 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenDoP: Auto-regressive Camera Trajectory Generation as a Director of Photography
Apr 10, 2025Camera trajectory design plays a crucial role in video production, serving as a fundamental tool for conveying directorial intent and enhancing visual storytelling. In cinematography, Directors of Photography meticulously craft camera movements to achieve expressive and intentional framing. However, existing methods for camera trajectory generation remain limited: Traditional approaches rely on geometric optimization or handcrafted procedural systems, while recent learning-based methods often inherit structural biases or lack textual alignment, constraining creative synthesis. In this work, we introduce an auto-regressive model inspired by the expertise of Directors of Photography to generate artistic and expressive camera trajectories. We first introduce DataDoP, a large-scale multi-modal dataset containing 29K real-world shots with free-moving camera trajectories, depth maps, and detailed captions in specific movements, interaction with the scene, and directorial intent. Thanks to the comprehensive and diverse database, we further train an auto-regressive, decoder-only Transformer for high-quality, context-aware camera movement generation based on text guidance and RGBD inputs, named GenDoP. Extensive experiments demonstrate that compared to existing methods, GenDoP offers better controllability, finer-grained trajectory adjustments, and higher motion stability. We believe our approach establishes a new standard for learning-based cinematography, paving the way for future advancements in camera control and filmmaking. Our project website: https://kszpxxzmc.github.io/GenDoP/.
