 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUATVR: Uncertainty-Adaptive Text-Video Retrieval
Jan 16, 2023With the explosive growth of web videos and emerging large-scale vision-language pre-training models, e.g., CLIP, retrieving videos of interest with text instructions has attracted increasing attention. A common practice is to transfer text-video pairs to the same embedding space and craft cross-modal interactions with certain entities in specific granularities for semantic correspondence. Unfortunately, the intrinsic uncertainties of optimal entity combinations in appropriate granularities for cross-modal queries are understudied, which is especially critical for modalities with hierarchical semantics, e.g., video, text, etc. In this paper, we propose an Uncertainty-Adaptive Text-Video Retrieval approach, termed UATVR, which models each look-up as a distribution matching procedure. Concretely, we add additional learnable tokens in the encoders to adaptively aggregate multi-grained semantics for flexible high-level reasoning. In the refined embedding space, we represent text-video pairs as probabilistic distributions where prototypes are sampled for matching evaluation. Comprehensive experiments on four benchmarks justify the superiority of our UATVR, which achieves new state-of-the-art results on MSR-VTT (50.8%), VATEX (64.5%), MSVD (49.7%), and DiDeMo (45.8%). The code is available in supplementary materials and will be released publicly soon.
AdaCM: Adaptive ColorMLP for Real-Time Universal Photo-realistic Style Transfer
Dec 03, 2022Photo-realistic style transfer aims at migrating the artistic style from an exemplar style image to a content image, producing a result image without spatial distortions or unrealistic artifacts. Impressive results have been achieved by recent deep models. However, deep neural network based methods are too expensive to run in real-time. Meanwhile, bilateral grid based methods are much faster but still contain artifacts like overexposure. In this work, we propose the \textbf{Adaptive ColorMLP (AdaCM)}, an effective and efficient framework for universal photo-realistic style transfer. First, we find the complex non-linear color mapping between input and target domain can be efficiently modeled by a small multi-layer perceptron (ColorMLP) model. Then, in \textbf{AdaCM}, we adopt a CNN encoder to adaptively predict all parameters for the ColorMLP conditioned on each input content and style image pair. Experimental results demonstrate that AdaCM can generate vivid and high-quality stylization results. Meanwhile, our AdaCM is ultrafast and can process a 4K resolution image in 6ms on one V100 GPU.
RRSR:Reciprocal Reference-based Image Super-Resolution with Progressive Feature Alignment and Selection
Nov 08, 2022



Reference-based image super-resolution (RefSR) is a promising SR branch and has shown great potential in overcoming the limitations of single image super-resolution. While previous state-of-the-art RefSR methods mainly focus on improving the efficacy and robustness of reference feature transfer, it is generally overlooked that a well reconstructed SR image should enable better SR reconstruction for its similar LR images when it is referred to as. Therefore, in this work, we propose a reciprocal learning framework that can appropriately leverage such a fact to reinforce the learning of a RefSR network. Besides, we deliberately design a progressive feature alignment and selection module for further improving the RefSR task. The newly proposed module aligns reference-input images at multi-scale feature spaces and performs reference-aware feature selection in a progressive manner, thus more precise reference features can be transferred into the input features and the network capability is enhanced. Our reciprocal learning paradigm is model-agnostic and it can be applied to arbitrary RefSR models. We empirically show that multiple recent state-of-the-art RefSR models can be consistently improved with our reciprocal learning paradigm. Furthermore, our proposed model together with the reciprocal learning strategy sets new state-of-the-art performances on multiple benchmarks.
