 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeta-optimized Contrastive Learning for Sequential Recommendation
Apr 26, 2023Contrastive Learning (CL) performances as a rising approach to address the challenge of sparse and noisy recommendation data. Although having achieved promising results, most existing CL methods only perform either hand-crafted data or model augmentation for generating contrastive pairs to find a proper augmentation operation for different datasets, which makes the model hard to generalize. Additionally, since insufficient input data may lead the encoder to learn collapsed embeddings, these CL methods expect a relatively large number of training data (e.g., large batch size or memory bank) to contrast. However, not all contrastive pairs are always informative and discriminative enough for the training processing. Therefore, a more general CL-based recommendation model called Meta-optimized Contrastive Learning for sequential Recommendation (MCLRec) is proposed in this work. By applying both data augmentation and learnable model augmentation operations, this work innovates the standard CL framework by contrasting data and model augmented views for adaptively capturing the informative features hidden in stochastic data augmentation. Moreover, MCLRec utilizes a meta-learning manner to guide the updating of the model augmenters, which helps to improve the quality of contrastive pairs without enlarging the amount of input data. Finally, a contrastive regularization term is considered to encourage the augmentation model to generate more informative augmented views and avoid too similar contrastive pairs within the meta updating. The experimental results on commonly used datasets validate the effectiveness of MCLRec.
Frequency Enhanced Hybrid Attention Network for Sequential Recommendation
Apr 18, 2023



The self-attention mechanism, which equips with a strong capability of modeling long-range dependencies, is one of the extensively used techniques in the sequential recommendation field. However, many recent studies represent that current self-attention based models are low-pass filters and are inadequate to capture high-frequency information. Furthermore, since the items in the user behaviors are intertwined with each other, these models are incomplete to distinguish the inherent periodicity obscured in the time domain. In this work, we shift the perspective to the frequency domain, and propose a novel Frequency Enhanced Hybrid Attention Network for Sequential Recommendation, namely FEARec. In this model, we firstly improve the original time domain self-attention in the frequency domain with a ramp structure to make both low-frequency and high-frequency information could be explicitly learned in our approach. Moreover, we additionally design a similar attention mechanism via auto-correlation in the frequency domain to capture the periodic characteristics and fuse the time and frequency level attention in a union model. Finally, both contrastive learning and frequency regularization are utilized to ensure that multiple views are aligned in both the time domain and frequency domain. Extensive experiments conducted on four widely used benchmark datasets demonstrate that the proposed model performs significantly better than the state-of-the-art approaches.
A Survey on Causal Inference for Recommendation
Mar 21, 2023Recently, causal inference has attracted increasing attention from researchers of recommender systems (RS), which analyzes the relationship between a cause and its effect and has a wide range of real-world applications in multiple fields. Causal inference can model the causality in recommender systems like confounding effects and deal with counterfactual problems such as offline policy evaluation and data augmentation. Although there are already some valuable surveys on causal recommendations, these surveys introduce approaches in a relatively isolated way and lack theoretical analysis of existing methods. Due to the unfamiliarity with causality to RS researchers, it is both necessary and challenging to comprehensively review the relevant studies from the perspective of causal theory, which might be instructive for the readers to propose new approaches in practice. This survey attempts to provide a systematic review of up-to-date papers in this area from a theoretical standpoint. Firstly, we introduce the fundamental concepts of causal inference as the basis of the following review. Then we propose a new taxonomy from the perspective of causal techniques and further discuss technical details about how existing methods apply causal inference to address specific recommender issues. Finally, we highlight some promising directions for future research in this field.
RHCO: A Relation-aware Heterogeneous Graph Neural Network with Contrastive Learning for Large-scale Graphs
Nov 20, 2022



Heterogeneous graph neural networks (HGNNs) have been widely applied in heterogeneous information network tasks, while most HGNNs suffer from poor scalability or weak representation when they are applied to large-scale heterogeneous graphs. To address these problems, we propose a novel Relation-aware Heterogeneous Graph Neural Network with Contrastive Learning (RHCO) for large-scale heterogeneous graph representation learning. Unlike traditional heterogeneous graph neural networks, we adopt the contrastive learning mechanism to deal with the complex heterogeneity of large-scale heterogeneous graphs. We first learn relation-aware node embeddings under the network schema view. Then we propose a novel positive sample selection strategy to choose meaningful positive samples. After learning node embeddings under the positive sample graph view, we perform a cross-view contrastive learning to obtain the final node representations. Moreover, we adopt the label smoothing technique to boost the performance of RHCO. Extensive experiments on three large-scale academic heterogeneous graph datasets show that RHCO achieves best performance over the state-of-the-art models.