Gaussian Mixture Flow Matching Models
Apr 07, 2025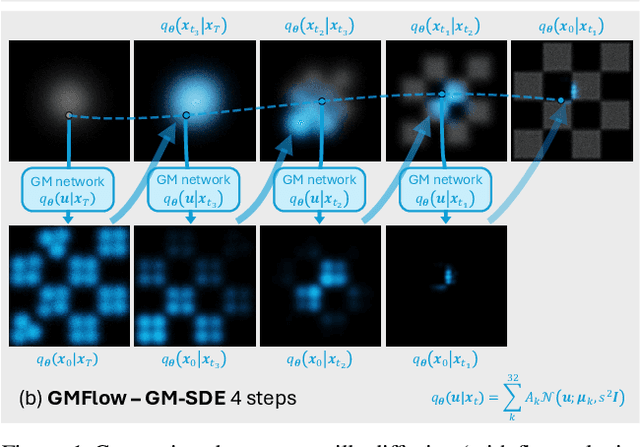
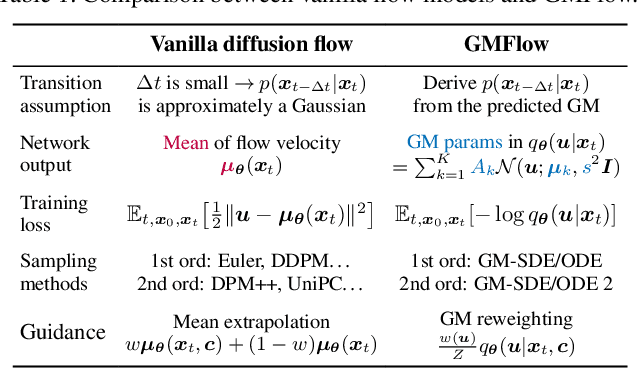
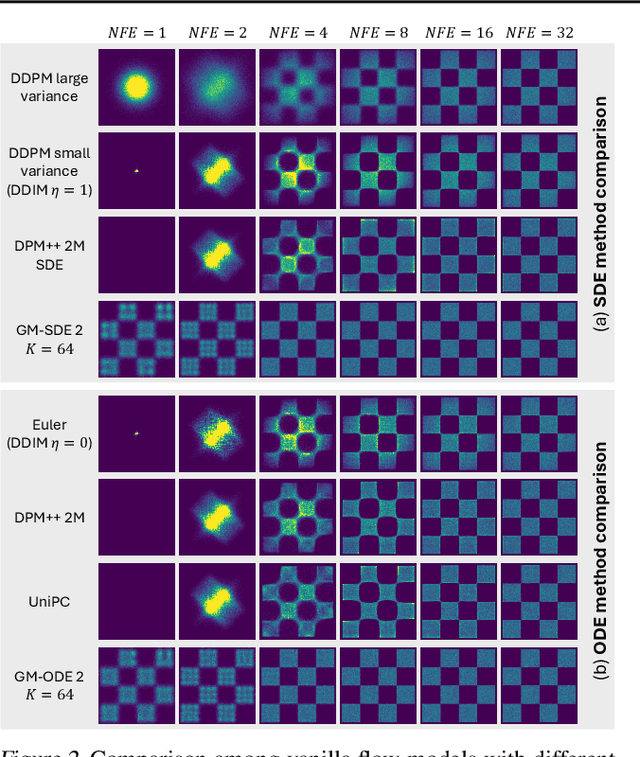
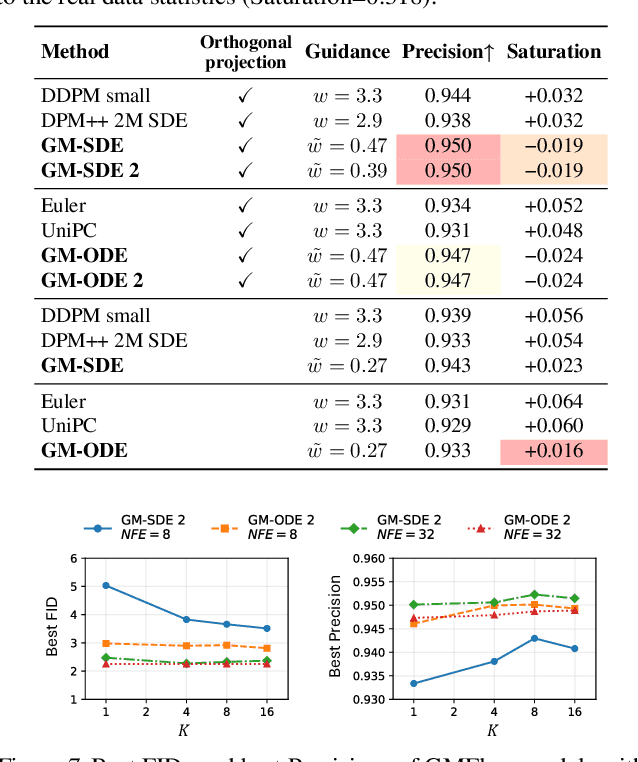
Diffusion models approximate the denoising distribution as a Gaussian and predict its mean, whereas flow matching models reparameterize the Gaussian mean as flow velocity. However, they underperform in few-step sampling due to discretization error and tend to produce over-saturated colors under classifier-free guidance (CFG). To address these limitations, we propose a novel Gaussian mixture flow matching (GMFlow) model: instead of predicting the mean, GMFlow predicts dynamic Gaussian mixture (GM) parameters to capture a multi-modal flow velocity distribution, which can be learned with a KL divergence loss. We demonstrate that GMFlow generalizes previous diffusion and flow matching models where a single Gaussian is learned with an $L_2$ denoising loss. For inference, we derive GM-SDE/ODE solvers that leverage analytic denoising distributions and velocity fields for precise few-step sampling. Furthermore, we introduce a novel probabilistic guidance scheme that mitigates the over-saturation issues of CFG and improves image generation quality. Extensive experiments demonstrate that GMFlow consistently outperforms flow matching baselines in generation quality, achieving a Precision of 0.942 with only 6 sampling steps on ImageNet 256$\times$256.
