 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Numerical Features: CNN-Driven Algorithm Selection via Contour Plots for Continuous Black-Box Optimization
May 20, 2026The present paper introduces a new representation-driven approach to per-instance algorithm selection, applied to black-box optimization, for automatically choosing the most promising solver from a fixed portfolio. Prior work in continuous optimization largely relies on numerical descriptors, including Exploratory Landscape Analysis features and learned embeddings such as Deep-ELA. This work studies a complementary representation: contour-map visualizations of probed landscapes. A CNN regressor takes multiple instance-specific contour views (stacked or encoded per view and aggregated) and predicts per-solver performance, enabling selection by the predicted best value. On the standard BBOB 2009 single-objective protocol, the resulting selectors significantly outperform the single best solver (SBS) and are competitive with feature-based baselines. A subsequent bi-objective evaluation under the DeepELA setting further indicates that the same image-based principle can be competitive when using windowed contour views. Overall, the results suggest that simple vision models can exploit spatial structure in probed landscapes for algorithm selection without handcrafted ELA features.
The Override Gap: A Magnitude Account of Knowledge Conflict Failure in Hypernetwork-Based Instant LLM Adaptation
Apr 26, 2026Hypernetwork-based methods such as Doc-to-LoRA internalize a document into an LLM's weights in a single forward pass, but they fail systematically on conflicts: when the document contradicts pretraining knowledge, accuracy collapses to 46.4% on the deepest facts. We show the failure is a magnitude problem rather than a representational one. The hypernetwork already targets the right layers, but its adapter margin is approximately constant across documents while the pretrained margin grows with training frequency, so deep conflicts lose by construction. The account predicts that failure should track prior strength: sorting 194 conflicts by the base model's log-probability on the contradicted fact, baseline accuracy falls from 68% on weak-prior questions to 16% on strong-prior ones, a 52 percentage-point gap. The cure is amplitude. Selective Layer Boosting scales the adapter at its top-norm layers, and Conflict-Aware Internalization triggers boosting only when the base model is confident. Both are training-free; together they raise deep-conflict accuracy from 46.4% to 71.0% on Gemma-2B and from 53.6% to 72.5% on Mistral-7B while preserving novel-knowledge recall, and beat vanilla retrieval-augmented generation on medium conflicts by 18 percentage points despite operating entirely in parameter space. We release KID-Bench, a 489-question benchmark that separates novel recall, cross-knowledge combination, and prior-graded conflicts.
Formalising the Logit Shift Induced by LoRA: A Technical Note
Apr 22, 2026This technical note provides a first-order formalisation of the logit shift and fact-margin change induced by Low-Rank Adaptation (LoRA). Using a first-order Fréchet approximation around the base model trajectory, we show that the multi-layer LoRA effect can be decomposed into a linear summation of layerwise contributions and a higher-order remainder term representing inter-layer coupling.
GeoPAS: Geometric Probing for Algorithm Selection in Continuous Black-Box Optimisation
Apr 14, 2026Automated algorithm selection in continuous black-box optimisation typically relies on fixed landscape descriptors computed under a limited probing budget, yet such descriptors can degrade under problem-split or cross-benchmark evaluation. We propose GeoPAS, a geometric probing approach that represents a problem instance by multiple coarse two-dimensional slices sampled across locations, orientations, and logarithmic scales. A shared validity-aware convolutional encoder maps each slice to an embedding, conditions it on slice-scale and amplitude statistics, and aggregates the resulting features permutation-invariantly for risk-aware solver selection via log-scale performance prediction with an explicit penalty on tail failures. On COCO/BBOB with a 12-solver portfolio in dimensions 2--10, GeoPAS improves over the single best solver under leave-instance-out, grouped random, and leave-problem-out evaluation. These results suggest that multi-scale geometric slices provide a useful transferable static signal for algorithm selection, although a small number of heavy-tail regimes remain and continue to dominate the mean. Our code is available at https://github.com/BradWangW/GeoPAS.