Pruning Pre-trained Language Models Without Fine-Tuning
Oct 12, 2022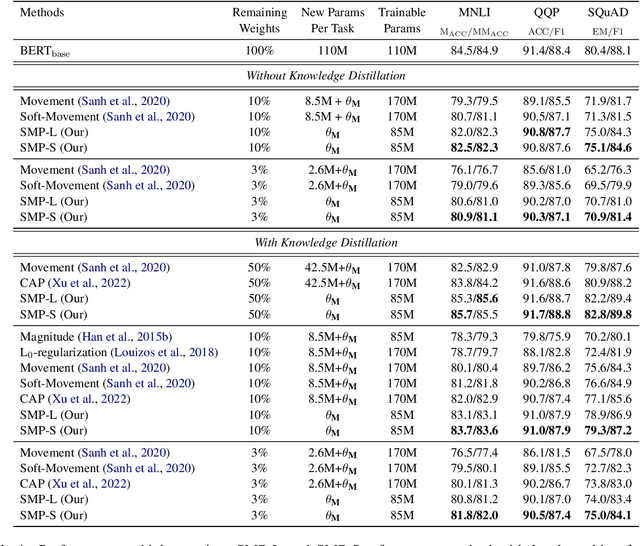
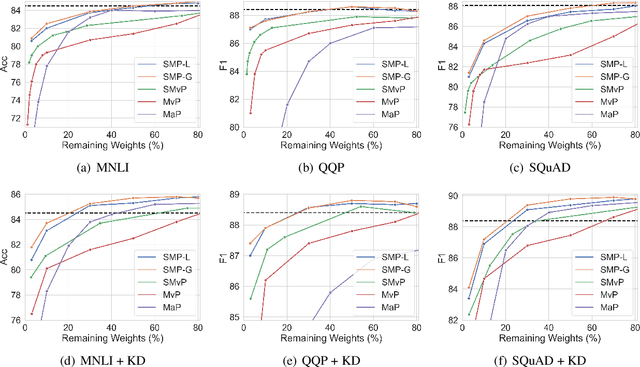

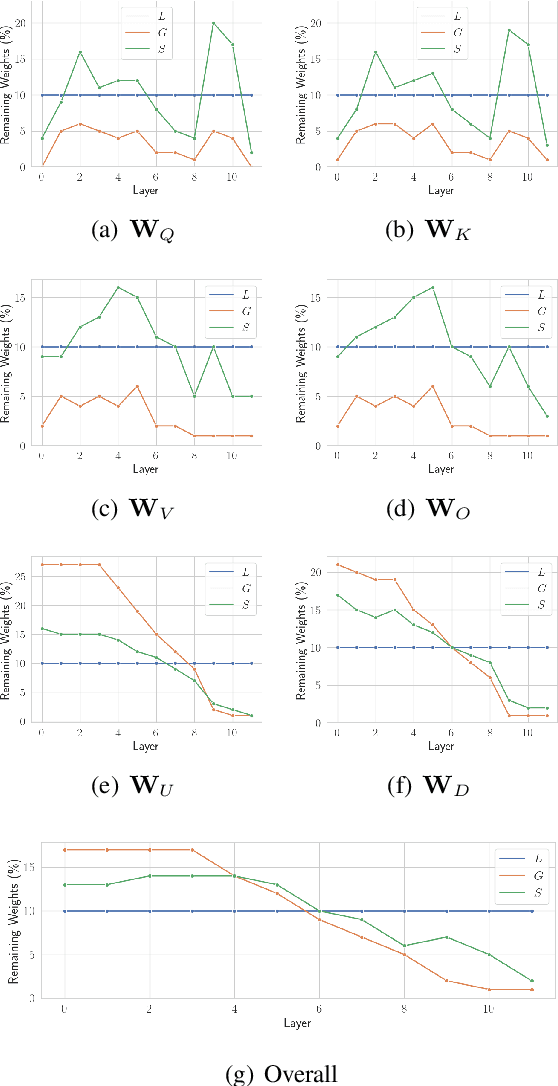
To overcome the overparameterized problem in Pre-trained Language Models (PLMs), pruning is widely used as a simple and straightforward compression method by directly removing unimportant weights. Previous first-order methods successfully compress PLMs to extremely high sparsity with little performance drop. These methods, such as movement pruning, use first-order information to prune PLMs while fine-tuning the remaining weights. In this work, we argue fine-tuning is redundant for first-order pruning, since first-order pruning is sufficient to converge PLMs to downstream tasks without fine-tuning. Under this motivation, we propose Static Model Pruning (SMP), which only uses first-order pruning to adapt PLMs to downstream tasks while achieving the target sparsity level. In addition, we also design a new masking function and training objective to further improve SMP. Extensive experiments at various sparsity levels show SMP has significant improvements over first-order and zero-order methods. Unlike previous first-order methods, SMP is also applicable to low sparsity and outperforms zero-order methods. Meanwhile, SMP is more parameter efficient than other methods due to it does not require fine-tuning.
