 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArtificial Intelligence-Enabled Analysis of Radiology Reports: Epidemiology and Consequences of Incidental Thyroid Findings
Oct 30, 2025



Importance Incidental thyroid findings (ITFs) are increasingly detected on imaging performed for non-thyroid indications. Their prevalence, features, and clinical consequences remain undefined. Objective To develop, validate, and deploy a natural language processing (NLP) pipeline to identify ITFs in radiology reports and assess their prevalence, features, and clinical outcomes. Design, Setting, and Participants Retrospective cohort of adults without prior thyroid disease undergoing thyroid-capturing imaging at Mayo Clinic sites from July 1, 2017, to September 30, 2023. A transformer-based NLP pipeline identified ITFs and extracted nodule characteristics from image reports from multiple modalities and body regions. Main Outcomes and Measures Prevalence of ITFs, downstream thyroid ultrasound, biopsy, thyroidectomy, and thyroid cancer diagnosis. Logistic regression identified demographic and imaging-related factors. Results Among 115,683 patients (mean age, 56.8 [SD 17.2] years; 52.9% women), 9,077 (7.8%) had an ITF, of which 92.9% were nodules. ITFs were more likely in women, older adults, those with higher BMI, and when imaging was ordered by oncology or internal medicine. Compared with chest CT, ITFs were more likely via neck CT, PET, and nuclear medicine scans. Nodule characteristics were poorly documented, with size reported in 44% and other features in fewer than 15% (e.g. calcifications). Compared with patients without ITFs, those with ITFs had higher odds of thyroid nodule diagnosis, biopsy, thyroidectomy and thyroid cancer diagnosis. Most cancers were papillary, and larger when detected after ITFs vs no ITF. Conclusions ITFs were common and strongly associated with cascades leading to the detection of small, low-risk cancers. These findings underscore the role of ITFs in thyroid cancer overdiagnosis and the need for standardized reporting and more selective follow-up.
Laminar: A Scalable Asynchronous RL Post-Training Framework
Oct 14, 2025Reinforcement learning (RL) post-training for Large Language Models (LLMs) is now scaling to large clusters and running for extended durations to enhance model reasoning performance. However, the scalability of existing RL frameworks is limited, as extreme long-tail skewness in RL trajectory generation causes severe GPU underutilization. Current asynchronous RL systems attempt to mitigate this, but they rely on global weight synchronization between the actor and all rollouts, which creates a rigid model update schedule. This global synchronization is ill-suited for the highly skewed and evolving distribution of trajectory generation latency in RL training, crippling training efficiency. Our key insight is that efficient scaling requires breaking this lockstep through trajectory-level asynchrony, which generates and consumes each trajectory independently. We propose Laminar, a scalable and robust RL post-training system built on a fully decoupled architecture. First, we replace global updates with a tier of relay workers acting as a distributed parameter service. This enables asynchronous and fine-grained weight synchronization, allowing rollouts to pull the latest weight anytime without stalling the actor's training loop. Second, a dynamic repack mechanism consolidates long-tail trajectories onto a few dedicated rollouts, maximizing generation throughput. The fully decoupled design also isolates failures, ensuring robustness for long-running jobs. Our evaluation on a 1024-GPU cluster shows that Laminar achieves up to 5.48$\times$ training throughput speedup over state-of-the-art systems, while reducing model convergence time.
SafeWork-R1: Coevolving Safety and Intelligence under the AI-45$^{\circ}$ Law
Jul 24, 2025



We introduce SafeWork-R1, a cutting-edge multimodal reasoning model that demonstrates the coevolution of capabilities and safety. It is developed by our proposed SafeLadder framework, which incorporates large-scale, progressive, safety-oriented reinforcement learning post-training, supported by a suite of multi-principled verifiers. Unlike previous alignment methods such as RLHF that simply learn human preferences, SafeLadder enables SafeWork-R1 to develop intrinsic safety reasoning and self-reflection abilities, giving rise to safety `aha' moments. Notably, SafeWork-R1 achieves an average improvement of $46.54\%$ over its base model Qwen2.5-VL-72B on safety-related benchmarks without compromising general capabilities, and delivers state-of-the-art safety performance compared to leading proprietary models such as GPT-4.1 and Claude Opus 4. To further bolster its reliability, we implement two distinct inference-time intervention methods and a deliberative search mechanism, enforcing step-level verification. Finally, we further develop SafeWork-R1-InternVL3-78B, SafeWork-R1-DeepSeek-70B, and SafeWork-R1-Qwen2.5VL-7B. All resulting models demonstrate that safety and capability can co-evolve synergistically, highlighting the generalizability of our framework in building robust, reliable, and trustworthy general-purpose AI.
Streaming 4D Visual Geometry Transformer
Jul 15, 2025