3DGen-Bench: Comprehensive Benchmark Suite for 3D Generative Models
Mar 27, 2025



3D generation is experiencing rapid advancements, while the development of 3D evaluation has not kept pace. How to keep automatic evaluation equitably aligned with human perception has become a well-recognized challenge. Recent advances in the field of language and image generation have explored human preferences and showcased respectable fitting ability. However, the 3D domain still lacks such a comprehensive preference dataset over generative models. To mitigate this absence, we develop 3DGen-Arena, an integrated platform in a battle manner. Then, we carefully design diverse text and image prompts and leverage the arena platform to gather human preferences from both public users and expert annotators, resulting in a large-scale multi-dimension human preference dataset 3DGen-Bench. Using this dataset, we further train a CLIP-based scoring model, 3DGen-Score, and a MLLM-based automatic evaluator, 3DGen-Eval. These two models innovatively unify the quality evaluation of text-to-3D and image-to-3D generation, and jointly form our automated evaluation system with their respective strengths. Extensive experiments demonstrate the efficacy of our scoring model in predicting human preferences, exhibiting a superior correlation with human ranks compared to existing metrics. We believe that our 3DGen-Bench dataset and automated evaluation system will foster a more equitable evaluation in the field of 3D generation, further promoting the development of 3D generative models and their downstream applications.
CoT-VLA: Visual Chain-of-Thought Reasoning for Vision-Language-Action Models
Mar 27, 2025



Vision-language-action models (VLAs) have shown potential in leveraging pretrained vision-language models and diverse robot demonstrations for learning generalizable sensorimotor control. While this paradigm effectively utilizes large-scale data from both robotic and non-robotic sources, current VLAs primarily focus on direct input--output mappings, lacking the intermediate reasoning steps crucial for complex manipulation tasks. As a result, existing VLAs lack temporal planning or reasoning capabilities. In this paper, we introduce a method that incorporates explicit visual chain-of-thought (CoT) reasoning into vision-language-action models (VLAs) by predicting future image frames autoregressively as visual goals before generating a short action sequence to achieve these goals. We introduce CoT-VLA, a state-of-the-art 7B VLA that can understand and generate visual and action tokens. Our experimental results demonstrate that CoT-VLA achieves strong performance, outperforming the state-of-the-art VLA model by 17% in real-world manipulation tasks and 6% in simulation benchmarks. Project website: https://cot-vla.github.io/
* Project website: https://cot-vla.github.io/
CameraCtrl II: Dynamic Scene Exploration via Camera-controlled Video Diffusion Models
Mar 13, 2025This paper introduces CameraCtrl II, a framework that enables large-scale dynamic scene exploration through a camera-controlled video diffusion model. Previous camera-conditioned video generative models suffer from diminished video dynamics and limited range of viewpoints when generating videos with large camera movement. We take an approach that progressively expands the generation of dynamic scenes -- first enhancing dynamic content within individual video clip, then extending this capability to create seamless explorations across broad viewpoint ranges. Specifically, we construct a dataset featuring a large degree of dynamics with camera parameter annotations for training while designing a lightweight camera injection module and training scheme to preserve dynamics of the pretrained models. Building on these improved single-clip techniques, we enable extended scene exploration by allowing users to iteratively specify camera trajectories for generating coherent video sequences. Experiments across diverse scenarios demonstrate that CameraCtrl Ii enables camera-controlled dynamic scene synthesis with substantially wider spatial exploration than previous approaches.
GroomLight: Hybrid Inverse Rendering for Relightable Human Hair Appearance Modeling
Mar 13, 2025We present GroomLight, a novel method for relightable hair appearance modeling from multi-view images. Existing hair capture methods struggle to balance photorealistic rendering with relighting capabilities. Analytical material models, while physically grounded, often fail to fully capture appearance details. Conversely, neural rendering approaches excel at view synthesis but generalize poorly to novel lighting conditions. GroomLight addresses this challenge by combining the strengths of both paradigms. It employs an extended hair BSDF model to capture primary light transport and a light-aware residual model to reconstruct the remaining details. We further propose a hybrid inverse rendering pipeline to optimize both components, enabling high-fidelity relighting, view synthesis, and material editing. Extensive evaluations on real-world hair data demonstrate state-of-the-art performance of our method.
