 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJenius Agent: Towards Experience-Driven Accuracy Optimization in Real-World Scenarios
Jan 07, 2026As agent systems powered by large language models (LLMs) advance, improving the task performance of an autonomous agent, especially in context understanding, tool usage, and response generation, has become increasingly critical. Although prior studies have advanced the overall design of LLM-based agents, systematic optimization of their internal reasoning and tool-use pipelines remains underexplored. This paper introduces an agent framework grounded in real-world practical experience, with three key innovations: (1) an adaptive prompt generation strategy that aligns with the agent's state and task goals to improve reliability and robustness; (2) a context-aware tool orchestration module that performs tool categorization, semantic retrieval, and adaptive invocation based on user intent and context; and (3) a layered memory mechanism that integrates session memory, task history, and external summaries to improve relevance and efficiency through dynamic summarization and compression. An end-to-end framework named Jenius-Agent has been integrated with three key optimizations, including tools based on the Model Context Protocol (MCP), file input/output (I/O), and execution feedback. The experiments show a 20 percent improvement in task accuracy, along with a reduced token cost, response latency, and invocation failures. The framework is already deployed in Jenius (https://www.jenius.cn), providing a lightweight and scalable solution for robust, protocol-compatible autonomous agents.
OVERLORD: Ultimate Scaling of DataLoader for Multi-Source Large Foundation Model Training
Apr 14, 2025Modern frameworks for training large foundation models (LFMs) employ data loaders in a data parallel paradigm. While this design offers implementation simplicity, it introduces two fundamental challenges. First, due to the quadratic computational complexity of the attention operator, the non-uniform sample distribution over data-parallel ranks leads to a significant workload imbalance among loaders, which degrades the training efficiency. This paradigm also impedes the implementation of data mixing algorithms (e.g., curriculum learning) over different datasets. Second, to acquire a broad range of capability, LFMs training ingests data from diverse sources, each with distinct file access states. Colocating massive datasets within loader instances can easily exceed local pod memory capacity. Additionally, heavy sources with higher transformation latency require larger worker pools, further exacerbating memory consumption. We present OVERLORD, an industrial-grade distributed data loading architecture with three innovations: (1) A centralized and declarative data plane, which facilitates elastic data orchestration strategy, such as long-short context, multimodal, and curriculum learning; (2) Disaggregated multisource preprocessing through role-specific actors, i.e., Source Loaders and Data Constructors, leveraging autoscaling for Source Loaders towards heterogeneous and evolving source preprocessing cost; (3) Shadow Loaders with differential checkpointing for uninterrupted fault recovery. Deployed on production clusters scaling to multi-thousand GPU, OVERLORD achieves: (1) 4.5x end-to-end training throughput improvement, (2) a minimum 3.6x reduction in CPU memory usage, with further improvements to be added in later experiments.
ByteScale: Efficient Scaling of LLM Training with a 2048K Context Length on More Than 12,000 GPUs
Feb 28, 2025Scaling long-context ability is essential for Large Language Models (LLMs). To amortize the memory consumption across multiple devices in long-context training, inter-data partitioning (a.k.a. Data Parallelism) and intra-data partitioning (a.k.a. Context Parallelism) are commonly used. Current training frameworks predominantly treat the two techniques as orthogonal, and establish static communication groups to organize the devices as a static mesh (e.g., a 2D mesh). However, the sequences for LLM training typically vary in lengths, no matter for texts, multi-modalities or reinforcement learning. The mismatch between data heterogeneity and static mesh causes redundant communication and imbalanced computation, degrading the training efficiency. In this work, we introduce ByteScale, an efficient, flexible, and scalable LLM training framework for large-scale mixed training of long and short sequences. The core of ByteScale is a novel parallelism strategy, namely Hybrid Data Parallelism (HDP), which unifies the inter- and intra-data partitioning with a dynamic mesh design. In particular, we build a communication optimizer, which eliminates the redundant communication for short sequences by data-aware sharding and dynamic communication, and further compresses the communication cost for long sequences by selective offloading. Besides, we also develop a balance scheduler to mitigate the imbalanced computation by parallelism-aware data assignment. We evaluate ByteScale with the model sizes ranging from 7B to 141B, context lengths from 256K to 2048K, on a production cluster with more than 12,000 GPUs. Experiment results show that ByteScale outperforms the state-of-the-art training system by up to 7.89x.
