 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBrainCast: A Spatio-Temporal Forecasting Model for Whole-Brain fMRI Time Series Prediction
Mar 09, 2026Functional magnetic resonance imaging (fMRI) enables noninvasive investigation of brain function, while short clinical scan durations, arising from human and non-human factors, usually lead to reduced data quality and limited statistical power for neuroimaging research. In this paper, we propose BrainCast, a novel spatio-temporal forecasting framework specifically tailored for whole-brain fMRI time series forecasting, to extend informative fMRI time series without additional data acquisition. It formulates fMRI time series forecasting as a multivariate time series prediction task and jointly models temporal dynamics within regions of interest (ROIs) and spatial interactions across ROIs. Specifically, BrainCast integrates a Spatial Interaction Awareness module to characterize inter-ROI dependencies via embedding every ROI time series as a token, a Temporal Feature Refinement module to capture intrinsic neural dynamics within each ROI by enhancing both low- and high-energy temporal components of fMRI time series at the ROI level, and a Spatio-temporal Pattern Alignment module to combine spatial and temporal representations for producing informative whole-brain features. Experimental results on resting-state and task fMRI datasets from the Human Connectome Project demonstrate the superiority of BrainCast over state-of-the-art time series forecasting baselines. Moreover, fMRI time series extended by BrainCast improve downstream cognitive ability prediction, highlighting the clinical and neuroscientific impact brought by whole-brain fMRI time series forecasting in scenarios with restricted scan durations.
FCN-LLM: Empower LLM for Brain Functional Connectivity Network Understanding via Graph-level Multi-task Instruction Tuning
Mar 01, 2026Large Language Models have achieved remarkable success in language understanding and reasoning, and their multimodal extensions enable comprehension of images, video, and audio. Inspired by this, foundation models for brain functional connectivity networks derived from resting-state fMRI have shown promise in clinical tasks. However, existing methods do not align FCNs with the text modality, limiting the ability of LLMs to directly understand FCNs. To address this, we propose FCN-LLM, a framework that enables LLMs to understand FCNs through graph-level, multi-task instruction tuning. Our approach employs a multi-scale FCN encoder capturing brain-region, functional subnetwork, and whole-brain features, projecting them into the semantic space of LLM. We design multi-paradigm instruction tasks covering 19 subject-specific attributes across demographics, phenotypes, and psychiatric conditions. A multi-stage learning strategy first aligns FCN embeddings with the LLM and then jointly fine-tunes the entire model to capture high-level semantic information. Experiments on a large-scale, multi-site FCN database show that FCN-LLM achieves strong zero-shot generalization on unseen datasets, outperforming conventional supervised and foundation models. This work introduces a new paradigm for integrating brain functional networks with LLMs, offering a flexible and interpretable framework for neuroscience.
ReGLA: Efficient Receptive-Field Modeling with Gated Linear Attention Network
Feb 05, 2026Balancing accuracy and latency on high-resolution images is a critical challenge for lightweight models, particularly for Transformer-based architectures that often suffer from excessive latency. To address this issue, we introduce \textbf{ReGLA}, a series of lightweight hybrid networks, which integrates efficient convolutions for local feature extraction with ReLU-based gated linear attention for global modeling. The design incorporates three key innovations: the Efficient Large Receptive Field (ELRF) module for enhancing convolutional efficiency while preserving a large receptive field; the ReLU Gated Modulated Attention (RGMA) module for maintaining linear complexity while enhancing local feature representation; and a multi-teacher distillation strategy to boost performance on downstream tasks. Extensive experiments validate the superiority of ReGLA; particularly the ReGLA-M achieves \textbf{80.85\%} Top-1 accuracy on ImageNet-1K at $224px$, with only \textbf{4.98 ms} latency at $512px$. Furthermore, ReGLA outperforms similarly scaled iFormer models in downstream tasks, achieving gains of \textbf{3.1\%} AP on COCO object detection and \textbf{3.6\%} mIoU on ADE20K semantic segmentation, establishing it as a state-of-the-art solution for high-resolution visual applications.
FUGC: Benchmarking Semi-Supervised Learning Methods for Cervical Segmentation
Jan 22, 2026Accurate segmentation of cervical structures in transvaginal ultrasound (TVS) is critical for assessing the risk of spontaneous preterm birth (PTB), yet the scarcity of labeled data limits the performance of supervised learning approaches. This paper introduces the Fetal Ultrasound Grand Challenge (FUGC), the first benchmark for semi-supervised learning in cervical segmentation, hosted at ISBI 2025. FUGC provides a dataset of 890 TVS images, including 500 training images, 90 validation images, and 300 test images. Methods were evaluated using the Dice Similarity Coefficient (DSC), Hausdorff Distance (HD), and runtime (RT), with a weighted combination of 0.4/0.4/0.2. The challenge attracted 10 teams with 82 participants submitting innovative solutions. The best-performing methods for each individual metric achieved 90.26\% mDSC, 38.88 mHD, and 32.85 ms RT, respectively. FUGC establishes a standardized benchmark for cervical segmentation, demonstrates the efficacy of semi-supervised methods with limited labeled data, and provides a foundation for AI-assisted clinical PTB risk assessment.