FLARE: Feed-forward Geometry, Appearance and Camera Estimation from Uncalibrated Sparse Views
Feb 19, 2025We present FLARE, a feed-forward model designed to infer high-quality camera poses and 3D geometry from uncalibrated sparse-view images (i.e., as few as 2-8 inputs), which is a challenging yet practical setting in real-world applications. Our solution features a cascaded learning paradigm with camera pose serving as the critical bridge, recognizing its essential role in mapping 3D structures onto 2D image planes. Concretely, FLARE starts with camera pose estimation, whose results condition the subsequent learning of geometric structure and appearance, optimized through the objectives of geometry reconstruction and novel-view synthesis. Utilizing large-scale public datasets for training, our method delivers state-of-the-art performance in the tasks of pose estimation, geometry reconstruction, and novel view synthesis, while maintaining the inference efficiency (i.e., less than 0.5 seconds). The project page and code can be found at: https://zhanghe3z.github.io/FLARE/
Self-Calibrating Gaussian Splatting for Large Field of View Reconstruction
Feb 13, 2025



In this paper, we present a self-calibrating framework that jointly optimizes camera parameters, lens distortion and 3D Gaussian representations, enabling accurate and efficient scene reconstruction. In particular, our technique enables high-quality scene reconstruction from Large field-of-view (FOV) imagery taken with wide-angle lenses, allowing the scene to be modeled from a smaller number of images. Our approach introduces a novel method for modeling complex lens distortions using a hybrid network that combines invertible residual networks with explicit grids. This design effectively regularizes the optimization process, achieving greater accuracy than conventional camera models. Additionally, we propose a cubemap-based resampling strategy to support large FOV images without sacrificing resolution or introducing distortion artifacts. Our method is compatible with the fast rasterization of Gaussian Splatting, adaptable to a wide variety of camera lens distortion, and demonstrates state-of-the-art performance on both synthetic and real-world datasets.
RelightVid: Temporal-Consistent Diffusion Model for Video Relighting
Jan 27, 2025Diffusion models have demonstrated remarkable success in image generation and editing, with recent advancements enabling albedo-preserving image relighting. However, applying these models to video relighting remains challenging due to the lack of paired video relighting datasets and the high demands for output fidelity and temporal consistency, further complicated by the inherent randomness of diffusion models. To address these challenges, we introduce RelightVid, a flexible framework for video relighting that can accept background video, text prompts, or environment maps as relighting conditions. Trained on in-the-wild videos with carefully designed illumination augmentations and rendered videos under extreme dynamic lighting, RelightVid achieves arbitrary video relighting with high temporal consistency without intrinsic decomposition while preserving the illumination priors of its image backbone.
X-Dyna: Expressive Dynamic Human Image Animation
Jan 20, 2025We introduce X-Dyna, a novel zero-shot, diffusion-based pipeline for animating a single human image using facial expressions and body movements derived from a driving video, that generates realistic, context-aware dynamics for both the subject and the surrounding environment. Building on prior approaches centered on human pose control, X-Dyna addresses key shortcomings causing the loss of dynamic details, enhancing the lifelike qualities of human video animations. At the core of our approach is the Dynamics-Adapter, a lightweight module that effectively integrates reference appearance context into the spatial attentions of the diffusion backbone while preserving the capacity of motion modules in synthesizing fluid and intricate dynamic details. Beyond body pose control, we connect a local control module with our model to capture identity-disentangled facial expressions, facilitating accurate expression transfer for enhanced realism in animated scenes. Together, these components form a unified framework capable of learning physical human motion and natural scene dynamics from a diverse blend of human and scene videos. Comprehensive qualitative and quantitative evaluations demonstrate that X-Dyna outperforms state-of-the-art methods, creating highly lifelike and expressive animations. The code is available at https://github.com/bytedance/X-Dyna.