Perceiving and reconstructing 4D spatial-temporal geometry from videos is a fundamental yet challenging computer vision task. To facilitate interactive and real-time applications, we propose a streaming 4D visual geometry transformer that shares a similar philosophy with autoregressive large language models. We explore a simple and efficient design and employ a causal transformer architecture to process the input sequence in an online manner. We use temporal causal attention and cache the historical keys and values as implicit memory to enable efficient streaming long-term 4D reconstruction. This design can handle real-time 4D reconstruction by incrementally integrating historical information while maintaining high-quality spatial consistency. For efficient training, we propose to distill knowledge from the dense bidirectional visual geometry grounded transformer (VGGT) to our causal model. For inference, our model supports the migration of optimized efficient attention operator (e.g., FlashAttention) from the field of large language models. Extensive experiments on various 4D geometry perception benchmarks demonstrate that our model increases the inference speed in online scenarios while maintaining competitive performance, paving the way for scalable and interactive 4D vision systems. Code is available at: https://github.com/wzzheng/StreamVGGT.
Point3R: Streaming 3D Reconstruction with Explicit Spatial Pointer Memory
Jul 03, 2025Dense 3D scene reconstruction from an ordered sequence or unordered image collections is a critical step when bringing research in computer vision into practical scenarios. Following the paradigm introduced by DUSt3R, which unifies an image pair densely into a shared coordinate system, subsequent methods maintain an implicit memory to achieve dense 3D reconstruction from more images. However, such implicit memory is limited in capacity and may suffer from information loss of earlier frames. We propose Point3R, an online framework targeting dense streaming 3D reconstruction. To be specific, we maintain an explicit spatial pointer memory directly associated with the 3D structure of the current scene. Each pointer in this memory is assigned a specific 3D position and aggregates scene information nearby in the global coordinate system into a changing spatial feature. Information extracted from the latest frame interacts explicitly with this pointer memory, enabling dense integration of the current observation into the global coordinate system. We design a 3D hierarchical position embedding to promote this interaction and design a simple yet effective fusion mechanism to ensure that our pointer memory is uniform and efficient. Our method achieves competitive or state-of-the-art performance on various tasks with low training costs. Code is available at: https://github.com/YkiWu/Point3R.
Estimating Quality in Therapeutic Conversations: A Multi-Dimensional Natural Language Processing Framework
May 09, 2025



Engagement between client and therapist is a critical determinant of therapeutic success. We propose a multi-dimensional natural language processing (NLP) framework that objectively classifies engagement quality in counseling sessions based on textual transcripts. Using 253 motivational interviewing transcripts (150 high-quality, 103 low-quality), we extracted 42 features across four domains: conversational dynamics, semantic similarity as topic alignment, sentiment classification, and question detection. Classifiers, including Random Forest (RF), Cat-Boost, and Support Vector Machines (SVM), were hyperparameter tuned and trained using a stratified 5-fold cross-validation and evaluated on a holdout test set. On balanced (non-augmented) data, RF achieved the highest classification accuracy (76.7%), and SVM achieved the highest AUC (85.4%). After SMOTE-Tomek augmentation, performance improved significantly: RF achieved up to 88.9% accuracy, 90.0% F1-score, and 94.6% AUC, while SVM reached 81.1% accuracy, 83.1% F1-score, and 93.6% AUC. The augmented data results reflect the potential of the framework in future larger-scale applications. Feature contribution revealed conversational dynamics and semantic similarity between clients and therapists were among the top contributors, led by words uttered by the client (mean and standard deviation). The framework was robust across the original and augmented datasets and demonstrated consistent improvements in F1 scores and recall. While currently text-based, the framework supports future multimodal extensions (e.g., vocal tone, facial affect) for more holistic assessments. This work introduces a scalable, data-driven method for evaluating engagement quality of the therapy session, offering clinicians real-time feedback to enhance the quality of both virtual and in-person therapeutic interactions.
Understanding LLM Scientific Reasoning through Promptings and Model's Explanation on the Answers
May 02, 2025Large language models (LLMs) have demonstrated remarkable capabilities in natural language understanding, reasoning, and problem-solving across various domains. However, their ability to perform complex, multi-step reasoning task-essential for applications in science, medicine, and law-remains an area of active investigation. This paper examines the reasoning capabilities of contemporary LLMs, analyzing their strengths, limitations, and potential for improvement. The study uses prompt engineering techniques on the Graduate-Level GoogleProof Q&A (GPQA) dataset to assess the scientific reasoning of GPT-4o. Five popular prompt engineering techniques and two tailored promptings were tested: baseline direct answer (zero-shot), chain-of-thought (CoT), zero-shot CoT, self-ask, self-consistency, decomposition, and multipath promptings. Our findings indicate that while LLMs exhibit emergent reasoning abilities, they often rely on pattern recognition rather than true logical inference, leading to inconsistencies in complex problem-solving. The results indicated that self-consistency outperformed the other prompt engineering technique with an accuracy of 52.99%, followed by direct answer (52.23%). Zero-shot CoT (50%) outperformed multipath (48.44%), decomposition (47.77%), self-ask (46.88%), and CoT (43.75%). Self-consistency performed the second worst in explaining the answers. Simple techniques such as direct answer, CoT, and zero-shot CoT have the best scientific reasoning. We propose a research agenda aimed at bridging these gaps by integrating structured reasoning frameworks, hybrid AI approaches, and human-in-the-loop methodologies. By critically evaluating the reasoning mechanisms of LLMs, this paper contributes to the ongoing discourse on the future of artificial general intelligence and the development of more robust, trustworthy AI systems.
ProAI: Proactive Multi-Agent Conversational AI with Structured Knowledge Base for Psychiatric Diagnosis
Feb 28, 2025Most LLM-driven conversational AI systems operate reactively, responding to user prompts without guiding the interaction. Most LLM-driven conversational AI systems operate reactively, responding to user prompts without guiding the interaction. However, many real-world applications-such as psychiatric diagnosis, consulting, and interviews-require AI to take a proactive role, asking the right questions and steering conversations toward specific objectives. Using mental health differential diagnosis as an application context, we introduce ProAI, a goal-oriented, proactive conversational AI framework. ProAI integrates structured knowledge-guided memory, multi-agent proactive reasoning, and a multi-faceted evaluation strategy, enabling LLMs to engage in clinician-style diagnostic reasoning rather than simple response generation. Through simulated patient interactions, user experience assessment, and professional clinical validation, we demonstrate that ProAI achieves up to 83.3% accuracy in mental disorder differential diagnosis while maintaining professional and empathetic interaction standards. These results highlight the potential for more reliable, adaptive, and goal-driven AI diagnostic assistants, advancing LLMs beyond reactive dialogue systems.
EmbodiedOcc: Embodied 3D Occupancy Prediction for Vision-based Online Scene Understanding
Dec 05, 2024