WSD-MIL: Window Scale Decay Multiple Instance Learning for Whole Slide Image Classification
Dec 23, 2025In recent years, the integration of pre-trained foundational models with multiple instance learning (MIL) has improved diagnostic accuracy in computational pathology. However, existing MIL methods focus on optimizing feature extractors and aggregation strategies while overlooking the complex semantic relationships among instances within whole slide image (WSI). Although Transformer-based MIL approaches aiming to model instance dependencies, the quadratic computational complexity limits their scalability to large-scale WSIs. Moreover, due to the pronounced variations in tumor region scales across different WSIs, existing Transformer-based methods employing fixed-scale attention mechanisms face significant challenges in precisely capturing local instance correlations and fail to account for the distance-based decay effect of patch relevance. To address these challenges, we propose window scale decay MIL (WSD-MIL), designed to enhance the capacity to model tumor regions of varying scales while improving computational efficiency. WSD-MIL comprises: 1) a window scale decay based attention module, which employs a cluster-based sampling strategy to reduce computational costs while progressively decaying attention window-scale to capture local instance relationships at varying scales; and 2) a squeeze-and-excitation based region gate module, which dynamically adjusts window weights to enhance global information modeling. Experimental results demonstrate that WSD-MIL achieves state-of-the-art performance on the CAMELYON16 and TCGA-BRCA datasets while reducing 62% of the computational memory. The code will be publicly available.
Impact of Phonetics on Speaker Identity in Adversarial Voice Attack
Sep 18, 2025Adversarial perturbations in speech pose a serious threat to automatic speech recognition (ASR) and speaker verification by introducing subtle waveform modifications that remain imperceptible to humans but can significantly alter system outputs. While targeted attacks on end-to-end ASR models have been widely studied, the phonetic basis of these perturbations and their effect on speaker identity remain underexplored. In this work, we analyze adversarial audio at the phonetic level and show that perturbations exploit systematic confusions such as vowel centralization and consonant substitutions. These distortions not only mislead transcription but also degrade phonetic cues critical for speaker verification, leading to identity drift. Using DeepSpeech as our ASR target, we generate targeted adversarial examples and evaluate their impact on speaker embeddings across genuine and impostor samples. Results across 16 phonetically diverse target phrases demonstrate that adversarial audio induces both transcription errors and identity drift, highlighting the need for phonetic-aware defenses to ensure the robustness of ASR and speaker recognition systems.
PepThink-R1: LLM for Interpretable Cyclic Peptide Optimization with CoT SFT and Reinforcement Learning
Aug 20, 2025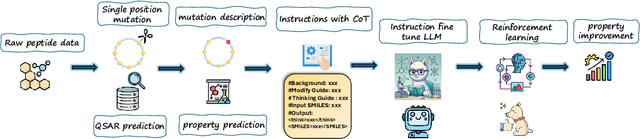
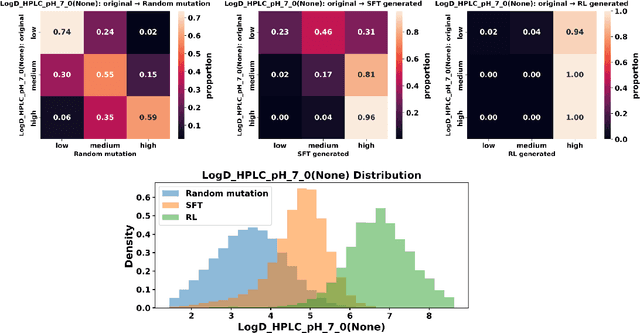
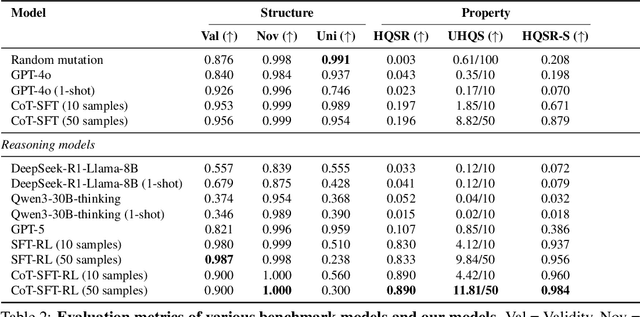
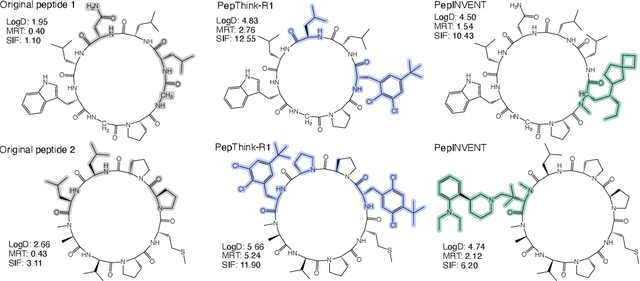
Designing therapeutic peptides with tailored properties is hindered by the vastness of sequence space, limited experimental data, and poor interpretability of current generative models. To address these challenges, we introduce PepThink-R1, a generative framework that integrates large language models (LLMs) with chain-of-thought (CoT) supervised fine-tuning and reinforcement learning (RL). Unlike prior approaches, PepThink-R1 explicitly reasons about monomer-level modifications during sequence generation, enabling interpretable design choices while optimizing for multiple pharmacological properties. Guided by a tailored reward function balancing chemical validity and property improvements, the model autonomously explores diverse sequence variants. We demonstrate that PepThink-R1 generates cyclic peptides with significantly enhanced lipophilicity, stability, and exposure, outperforming existing general LLMs (e.g., GPT-5) and domain-specific baseline in both optimization success and interpretability. To our knowledge, this is the first LLM-based peptide design framework that combines explicit reasoning with RL-driven property control, marking a step toward reliable and transparent peptide optimization for therapeutic discovery.