A Hierarchical Interactive Network for Joint Span-based Aspect-Sentiment Analysis
Aug 24, 2022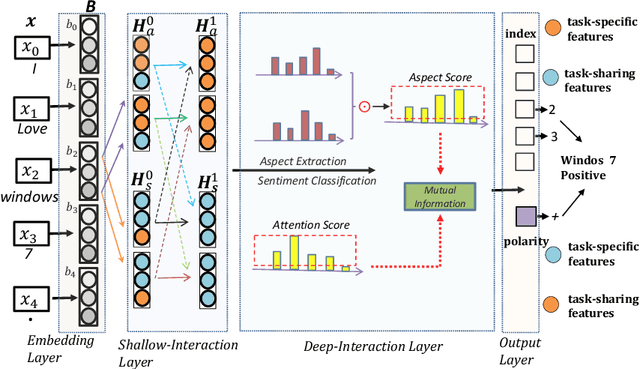
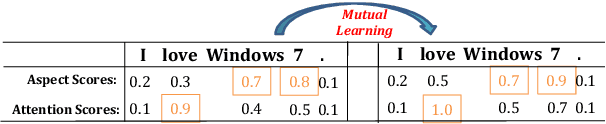
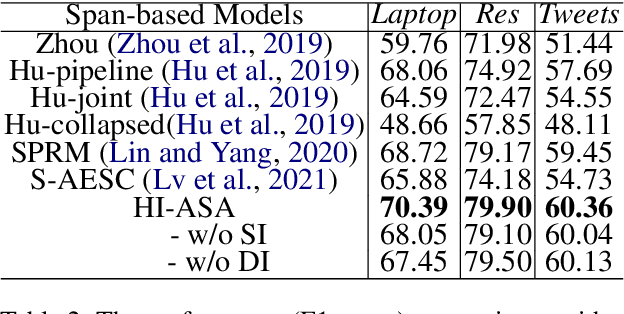
Recently, some span-based methods have achieved encouraging performances for joint aspect-sentiment analysis, which first extract aspects (aspect extraction) by detecting aspect boundaries and then classify the span-level sentiments (sentiment classification). However, most existing approaches either sequentially extract task-specific features, leading to insufficient feature interactions, or they encode aspect features and sentiment features in a parallel manner, implying that feature representation in each task is largely independent of each other except for input sharing. Both of them ignore the internal correlations between the aspect extraction and sentiment classification. To solve this problem, we novelly propose a hierarchical interactive network (HI-ASA) to model two-way interactions between two tasks appropriately, where the hierarchical interactions involve two steps: shallow-level interaction and deep-level interaction. First, we utilize cross-stitch mechanism to combine the different task-specific features selectively as the input to ensure proper two-way interactions. Second, the mutual information technique is applied to mutually constrain learning between two tasks in the output layer, thus the aspect input and the sentiment input are capable of encoding features of the other task via backpropagation. Extensive experiments on three real-world datasets demonstrate HI-ASA's superiority over baselines.
