 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTensorHub: Scalable and Elastic Weight Transfer for LLM RL Training
Apr 10, 2026Modern LLM reinforcement learning (RL) workloads require a highly efficient weight transfer system to scale training across heterogeneous computational resources. However, existing weight transfer approaches either fail to provide flexibility for dynamically scaling clusters or incur fundamental data movement overhead, resulting in poor performance. We introduce Reference-Oriented Storage (ROS), a new storage abstraction for RL weight transfer that exploits the highly replicated model weights in place. ROS presents the illusion that certain versions of the model weights are stored and can be fetched on demand. Underneath, ROS does not physically store any copies of the weights; instead, it tracks the workers that hold these weights on GPUs for inference. Upon request, ROS directly uses them to serve reads. We build TensorHub, a production-quality system that extends the ROS idea with topology-optimized transfer, strong consistency, and fault tolerance. Evaluation shows that TensorHub fully saturates RDMA bandwidth and adapts to three distinct rollout workloads with minimal engineering effort. Specifically, TensorHub reduces total GPU stall time by up to 6.7x for standalone rollouts, accelerates weight update for elastic rollout by 4.8x, and cuts cross-datacenter rollout stall time by 19x. TensorHub has been deployed in production to support cutting-edge RL training.
Joint Geometric and Trajectory Consistency Learning for One-Step Real-World Super-Resolution
Feb 27, 2026Diffusion-based Real-World Image Super-Resolution (Real-ISR) achieves impressive perceptual quality but suffers from high computational costs due to iterative sampling. While recent distillation approaches leveraging large-scale Text-to-Image (T2I) priors have enabled one-step generation, they are typically hindered by prohibitive parameter counts and the inherent capability bounds imposed by teacher models. As a lightweight alternative, Consistency Models offer efficient inference but struggle with two critical limitations: the accumulation of consistency drift inherent to transitive training, and a phenomenon we term "Geometric Decoupling" - where the generative trajectory achieves pixel-wise alignment yet fails to preserve structural coherence. To address these challenges, we propose GTASR (Geometric Trajectory Alignment Super-Resolution), a simple yet effective consistency training paradigm for Real-ISR. Specifically, we introduce a Trajectory Alignment (TA) strategy to rectify the tangent vector field via full-path projection, and a Dual-Reference Structural Rectification (DRSR) mechanism to enforce strict structural constraints. Extensive experiments verify that GTASR delivers superior performance over representative baselines while maintaining minimal latency. The code and model will be released at https://github.com/Blazedengcy/GTASR.
Guaranteeing Conservation of Integrals with Projection in Physics-Informed Neural Networks
Nov 12, 2025We propose a novel projection method that guarantees the conservation of integral quantities in Physics-Informed Neural Networks (PINNs). While the soft constraint that PINNs use to enforce the structure of partial differential equations (PDEs) enables necessary flexibility during training, it also permits the discovered solution to violate physical laws. To address this, we introduce a projection method that guarantees the conservation of the linear and quadratic integrals, both separately and jointly. We derived the projection formulae by solving constrained non-linear optimization problems and found that our PINN modified with the projection, which we call PINN-Proj, reduced the error in the conservation of these quantities by three to four orders of magnitude compared to the soft constraint and marginally reduced the PDE solution error. We also found evidence that the projection improved convergence through improving the conditioning of the loss landscape. Our method holds promise as a general framework to guarantee the conservation of any integral quantity in a PINN if a tractable solution exists.
Laminar: A Scalable Asynchronous RL Post-Training Framework
Oct 14, 2025Reinforcement learning (RL) post-training for Large Language Models (LLMs) is now scaling to large clusters and running for extended durations to enhance model reasoning performance. However, the scalability of existing RL frameworks is limited, as extreme long-tail skewness in RL trajectory generation causes severe GPU underutilization. Current asynchronous RL systems attempt to mitigate this, but they rely on global weight synchronization between the actor and all rollouts, which creates a rigid model update schedule. This global synchronization is ill-suited for the highly skewed and evolving distribution of trajectory generation latency in RL training, crippling training efficiency. Our key insight is that efficient scaling requires breaking this lockstep through trajectory-level asynchrony, which generates and consumes each trajectory independently. We propose Laminar, a scalable and robust RL post-training system built on a fully decoupled architecture. First, we replace global updates with a tier of relay workers acting as a distributed parameter service. This enables asynchronous and fine-grained weight synchronization, allowing rollouts to pull the latest weight anytime without stalling the actor's training loop. Second, a dynamic repack mechanism consolidates long-tail trajectories onto a few dedicated rollouts, maximizing generation throughput. The fully decoupled design also isolates failures, ensuring robustness for long-running jobs. Our evaluation on a 1024-GPU cluster shows that Laminar achieves up to 5.48$\times$ training throughput speedup over state-of-the-art systems, while reducing model convergence time.