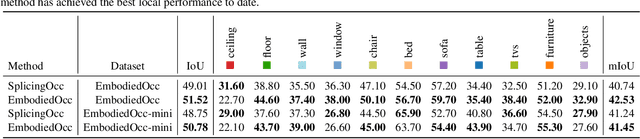

3D occupancy prediction provides a comprehensive description of the surrounding scenes and has become an essential task for 3D perception. Most existing methods focus on offline perception from one or a few views and cannot be applied to embodied agents which demands to gradually perceive the scene through progressive embodied exploration. In this paper, we formulate an embodied 3D occupancy prediction task to target this practical scenario and propose a Gaussian-based EmbodiedOcc framework to accomplish it. We initialize the global scene with uniform 3D semantic Gaussians and progressively update local regions observed by the embodied agent. For each update, we extract semantic and structural features from the observed image and efficiently incorporate them via deformable cross-attention to refine the regional Gaussians. Finally, we employ Gaussian-to-voxel splatting to obtain the global 3D occupancy from the updated 3D Gaussians. Our EmbodiedOcc assumes an unknown (i.e., uniformly distributed) environment and maintains an explicit global memory of it with 3D Gaussians. It gradually gains knowledge through local refinement of regional Gaussians, which is consistent with how humans understand new scenes through embodied exploration. We reorganize an EmbodiedOcc-ScanNet benchmark based on local annotations to facilitate the evaluation of the embodied 3D occupancy prediction task. Experiments demonstrate that our EmbodiedOcc outperforms existing local prediction methods and accomplishes the embodied occupancy prediction with high accuracy and strong expandability. Our code is available at: https://github.com/YkiWu/EmbodiedOcc.
Dynamic Self-Consistency: Leveraging Reasoning Paths for Efficient LLM Sampling
Aug 30, 2024



Self-Consistency (SC) is a widely used method to mitigate hallucinations in Large Language Models (LLMs) by sampling the LLM multiple times and outputting the most frequent solution. Despite its benefits, SC results in significant computational costs proportional to the number of samples generated. Previous early-stopping approaches, such as Early Stopping Self Consistency and Adaptive Consistency, have aimed to reduce these costs by considering output consistency, but they do not analyze the quality of the reasoning paths (RPs) themselves. To address this issue, we propose Reasoning-Aware Self-Consistency (RASC), an innovative early-stopping framework that dynamically adjusts the number of sample generations by considering both the output answer and the RPs from Chain of Thought (CoT) prompting. RASC assigns confidence scores sequentially to the generated samples, stops when certain criteria are met, and then employs weighted majority voting to optimize sample usage and enhance answer reliability. We comprehensively test RASC with multiple LLMs across varied QA datasets. RASC outperformed existing methods and significantly reduces sample usage by an average of 80% while maintaining or improving accuracy up to 5% compared to the original SC