It Takes Two: Masked Appearance-Motion Modeling for Self-supervised Video Transformer Pre-training
Oct 11, 2022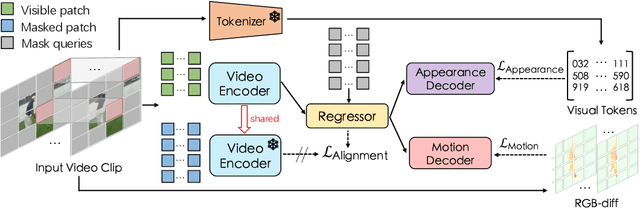

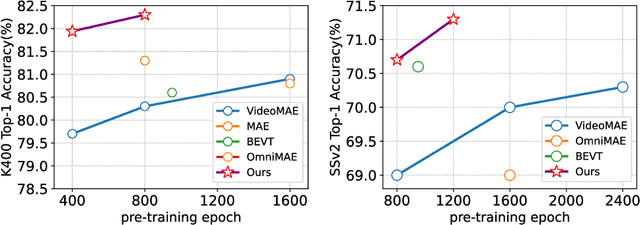
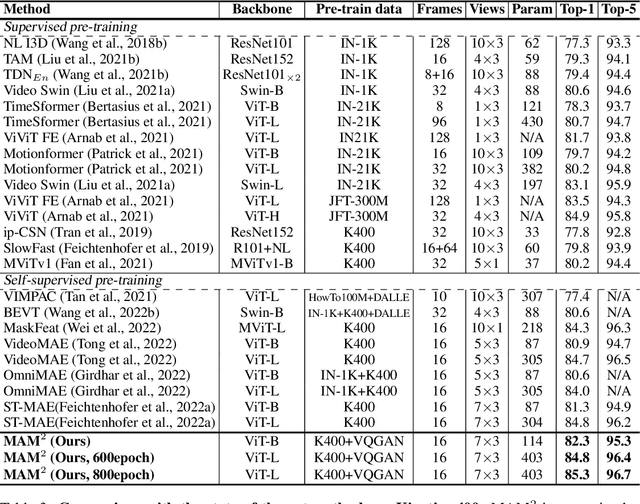
Self-supervised video transformer pre-training has recently benefited from the mask-and-predict pipeline. They have demonstrated outstanding effectiveness on downstream video tasks and superior data efficiency on small datasets. However, temporal relation is not fully exploited by these methods. In this work, we explicitly investigate motion cues in videos as extra prediction target and propose our Masked Appearance-Motion Modeling (MAM2) framework. Specifically, we design an encoder-regressor-decoder pipeline for this task. The regressor separates feature encoding and pretext tasks completion, such that the feature extraction process is completed adequately by the encoder. In order to guide the encoder to fully excavate spatial-temporal features, two separate decoders are used for two pretext tasks of disentangled appearance and motion prediction. We explore various motion prediction targets and figure out RGB-difference is simple yet effective. As for appearance prediction, VQGAN codes are leveraged as prediction target. With our pre-training pipeline, convergence can be remarkably speed up, e.g., we only require half of epochs than state-of-the-art VideoMAE (400 v.s. 800) to achieve the competitive performance. Extensive experimental results prove that our method learns generalized video representations. Notably, our MAM2 with ViT-B achieves 82.3% on Kinects-400, 71.3% on Something-Something V2, 91.5% on UCF101, and 62.5% on HMDB51.
CODER: Coupled Diversity-Sensitive Momentum Contrastive Learning for Image-Text Retrieval
Aug 21, 2022
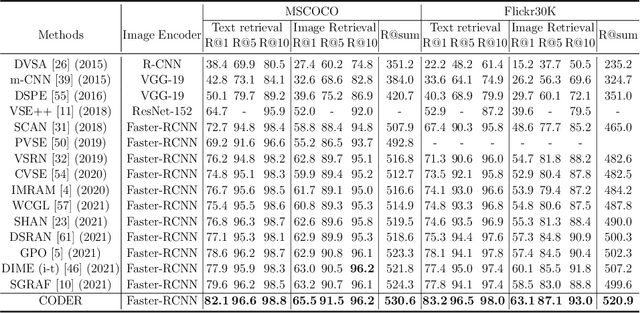
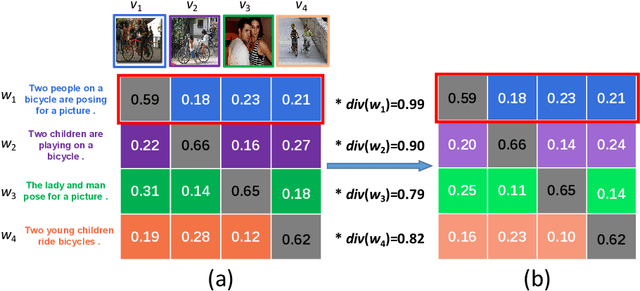
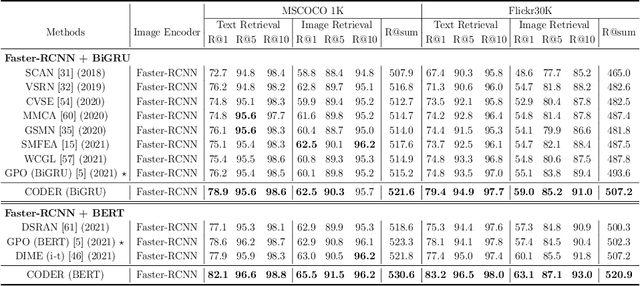
Image-Text Retrieval (ITR) is challenging in bridging visual and lingual modalities. Contrastive learning has been adopted by most prior arts. Except for limited amount of negative image-text pairs, the capability of constrastive learning is restricted by manually weighting negative pairs as well as unawareness of external knowledge. In this paper, we propose our novel Coupled Diversity-Sensitive Momentum Constrastive Learning (CODER) for improving cross-modal representation. Firstly, a novel diversity-sensitive contrastive learning (DCL) architecture is invented. We introduce dynamic dictionaries for both modalities to enlarge the scale of image-text pairs, and diversity-sensitiveness is achieved by adaptive negative pair weighting. Furthermore, two branches are designed in CODER. One learns instance-level embeddings from image/text, and it also generates pseudo online clustering labels for its input image/text based on their embeddings. Meanwhile, the other branch learns to query from commonsense knowledge graph to form concept-level descriptors for both modalities. Afterwards, both branches leverage DCL to align the cross-modal embedding spaces while an extra pseudo clustering label prediction loss is utilized to promote concept-level representation learning for the second branch. Extensive experiments conducted on two popular benchmarks, i.e. MSCOCO and Flicker30K, validate CODER remarkably outperforms the state-of-the-art approaches.
