically incurs high computation and communication costs when dealing with the explosively increasing number of neighbors. Existing graph sampling-enhanced FedGCN training approaches ignore graph structural information or dynamics of optimization, resulting in high variance and inaccurate node embeddings. To address this limitation, we propose the Federated Adaptive Importance-based Sampling (FedAIS) approach. It achieves substantial computational cost saving by focusing the limited resources on training important nodes, while reducing communication overhead via adaptive historical embedding synchronization. The proposed adaptive importance-based sampling method jointly considers the graph structural heterogeneity and the optimization dynamics to achieve optimal trade-off between efficiency and accuracy. Extensive evaluations against five state-of-the-art baselines on five real-world graph datasets show that FedAIS achieves comparable or up to 3.23% higher test accuracy, while saving communication and computation costs by 91.77% and 85.59%.
Fully Automated OCT-based Tissue Screening System
May 15, 2024This study introduces a groundbreaking optical coherence tomography (OCT) imaging system dedicated for high-throughput screening applications using ex vivo tissue culture. Leveraging OCT's non-invasive, high-resolution capabilities, the system is equipped with a custom-designed motorized platform and tissue detection ability for automated, successive imaging across samples. Transformer-based deep learning segmentation algorithms further ensure robust, consistent, and efficient readouts meeting the standards for screening assays. Validated using retinal explant cultures from a mouse model of retinal degeneration, the system provides robust, rapid, reliable, unbiased, and comprehensive readouts of tissue response to treatments. This fully automated OCT-based system marks a significant advancement in tissue screening, promising to transform drug discovery, as well as other relevant research fields.
Active Noise Control Portable Device Design
Nov 01, 2023While our world is filled with its own natural sounds that we can't resist enjoying, it is also chock-full of other sounds that can be irritating, this is noise. Noise not only influences the working efficiency but also the human's health. The problem of reducing noise is one of great importance and great difficulty. The problem has been addressed in many ways over the years. The current methods for noise reducing mostly rely on the materials and transmission medium, which are only effective to some extent for the high frequency noise. However, the effective reduction noise method especially for low frequency noise is very limited. Here we come up with a noise reduction system consist of a sensor to detect the noise in the environment. Then the noise will be sent to an electronic control system to process the noise, which will generate a reverse phase frequency signal to counteract the disturbance. Finally, the processed smaller noise will be broadcasted by the speaker. Through this smart noise reduction system, even the noise with low-frequency can be eliminated. The system is also integrated with sleep tracking and music player applications. It can also remember and store settings for the same environment, sense temperature, and smart control of home furniture, fire alarm, etc. This smart system can transfer data easily by Wi-Fi or Bluetooth and controlled by its APP. In this project, we will present a model of the above technology which can be used in various environments to prevent noise pollution and provide a solution to the people who have difficulties finding a peaceful and quiet environment for sleep, work or study.
Aggregating Intrinsic Information to Enhance BCI Performance through Federated Learning
Aug 14, 2023



Insufficient data is a long-standing challenge for Brain-Computer Interface (BCI) to build a high-performance deep learning model. Though numerous research groups and institutes collect a multitude of EEG datasets for the same BCI task, sharing EEG data from multiple sites is still challenging due to the heterogeneity of devices. The significance of this challenge cannot be overstated, given the critical role of data diversity in fostering model robustness. However, existing works rarely discuss this issue, predominantly centering their attention on model training within a single dataset, often in the context of inter-subject or inter-session settings. In this work, we propose a hierarchical personalized Federated Learning EEG decoding (FLEEG) framework to surmount this challenge. This innovative framework heralds a new learning paradigm for BCI, enabling datasets with disparate data formats to collaborate in the model training process. Each client is assigned a specific dataset and trains a hierarchical personalized model to manage diverse data formats and facilitate information exchange. Meanwhile, the server coordinates the training procedure to harness knowledge gleaned from all datasets, thus elevating overall performance. The framework has been evaluated in Motor Imagery (MI) classification with nine EEG datasets collected by different devices but implementing the same MI task. Results demonstrate that the proposed frame can boost classification performance up to 16.7% by enabling knowledge sharing between multiple datasets, especially for smaller datasets. Visualization results also indicate that the proposed framework can empower the local models to put a stable focus on task-related areas, yielding better performance. To the best of our knowledge, this is the first end-to-end solution to address this important challenge.
Efficient Training of Large-scale Industrial Fault Diagnostic Models through Federated Opportunistic Block Dropout
Feb 22, 2023