ROI-Driven Foveated Attention for Unified Egocentric Representations in Vision-Language-Action Systems
Mar 21, 2026The development of embodied AI systems is increasingly constrained by the availability and structure of physical interaction data. Despite recent advances in vision-language-action (VLA) models, current pipelines suffer from high data collection cost, limited cross-embodiment alignment, and poor transfer from internet-scale visual data to robot control. We propose a region-of-interest (ROI) driven engineering workflow that introduces an egocentric, geometry-grounded data representation. By projecting end-effector poses via forward kinematics (FK) into a single external camera, we derive movement-aligned hand-centric ROIs without requiring wrist-mounted cameras or multi-view systems. Unlike directly downsampling the full frame, ROI is cropped from the original image before resizing, preserving high local information density for contact-critical regions while retaining global context. We present a reproducible pipeline covering calibration, synchronization, ROI generation, deterministic boundary handling, and metadata governance. The resulting representation is embodiment-aligned and viewpoint-normalized, enabling data reuse across heterogeneous robots. We argue that egocentric ROI serves as a practical data abstraction for scalable collection and cross-embodiment learning, bridging internet-scale perception and robot-specific control.
SaiVLA-0: Cerebrum--Pons--Cerebellum Tripartite Architecture for Compute-Aware Vision-Language-Action
Mar 09, 2026We revisit Vision-Language-Action through a neuroscience-inspired triad. Biologically, the Cerebrum provides stable high-level multimodal priors and remains frozen; the Pons Adapter integrates these cortical features with real-time proprioceptive inputs and compiles intent into execution-ready tokens; and the Cerebellum (ParaCAT) performs fast, parallel categorical decoding for online control, with hysteresis/EMA/temperature/entropy for stability. A fixed-ratio schedule and two-stage feature caching make the system compute-aware and reproducible. Inspired by active, foveated vision, our wrist ROIs are geometrically tied to the end-effector via calibrated projection, providing a movement-stabilized, high-resolution view that is sensitive to fine-grained pose changes and complements the global context of the main view. The design is modular: upgrading the Cerebrum only retrains the Pons; changing robots only trains the Cerebellum; cerebellum-only RL can further refine control without touching high-level semantics. As a concept-and-protocol paper with preliminary evidence, we outline a timing protocol under matched conditions (GPU, resolution, batch) to verify anticipated efficiency gains. We also report preliminary LIBERO evidence showing that split feature caching reduces training time (7.5h to 4.5h) and improves average success (86.5% to 92.5%) under official N1.5 head-only training, and that SaiVLA0 reaches 99.0% mean success.
Interplay Between Belief Propagation and Transformer: Differential-Attention Message Passing Transformer
Sep 19, 2025Transformer-based neural decoders have emerged as a promising approach to error correction coding, combining data-driven adaptability with efficient modeling of long-range dependencies. This paper presents a novel decoder architecture that integrates classical belief propagation principles with transformer designs. We introduce a differentiable syndrome loss function leveraging global codebook structure and a differential-attention mechanism optimizing bit and syndrome embedding interactions. Experimental results demonstrate consistent performance improvements over existing transformer-based decoders, with our approach surpassing traditional belief propagation decoders for short-to-medium length LDPC codes.
Understanding Stragglers in Large Model Training Using What-if Analysis
May 09, 2025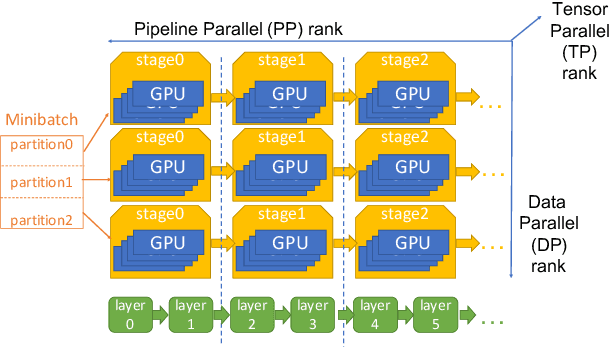

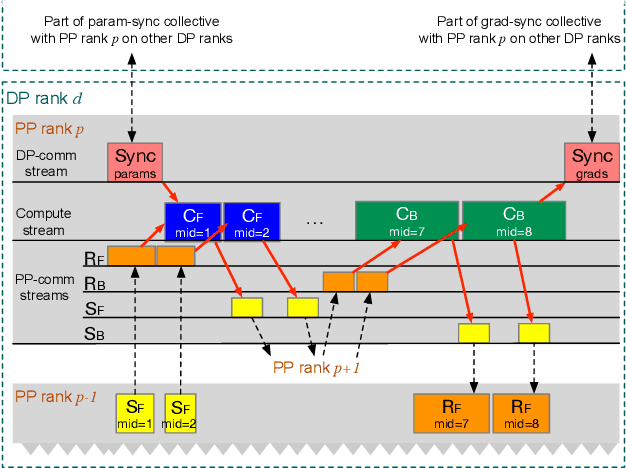