Customized Conversational Recommender Systems
Jun 30, 2022
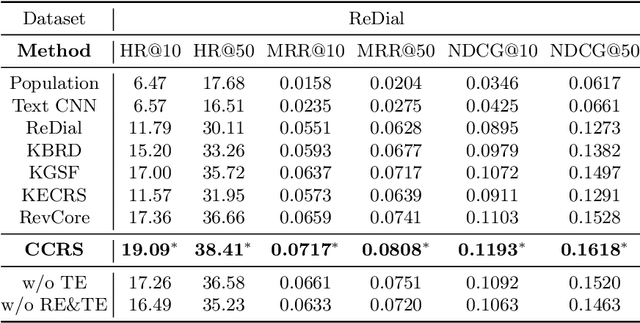
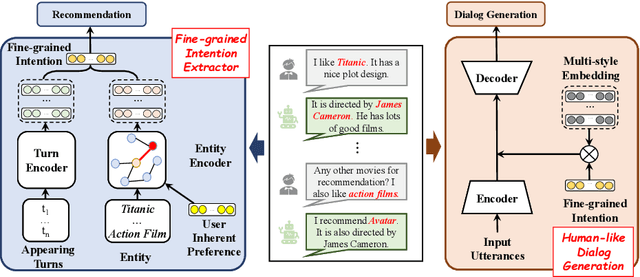
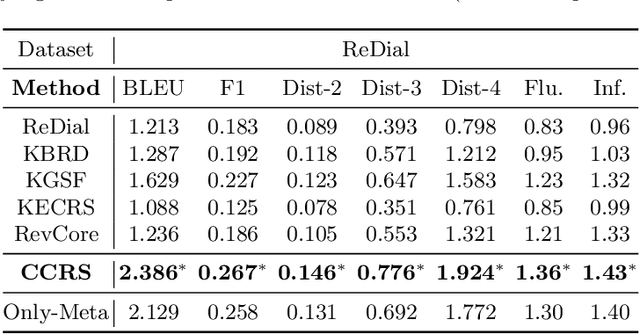
Conversational recommender systems (CRS) aim to capture user's current intentions and provide recommendations through real-time multi-turn conversational interactions. As a human-machine interactive system, it is essential for CRS to improve the user experience. However, most CRS methods neglect the importance of user experience. In this paper, we propose two key points for CRS to improve the user experience: (1) Speaking like a human, human can speak with different styles according to the current dialogue context. (2) Identifying fine-grained intentions, even for the same utterance, different users have diverse finegrained intentions, which are related to users' inherent preference. Based on the observations, we propose a novel CRS model, coined Customized Conversational Recommender System (CCRS), which customizes CRS model for users from three perspectives. For human-like dialogue services, we propose multi-style dialogue response generator which selects context-aware speaking style for utterance generation. To provide personalized recommendations, we extract user's current fine-grained intentions from dialogue context with the guidance of user's inherent preferences. Finally, to customize the model parameters for each user, we train the model from the meta-learning perspective. Extensive experiments and a series of analyses have shown the superiority of our CCRS on both the recommendation and dialogue services.
Memory-Guided Multi-View Multi-Domain Fake News Detection
Jun 26, 2022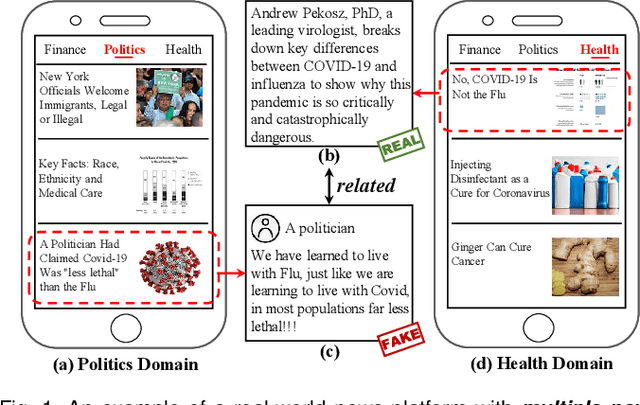
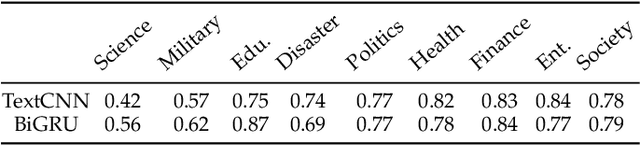
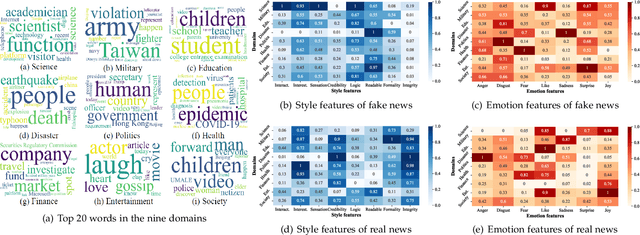
The wide spread of fake news is increasingly threatening both individuals and society. Great efforts have been made for automatic fake news detection on a single domain (e.g., politics). However, correlations exist commonly across multiple news domains, and thus it is promising to simultaneously detect fake news of multiple domains. Based on our analysis, we pose two challenges in multi-domain fake news detection: 1) domain shift, caused by the discrepancy among domains in terms of words, emotions, styles, etc. 2) domain labeling incompleteness, stemming from the real-world categorization that only outputs one single domain label, regardless of topic diversity of a news piece. In this paper, we propose a