 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSRT: Accelerating Reinforcement Learning via Speculative Rollout with Tree-Structured Cache
Jan 14, 2026We present Speculative Rollout with Tree-Structured Cache (SRT), a simple, model-free approach to accelerate on-policy reinforcement learning (RL) for language models without sacrificing distributional correctness. SRT exploits the empirical similarity of rollouts for the same prompt across training steps by storing previously generated continuations in a per-prompt tree-structured cache. During generation, the current policy uses this tree as the draft model for performing speculative decoding. To keep the cache fresh and improve draft model quality, SRT updates trees online from ongoing rollouts and proactively performs run-ahead generation during idle GPU bubbles. Integrated into standard RL pipelines (\textit{e.g.}, PPO, GRPO and DAPO) and multi-turn settings, SRT consistently reduces generation and step latency and lowers per-token inference cost, achieving up to 2.08x wall-clock time speedup during rollout.
FAPO: Flawed-Aware Policy Optimization for Efficient and Reliable Reasoning
Oct 26, 2025Reinforcement learning with verifiable rewards (RLVR) has emerged as a promising paradigm for enhancing the reasoning capabilities of large language models (LLMs). In this context, models explore reasoning trajectories and exploit rollouts with correct answers as positive signals for policy optimization. However, these rollouts might involve flawed patterns such as answer-guessing and jump-in-reasoning. Such flawed-positive rollouts are rewarded identically to fully correct ones, causing policy models to internalize these unreliable reasoning patterns. In this work, we first conduct a systematic study of flawed-positive rollouts in RL and find that they enable rapid capability gains during the early optimization stage, while constraining reasoning capability later by reinforcing unreliable patterns. Building on these insights, we propose Flawed-Aware Policy Optimization (FAPO), which presents a parameter-free reward penalty for flawed-positive rollouts, enabling the policy to leverage them as useful shortcuts in the warm-up stage, securing stable early gains, while gradually shifting optimization toward reliable reasoning in the later refinement stage. To accurately and comprehensively detect flawed-positive rollouts, we introduce a generative reward model (GenRM) with a process-level reward that precisely localizes reasoning errors. Experiments show that FAPO is effective in broad domains, improving outcome correctness, process reliability, and training stability without increasing the token budget.
Laminar: A Scalable Asynchronous RL Post-Training Framework
Oct 14, 2025Reinforcement learning (RL) post-training for Large Language Models (LLMs) is now scaling to large clusters and running for extended durations to enhance model reasoning performance. However, the scalability of existing RL frameworks is limited, as extreme long-tail skewness in RL trajectory generation causes severe GPU underutilization. Current asynchronous RL systems attempt to mitigate this, but they rely on global weight synchronization between the actor and all rollouts, which creates a rigid model update schedule. This global synchronization is ill-suited for the highly skewed and evolving distribution of trajectory generation latency in RL training, crippling training efficiency. Our key insight is that efficient scaling requires breaking this lockstep through trajectory-level asynchrony, which generates and consumes each trajectory independently. We propose Laminar, a scalable and robust RL post-training system built on a fully decoupled architecture. First, we replace global updates with a tier of relay workers acting as a distributed parameter service. This enables asynchronous and fine-grained weight synchronization, allowing rollouts to pull the latest weight anytime without stalling the actor's training loop. Second, a dynamic repack mechanism consolidates long-tail trajectories onto a few dedicated rollouts, maximizing generation throughput. The fully decoupled design also isolates failures, ensuring robustness for long-running jobs. Our evaluation on a 1024-GPU cluster shows that Laminar achieves up to 5.48$\times$ training throughput speedup over state-of-the-art systems, while reducing model convergence time.
Boosting Embodied AI Agents through Perception-Generation Disaggregation and Asynchronous Pipeline Execution
Sep 11, 2025Embodied AI systems operate in dynamic environments, requiring seamless integration of perception and generation modules to process high-frequency input and output demands. Traditional sequential computation patterns, while effective in ensuring accuracy, face significant limitations in achieving the necessary "thinking" frequency for real-world applications. In this work, we present Auras, an algorithm-system co-designed inference framework to optimize the inference frequency of embodied AI agents. Auras disaggregates the perception and generation and provides controlled pipeline parallelism for them to achieve high and stable throughput. Faced with the data staleness problem that appears when the parallelism is increased, Auras establishes a public context for perception and generation to share, thereby promising the accuracy of embodied agents. Experimental results show that Auras improves throughput by 2.54x on average while achieving 102.7% of the original accuracy, demonstrating its efficacy in overcoming the constraints of sequential computation and providing high throughput.