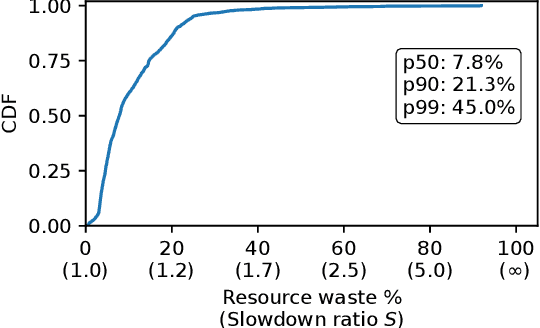
Large language model (LLM) training is one of the most demanding distributed computations today, often requiring thousands of GPUs with frequent synchronization across machines. Such a workload pattern makes it susceptible to stragglers, where the training can be stalled by few slow workers. At ByteDance we find stragglers are not trivially always caused by hardware failures, but can arise from multiple complex factors. This work aims to present a comprehensive study on the straggler issues in LLM training, using a five-month trace collected from our ByteDance LLM training cluster. The core methodology is what-if analysis that simulates the scenario without any stragglers and contrasts with the actual case. We use this method to study the following questions: (1) how often do stragglers affect training jobs, and what effect do they have on job performance; (2) do stragglers exhibit temporal or spatial patterns; and (3) what are the potential root causes for stragglers?
Scalable Hierarchical Reinforcement Learning for Hyper Scale Multi-Robot Task Planning
Dec 27, 2024



To improve the efficiency of warehousing system and meet huge customer orders, we aim to solve the challenges of dimension disaster and dynamic properties in hyper scale multi-robot task planning (MRTP) for robotic mobile fulfillment system (RMFS). Existing research indicates that hierarchical reinforcement learning (HRL) is an effective method to reduce these challenges. Based on that, we construct an efficient multi-stage HRL-based multi-robot task planner for hyper scale MRTP in RMFS, and the planning process is represented with a special temporal graph topology. To ensure optimality, the planner is designed with a centralized architecture, but it also brings the challenges of scaling up and generalization that require policies to maintain performance for various unlearned scales and maps. To tackle these difficulties, we first construct a hierarchical temporal attention network (HTAN) to ensure basic ability of handling inputs with unfixed lengths, and then design multi-stage curricula for hierarchical policy learning to further improve the scaling up and generalization ability while avoiding catastrophic forgetting. Additionally, we notice that policies with hierarchical structure suffer from unfair credit assignment that is similar to that in multi-agent reinforcement learning, inspired of which, we propose a hierarchical reinforcement learning algorithm with counterfactual rollout baseline to improve learning performance. Experimental results demonstrate that our planner outperform other state-of-the-art methods on various MRTP instances in both simulated and real-world RMFS. Also, our planner can successfully scale up to hyper scale MRTP instances in RMFS with up to 200 robots and 1000 retrieval racks on unlearned maps while keeping superior performance over other methods.
Minder: Faulty Machine Detection for Large-scale Distributed Model Training
Nov 04, 2024



Large-scale distributed model training requires simultaneous training on up to thousands of machines. Faulty machine detection is critical when an unexpected fault occurs in a machine. From our experience, a training task can encounter two faults per day on average, possibly leading to a halt for hours. To address the drawbacks of the time-consuming and labor-intensive manual scrutiny, we propose Minder, an automatic faulty machine detector for distributed training tasks. The key idea of Minder is to automatically and efficiently detect faulty distinctive monitoring metric patterns, which could last for a period before the entire training task comes to a halt. Minder has been deployed in our production environment for over one year, monitoring daily distributed training tasks where each involves up to thousands of machines. In our real-world fault detection scenarios, Minder can accurately and efficiently react to faults within 3.6 seconds on average, with a precision of 0.904 and F1-score of 0.893.