Memory-guided Multi-view Multi-domain Fake News Detection Framework (M$^3$FEND) to address these two challenges. We model news pieces from a multi-view perspective, including semantics, emotion, and style. Specifically, we propose a Domain Memory Bank to enrich domain information which could discover potential domain labels based on seen news pieces and model domain characteristics. Then, with enriched domain information as input, a Domain Adapter could adaptively aggregate discriminative information from multiple views for news in various domains. Extensive offline experiments on English and Chinese datasets demonstrate the effectiveness of M$^3$FEND, and online tests verify its superiority in practice. Our code is available at https://github.com/ICTMCG/M3FEND.
Joint Abductive and Inductive Neural Logical Reasoning
May 29, 2022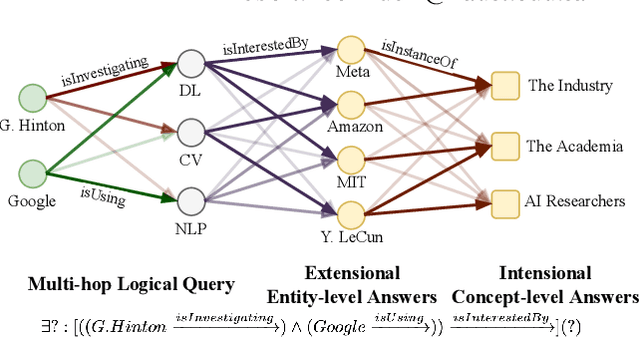

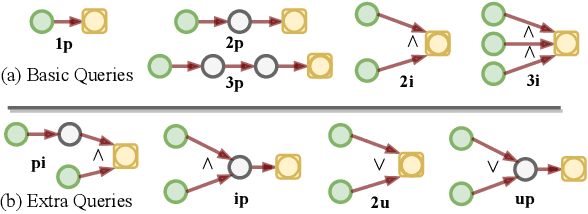
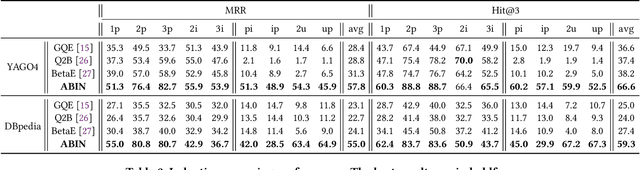
Neural logical reasoning (NLR) is a fundamental task in knowledge discovery and artificial intelligence. NLR aims at answering multi-hop queries with logical operations on structured knowledge bases based on distributed representations of queries and answers. While previous neural logical reasoners can give specific entity-level answers, i.e., perform inductive reasoning from the perspective of logic theory, they are not able to provide descriptive concept-level answers, i.e., perform abductive reasoning, where each concept is a summary of a set of entities. In particular, the abductive reasoning task attempts to infer the explanations of each query with descriptive concepts, which make answers comprehensible to users and is of great usefulness in the field of applied ontology. In this work, we formulate the problem of the joint abductive and inductive neural logical reasoning (AI-NLR), solving which needs to address challenges in incorporating, representing, and operating on concepts. We propose an original solution named ABIN for AI-NLR. Firstly, we incorporate description logic-based ontological axioms to provide the source of concepts. Then, we represent concepts and queries as fuzzy sets, i.e., sets whose elements have degrees of membership, to bridge concepts and queries with entities. Moreover, we design operators involving concepts on top of the fuzzy set representation of concepts and queries for optimization and inference. Extensive experimental results on two real-world datasets demonstrate the effectiveness of ABIN for AI-NLR.