SwiftSpec: Ultra-Low Latency LLM Decoding by Scaling Asynchronous Speculative Decoding
Jun 12, 2025



Low-latency decoding for large language models (LLMs) is crucial for applications like chatbots and code assistants, yet generating long outputs remains slow in single-query settings. Prior work on speculative decoding (which combines a small draft model with a larger target model) and tensor parallelism has each accelerated decoding. However, conventional approaches fail to apply both simultaneously due to imbalanced compute requirements (between draft and target models), KV-cache inconsistencies, and communication overheads under small-batch tensor-parallelism. This paper introduces SwiftSpec, a system that targets ultra-low latency for LLM decoding. SwiftSpec redesigns the speculative decoding pipeline in an asynchronous and disaggregated manner, so that each component can be scaled flexibly and remove draft overhead from the critical path. To realize this design, SwiftSpec proposes parallel tree generation, tree-aware KV cache management, and fused, latency-optimized kernels to overcome the challenges listed above. Across 5 model families and 6 datasets, SwiftSpec achieves an average of 1.75x speedup over state-of-the-art speculative decoding systems and, as a highlight, serves Llama3-70B at 348 tokens/s on 8 Nvidia Hopper GPUs, making it the fastest known system for low-latency LLM serving at this scale.
MegaScale-MoE: Large-Scale Communication-Efficient Training of Mixture-of-Experts Models in Production
May 19, 2025We present MegaScale-MoE, a production system tailored for the efficient training of large-scale mixture-of-experts (MoE) models. MoE emerges as a promising architecture to scale large language models (LLMs) to unprecedented sizes, thereby enhancing model performance. However, existing MoE training systems experience a degradation in training efficiency, exacerbated by the escalating scale of MoE models and the continuous evolution of hardware. Recognizing the pivotal role of efficient communication in enhancing MoE training, MegaScale-MoE customizes communication-efficient parallelism strategies for attention and FFNs in each MoE layer and adopts a holistic approach to overlap communication with computation at both inter- and intra-operator levels. Additionally, MegaScale-MoE applies communication compression with adjusted communication patterns to lower precision, further improving training efficiency. When training a 352B MoE model on 1,440 NVIDIA Hopper GPUs, MegaScale-MoE achieves a training throughput of 1.41M tokens/s, improving the efficiency by 1.88$\times$ compared to Megatron-LM. We share our operational experience in accelerating MoE training and hope that by offering our insights in system design, this work will motivate future research in MoE systems.
Seed1.5-VL Technical Report
May 11, 2025



We present Seed1.5-VL, a vision-language foundation model designed to advance general-purpose multimodal understanding and reasoning. Seed1.5-VL is composed with a 532M-parameter vision encoder and a Mixture-of-Experts (MoE) LLM of 20B active parameters. Despite its relatively compact architecture, it delivers strong performance across a wide spectrum of public VLM benchmarks and internal evaluation suites, achieving the state-of-the-art performance on 38 out of 60 public benchmarks. Moreover, in agent-centric tasks such as GUI control and gameplay, Seed1.5-VL outperforms leading multimodal systems, including OpenAI CUA and Claude 3.7. Beyond visual and video understanding, it also demonstrates strong reasoning abilities, making it particularly effective for multimodal reasoning challenges such as visual puzzles. We believe these capabilities will empower broader applications across diverse tasks. In this report, we mainly provide a comprehensive review of our experiences in building Seed1.5-VL across model design, data construction, and training at various stages, hoping that this report can inspire further research. Seed1.5-VL is now accessible at https://www.volcengine.com/ (Volcano Engine Model ID: doubao-1-5-thinking-vision-pro-250428)
Understanding Stragglers in Large Model Training Using What-if Analysis