Human-Aligned Bench: Fine-Grained Assessment of Reasoning Ability in MLLMs vs. Humans
May 16, 2025The goal of achieving Artificial General Intelligence (AGI) is to imitate humans and surpass them. Models such as OpenAI's o1, o3, and DeepSeek's R1 have demonstrated that large language models (LLMs) with human-like reasoning capabilities exhibit exceptional performance and are being gradually integrated into multimodal large language models (MLLMs). However, whether these models possess capabilities comparable to humans in handling reasoning tasks remains unclear at present. In this paper, we propose Human-Aligned Bench, a benchmark for fine-grained alignment of multimodal reasoning with human performance. Specifically, we collected 9,794 multimodal questions that solely rely on contextual reasoning, including bilingual (Chinese and English) multimodal questions and pure text-based questions, encompassing four question types: visual reasoning, definition judgment, analogical reasoning, and logical judgment. More importantly, each question is accompanied by human success rates and options that humans are prone to choosing incorrectly. Extensive experiments on the Human-Aligned Bench reveal notable differences between the performance of current MLLMs in multimodal reasoning and human performance. The findings on our benchmark provide insights into the development of the next-generation models.
Learning 3D Medical Image Models From Brain Functional Connectivity Network Supervision For Mental Disorder Diagnosis
Mar 06, 2025



In MRI-based mental disorder diagnosis, most previous studies focus on functional connectivity network (FCN) derived from functional MRI (fMRI). However, the small size of annotated fMRI datasets restricts its wide application. Meanwhile, structural MRIs (sMRIs), such as 3D T1-weighted (T1w) MRI, which are commonly used and readily accessible in clinical settings, are often overlooked. To integrate the complementary information from both function and structure for improved diagnostic accuracy, we propose CINP (Contrastive Image-Network Pre-training), a framework that employs contrastive learning between sMRI and FCN. During pre-training, we incorporate masked image modeling and network-image matching to enhance visual representation learning and modality alignment. Since the CINP facilitates knowledge transfer from FCN to sMRI, we introduce network prompting. It utilizes only sMRI from suspected patients and a small amount of FCNs from different patient classes for diagnosing mental disorders, which is practical in real-world clinical scenario. The competitive performance on three mental disorder diagnosis tasks demonstrate the effectiveness of the CINP in integrating multimodal MRI information, as well as the potential of incorporating sMRI into clinical diagnosis using network prompting.
A Scalable Crawling Algorithm Utilizing Noisy Change-Indicating Signals
Feb 04, 2025Web refresh crawling is the problem of keeping a cache of web pages fresh, that is, having the most recent copy available when a page is requested, given a limited bandwidth available to the crawler. Under the assumption that the change and request events, resp., to each web page follow independent Poisson processes, the optimal scheduling policy was derived by Azar et al. 2018. In this paper, we study an extension of this problem where side information indicating content changes, such as various types of web pings, for example, signals from sitemaps, content delivery networks, etc., is available. Incorporating such side information into the crawling policy is challenging, because (i) the signals can be noisy with false positive events and with missing change events; and (ii) the crawler should achieve a fair performance over web pages regardless of the quality of the side information, which might differ from web page to web page. We propose a scalable crawling algorithm which (i) uses the noisy side information in an optimal way under mild assumptions; (ii) can be deployed without heavy centralized computation; (iii) is able to crawl web pages at a constant total rate without spikes in the total bandwidth usage over any time interval, and automatically adapt to the new optimal solution when the total bandwidth changes without centralized computation. Experiments clearly demonstrate the versatility of our approach.