AllWOZ: Towards Multilingual Task-Oriented Dialog Systems for All
Dec 15, 2021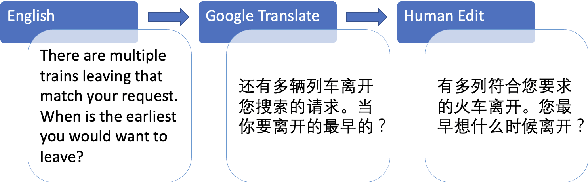
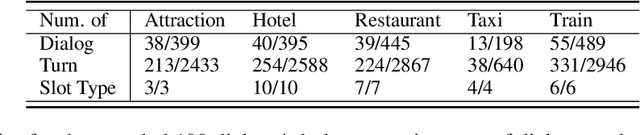

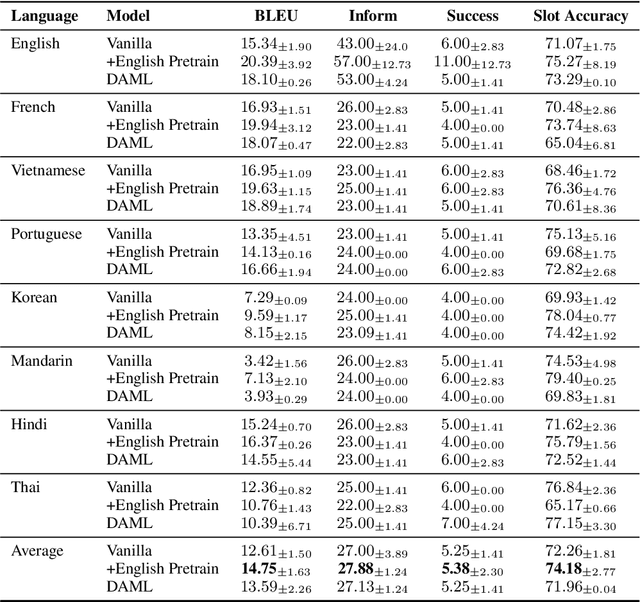
A commonly observed problem of the state-of-the-art natural language technologies, such as Amazon Alexa and Apple Siri, is that their services do not extend to most developing countries' citizens due to language barriers. Such populations suffer due to the lack of available resources in their languages to build NLP products. This paper presents AllWOZ, a multilingual multi-domain task-oriented customer service dialog dataset covering eight languages: English, Mandarin, Korean, Vietnamese, Hindi, French, Portuguese, and Thai. Furthermore, we create a benchmark for our multilingual dataset by applying mT5 with meta-learning.
Improving Conversational Recommendation Systems' Quality with Context-Aware Item Meta Information
Dec 15, 2021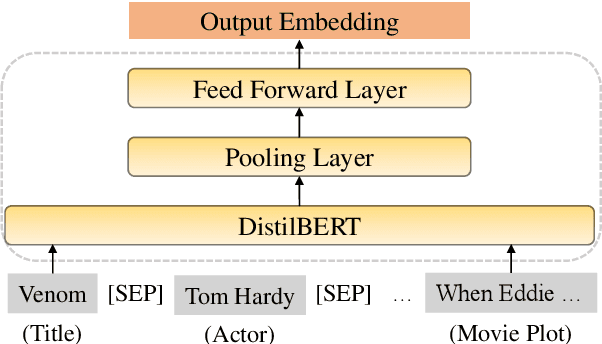
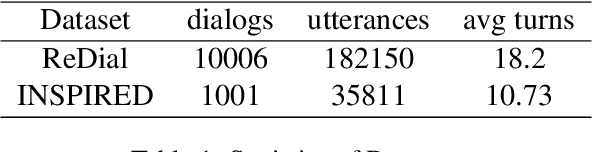
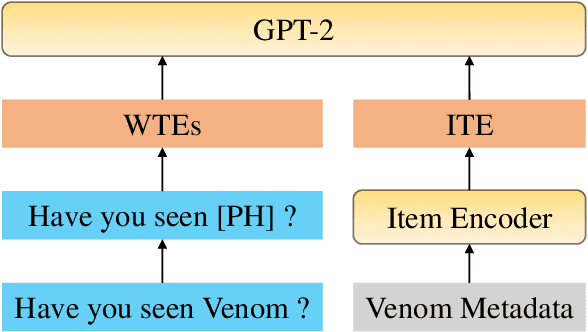
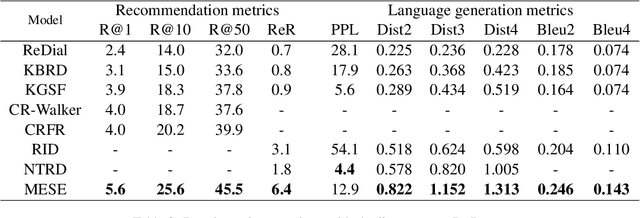
Conversational recommendation systems (CRS) engage with users by inferring user preferences from dialog history, providing accurate recommendations, and generating appropriate responses. Previous CRSs use knowledge graph (KG) based recommendation modules and integrate KG with language models for response generation. Although KG-based approaches prove effective, two issues remain to be solved. First, KG-based approaches ignore the information in the conversational context but only rely on entity relations and bag of words to recommend items. Second, it requires substantial engineering efforts to maintain KGs that model domain-specific relations, thus leading to less flexibility. In this paper, we propose a simple yet effective architecture comprising a pre-trained language model (PLM) and an item metadata encoder. The encoder learns to map item metadata to embeddings that can reflect the semantic information in the dialog context. The PLM then consumes the semantic-aligned item embeddings together with dialog context to generate high-quality recommendations and responses. Instead of modeling entity relations with KGs, our model reduces engineering complexity by directly converting each item to an embedding. Experimental results on the benchmark dataset ReDial show that our model obtains state-of-the-art results on both recommendation and response generation tasks.