Measuring and Controlling the Spectral Bias for Self-Supervised Image Denoising
Oct 01, 2025Current self-supervised denoising methods for paired noisy images typically involve mapping one noisy image through the network to the other noisy image. However, after measuring the spectral bias of such methods using our proposed Image Pair Frequency-Band Similarity, it suffers from two practical limitations. Firstly, the high-frequency structural details in images are not preserved well enough. Secondly, during the process of fitting high frequencies, the network learns high-frequency noise from the mapped noisy images. To address these challenges, we introduce a Spectral Controlling network (SCNet) to optimize self-supervised denoising of paired noisy images. First, we propose a selection strategy to choose frequency band components for noisy images, to accelerate the convergence speed of training. Next, we present a parameter optimization method that restricts the learning ability of convolutional kernels to high-frequency noise using the Lipschitz constant, without changing the network structure. Finally, we introduce the Spectral Separation and low-rank Reconstruction module (SSR module), which separates noise and high-frequency details through frequency domain separation and low-rank space reconstruction, to retain the high-frequency structural details of images. Experiments performed on synthetic and real-world datasets verify the effectiveness of SCNet.
TongUI: Building Generalized GUI Agents by Learning from Multimodal Web Tutorials
Apr 17, 2025Building Graphical User Interface (GUI) agents is a promising research direction, which simulates human interaction with computers or mobile phones to perform diverse GUI tasks. However, a major challenge in developing generalized GUI agents is the lack of sufficient trajectory data across various operating systems and applications, mainly due to the high cost of manual annotations. In this paper, we propose the TongUI framework that builds generalized GUI agents by learning from rich multimodal web tutorials. Concretely, we crawl and process online GUI tutorials (such as videos and articles) into GUI agent trajectory data, through which we produce the GUI-Net dataset containing 143K trajectory data across five operating systems and more than 200 applications. We develop the TongUI agent by fine-tuning Qwen2.5-VL-3B/7B models on GUI-Net, which show remarkable performance improvements on commonly used grounding and navigation benchmarks, outperforming baseline agents about 10\% on multiple benchmarks, showing the effectiveness of the GUI-Net dataset and underscoring the significance of our TongUI framework. We will fully open-source the code, the GUI-Net dataset, and the trained models soon.
VAPO: Efficient and Reliable Reinforcement Learning for Advanced Reasoning Tasks
Apr 08, 2025


We present VAPO, Value-based Augmented Proximal Policy Optimization framework for reasoning models., a novel framework tailored for reasoning models within the value-based paradigm. Benchmarked the AIME 2024 dataset, VAPO, built on the Qwen 32B pre-trained model, attains a state-of-the-art score of $\mathbf{60.4}$. In direct comparison under identical experimental settings, VAPO outperforms the previously reported results of DeepSeek-R1-Zero-Qwen-32B and DAPO by more than 10 points. The training process of VAPO stands out for its stability and efficiency. It reaches state-of-the-art performance within a mere 5,000 steps. Moreover, across multiple independent runs, no training crashes occur, underscoring its reliability. This research delves into long chain-of-thought (long-CoT) reasoning using a value-based reinforcement learning framework. We pinpoint three key challenges that plague value-based methods: value model bias, the presence of heterogeneous sequence lengths, and the sparsity of reward signals. Through systematic design, VAPO offers an integrated solution that effectively alleviates these challenges, enabling enhanced performance in long-CoT reasoning tasks.