Detect Professional Malicious User with Metric Learning in Recommender Systems
May 19, 2022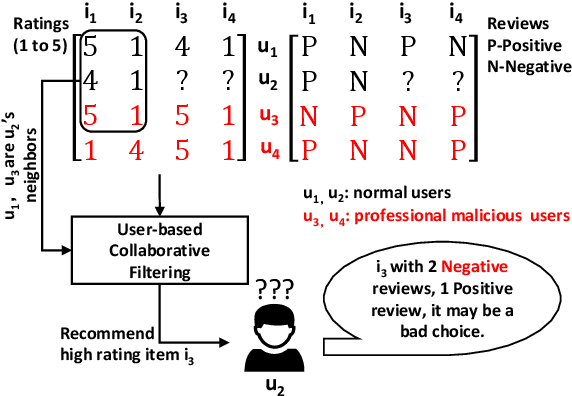

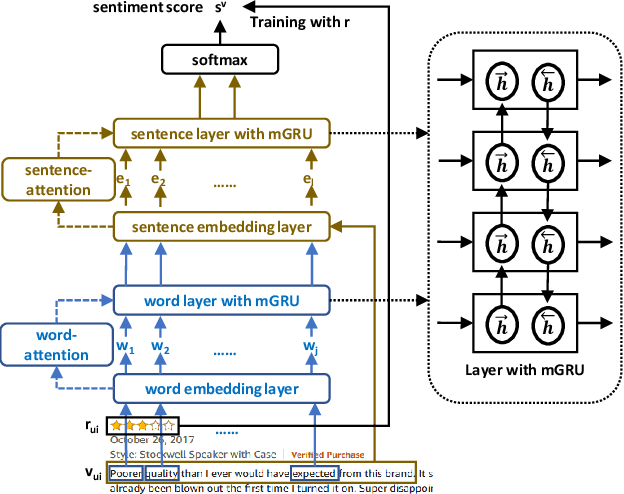
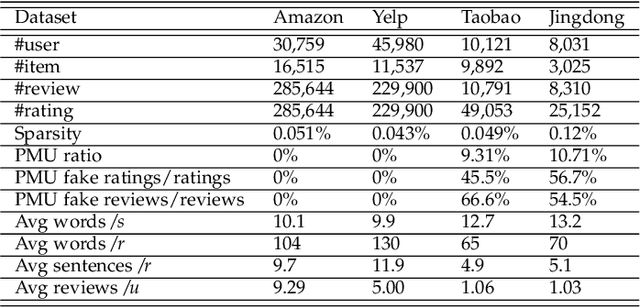
In e-commerce, online retailers are usually suffering from professional malicious users (PMUs), who utilize negative reviews and low ratings to their consumed products on purpose to threaten the retailers for illegal profits. Specifically, there are three challenges for PMU detection: 1) professional malicious users do not conduct any abnormal or illegal interactions (they never concurrently leave too many negative reviews and low ratings at the same time), and they conduct masking strategies to disguise themselves. Therefore, conventional outlier detection methods are confused by their masking strategies. 2) the PMU detection model should take both ratings and reviews into consideration, which makes PMU detection a multi-modal problem. 3) there are no datasets with labels for professional malicious users in public, which makes PMU detection an unsupervised learning problem. To this end, we propose an unsupervised multi-modal learning model: MMD, which employs Metric learning for professional Malicious users Detection with both ratings and reviews. MMD first utilizes a modified RNN to project the informational review into a sentiment score, which jointly considers the ratings and reviews. Then professional malicious user profiling (MUP) is proposed to catch the sentiment gap between sentiment scores and ratings. MUP filters the users and builds a candidate PMU set. We apply a metric learning-based clustering to learn a proper metric matrix for PMU detection. Finally, we can utilize this metric and labeled users to detect PMUs. Specifically, we apply the attention mechanism in metric learning to improve the model's performance. The extensive experiments in four datasets demonstrate that our proposed method can solve this unsupervised detection problem. Moreover, the performance of the state-of-the-art recommender models is enhanced by taking MMD as a preprocessing stage.