May 09, 2025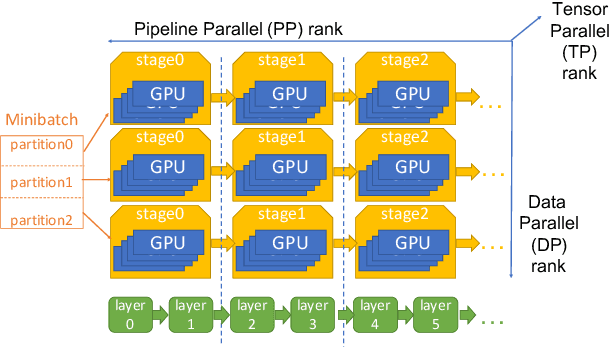

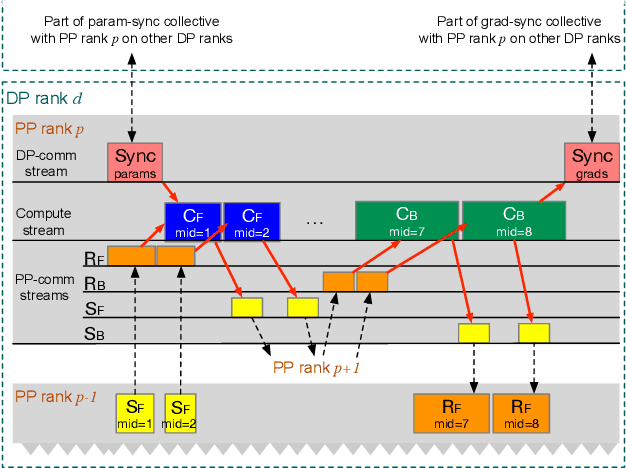
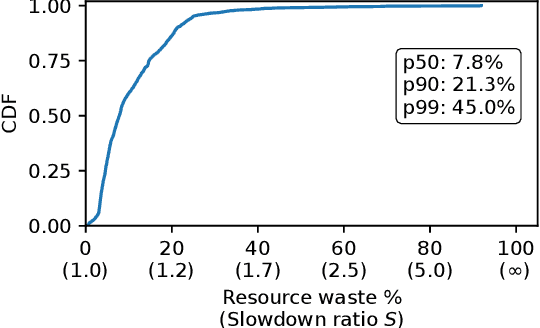
Large language model (LLM) training is one of the most demanding distributed computations today, often requiring thousands of GPUs with frequent synchronization across machines. Such a workload pattern makes it susceptible to stragglers, where the training can be stalled by few slow workers. At ByteDance we find stragglers are not trivially always caused by hardware failures, but can arise from multiple complex factors. This work aims to present a comprehensive study on the straggler issues in LLM training, using a five-month trace collected from our ByteDance LLM training cluster. The core methodology is what-if analysis that simulates the scenario without any stragglers and contrasts with the actual case. We use this method to study the following questions: (1) how often do stragglers affect training jobs, and what effect do they have on job performance; (2) do stragglers exhibit temporal or spatial patterns; and (3) what are the potential root causes for stragglers?
OVERLORD: Ultimate Scaling of DataLoader for Multi-Source Large Foundation Model Training
Apr 14, 2025Modern frameworks for training large foundation models (LFMs) employ data loaders in a data parallel paradigm. While this design offers implementation simplicity, it introduces two fundamental challenges. First, due to the quadratic computational complexity of the attention operator, the non-uniform sample distribution over data-parallel ranks leads to a significant workload imbalance among loaders, which degrades the training efficiency. This paradigm also impedes the implementation of data mixing algorithms (e.g., curriculum learning) over different datasets. Second, to acquire a broad range of capability, LFMs training ingests data from diverse sources, each with distinct file access states. Colocating massive datasets within loader instances can easily exceed local pod memory capacity. Additionally, heavy sources with higher transformation latency require larger worker pools, further exacerbating memory consumption. We present OVERLORD, an industrial-grade distributed data loading architecture with three innovations: (1) A centralized and declarative data plane, which facilitates elastic data orchestration strategy, such as long-short context, multimodal, and curriculum learning; (2) Disaggregated multisource preprocessing through role-specific actors, i.e., Source Loaders and Data Constructors, leveraging autoscaling for Source Loaders towards heterogeneous and evolving source preprocessing cost; (3) Shadow Loaders with differential checkpointing for uninterrupted fault recovery. Deployed on production clusters scaling to multi-thousand GPU, OVERLORD achieves: (1) 4.5x end-to-end training throughput improvement, (2) a minimum 3.6x reduction in CPU memory usage, with further improvements to be added in later experiments.
VAPO: Efficient and Reliable Reinforcement Learning for Advanced Reasoning Tasks
Apr 08, 2025


We present VAPO, Value-based Augmented Proximal Policy Optimization framework for reasoning models., a novel framework tailored for reasoning models within the value-based paradigm. Benchmarked the AIME 2024 dataset, VAPO, built on the Qwen 32B pre-trained model, attains a state-of-the-art score of $\mathbf{60.4}$. In direct comparison under identical experimental settings, VAPO outperforms the previously reported results of DeepSeek-R1-Zero-Qwen-32B and DAPO by more than 10 points. The training process of VAPO stands out for its stability and efficiency. It reaches state-of-the-art performance within a mere 5,000 steps. Moreover, across multiple independent runs, no training crashes occur, underscoring its reliability. This research delves into long chain-of-thought (long-CoT) reasoning using a value-based reinforcement learning framework. We pinpoint three key challenges that plague value-based methods: value model bias, the presence of heterogeneous sequence lengths, and the sparsity of reward signals. Through systematic design, VAPO offers an integrated solution that effectively alleviates these challenges, enabling enhanced performance in long-CoT reasoning tasks.