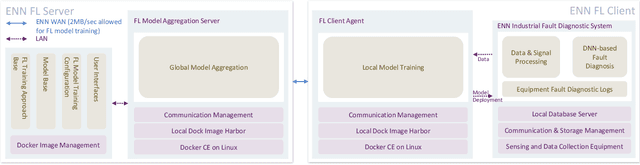

Artificial intelligence (AI)-empowered industrial fault diagnostics is important in ensuring the safe operation of industrial applications. Since complex industrial systems often involve multiple industrial plants (possibly belonging to different companies or subsidiaries) with sensitive data collected and stored in a distributed manner, collaborative fault diagnostic model training often needs to leverage federated learning (FL). As the scale of the industrial fault diagnostic models are often large and communication channels in such systems are often not exclusively used for FL model training, existing deployed FL model training frameworks cannot train such models efficiently across multiple institutions. In this paper, we report our experience developing and deploying the Federated Opportunistic Block Dropout (FEDOBD) approach for industrial fault diagnostic model training. By decomposing large-scale models into semantic blocks and enabling FL participants to opportunistically upload selected important blocks in a quantized manner, it significantly reduces the communication overhead while maintaining model performance. Since its deployment in ENN Group in February 2022, FEDOBD has served two coal chemical plants across two cities in China to build industrial fault prediction models. It helped the company reduce the training communication overhead by over 70% compared to its previous AI Engine, while maintaining model performance at over 85% test F1 score. To our knowledge, it is the first successfully deployed dropout-based FL approach.
FedOBD: Opportunistic Block Dropout for Efficiently Training Large-scale Neural Networks through Federated Learning
Aug 10, 2022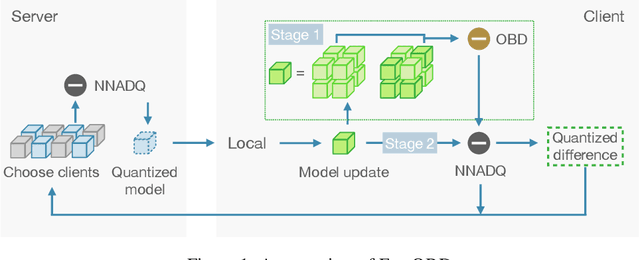
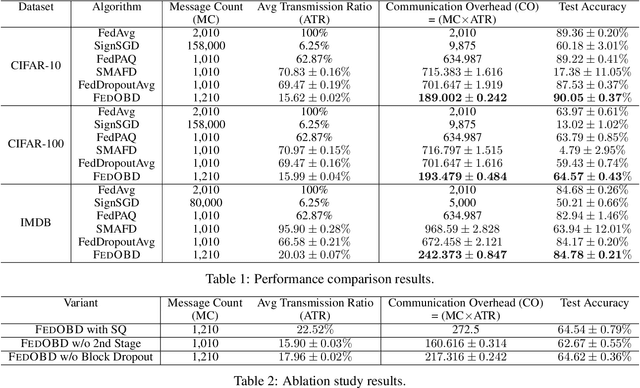
Large-scale neural networks possess considerable expressive power. They are well-suited for complex learning tasks in industrial applications. However, large-scale models pose significant challenges for training under the current Federated Learning (FL) paradigm. Existing approaches for efficient FL training often leverage model parameter dropout. However, manipulating individual model parameters is not only inefficient in meaningfully reducing the communication overhead when training large-scale FL models, but may also be detrimental to the scaling efforts and model performance as shown by recent research. To address these issues, we propose the Federated Opportunistic Block Dropout (FedOBD) approach. The key novelty is that it decomposes large-scale models into semantic blocks so that FL participants can opportunistically upload quantized blocks, which are deemed to be significant towards training the model, to the FL server for aggregation. Extensive experiments evaluating FedOBD against five state-of-the-art approaches based on multiple real-world datasets show that it reduces the overall communication overhead by more than 70% compared to the best performing baseline approach, while achieving the highest test accuracy. To the best of our knowledge, FedOBD is the first approach to perform dropout on FL models at the block level rather than at the individual parameter level.