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Mar 18, 2025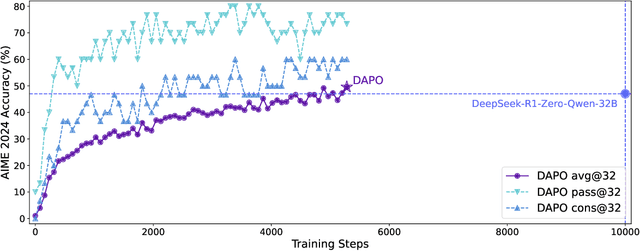

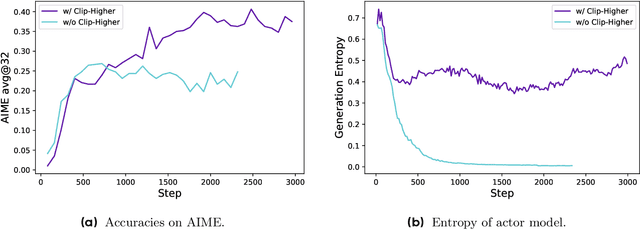

Inference scaling empowers LLMs with unprecedented reasoning ability, with reinforcement learning as the core technique to elicit complex reasoning. However, key technical details of state-of-the-art reasoning LLMs are concealed (such as in OpenAI o1 blog and DeepSeek R1 technical report), thus the community still struggles to reproduce their RL training results. We propose the $\textbf{D}$ecoupled Clip and $\textbf{D}$ynamic s$\textbf{A}$mpling $\textbf{P}$olicy $\textbf{O}$ptimization ($\textbf{DAPO}$) algorithm, and fully open-source a state-of-the-art large-scale RL system that achieves 50 points on AIME 2024 using Qwen2.5-32B base model. Unlike previous works that withhold training details, we introduce four key techniques of our algorithm that make large-scale LLM RL a success. In addition, we open-source our training code, which is built on the verl framework, along with a carefully curated and processed dataset. These components of our open-source system enhance reproducibility and support future research in large-scale LLM RL.
Prompt-SID: Learning Structural Representation Prompt via Latent Diffusion for Single-Image Denoising
Feb 10, 2025



Many studies have concentrated on constructing supervised models utilizing paired datasets for image denoising, which proves to be expensive and time-consuming. Current self-supervised and unsupervised approaches typically rely on blind-spot networks or sub-image pairs sampling, resulting in pixel information loss and destruction of detailed structural information, thereby significantly constraining the efficacy of such methods. In this paper, we introduce Prompt-SID, a prompt-learning-based single image denoising framework that emphasizes preserving of structural details. This approach is trained in a self-supervised manner using downsampled image pairs. It captures original-scale image information through structural encoding and integrates this prompt into the denoiser. To achieve this, we propose a structural representation generation model based on the latent diffusion process and design a structural attention module within the transformer-based denoiser architecture to decode the prompt. Additionally, we introduce a scale replay training mechanism, which effectively mitigates the scale gap from images of different resolutions. We conduct comprehensive experiments on synthetic, real-world, and fluorescence imaging datasets, showcasing the remarkable effectiveness of Prompt-SID.
Spatiotemporal Blind-Spot Network with Calibrated Flow Alignment for Self-Supervised Video Denoising
Dec 16, 2024Self-supervised video denoising aims to remove noise from videos without relying on ground truth data, leveraging the video itself to recover clean frames. Existing methods often rely on simplistic feature stacking or apply optical flow without thorough analysis. This results in suboptimal utilization of both inter-frame and intra-frame information, and it also neglects the potential of optical flow alignment under self-supervised conditions, leading to biased and insufficient denoising outcomes. To this end, we first explore the practicality of optical flow in the self-supervised setting and introduce a SpatioTemporal Blind-spot Network (STBN) for global frame feature utilization. In the temporal domain, we utilize bidirectional blind-spot feature propagation through the proposed blind-spot alignment block to ensure accurate temporal alignment and effectively capture long-range dependencies. In the spatial domain, we introduce the spatial receptive field expansion module, which enhances the receptive field and improves global perception capabilities. Additionally, to reduce the sensitivity of optical flow estimation to noise, we propose an unsupervised optical flow distillation mechanism that refines fine-grained inter-frame interactions during optical flow alignment. Our method demonstrates superior performance across both synthetic and real-world video denoising datasets. The source code is publicly available at https://github.com/ZKCCZ/STBN.