Boosting Video-Text Retrieval with Explicit High-Level Semantics
Aug 09, 2022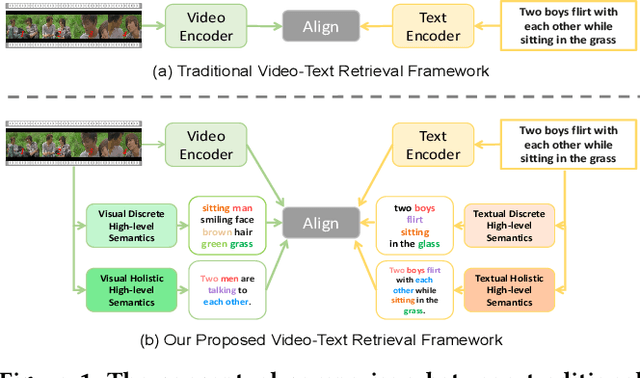
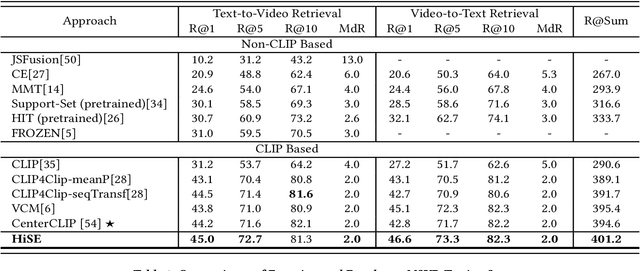
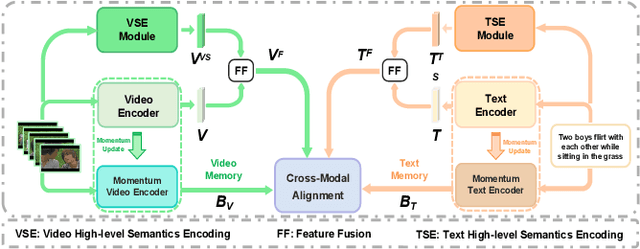
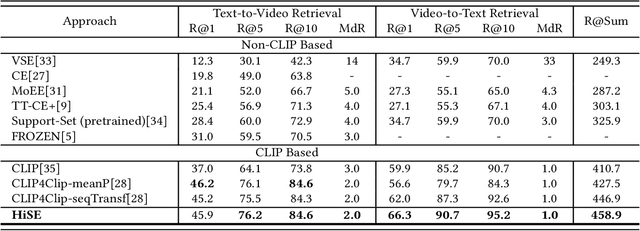
Video-text retrieval (VTR) is an attractive yet challenging task for multi-modal understanding, which aims to search for relevant video (text) given a query (video). Existing methods typically employ completely heterogeneous visual-textual information to align video and text, whilst lacking the awareness of homogeneous high-level semantic information residing in both modalities. To fill this gap, in this work, we propose a novel visual-linguistic aligning model named HiSE for VTR, which improves the cross-modal representation by incorporating explicit high-level semantics. First, we explore the hierarchical property of explicit high-level semantics, and further decompose it into two levels, i.e. discrete semantics and holistic semantics. Specifically, for visual branch, we exploit an off-the-shelf semantic entity predictor to generate discrete high-level semantics. In parallel, a trained video captioning model is employed to output holistic high-level semantics. As for the textual modality, we parse the text into three parts including occurrence, action and entity. In particular, the occurrence corresponds to the holistic high-level semantics, meanwhile both action and entity represent the discrete ones. Then, different graph reasoning techniques are utilized to promote the interaction between holistic and discrete high-level semantics. Extensive experiments demonstrate that, with the aid of explicit high-level semantics, our method achieves the superior performance over state-of-the-art methods on three benchmark datasets, including MSR-VTT, MSVD and DiDeMo.
Neural Color Operators for Sequential Image Retouching
Jul 17, 2022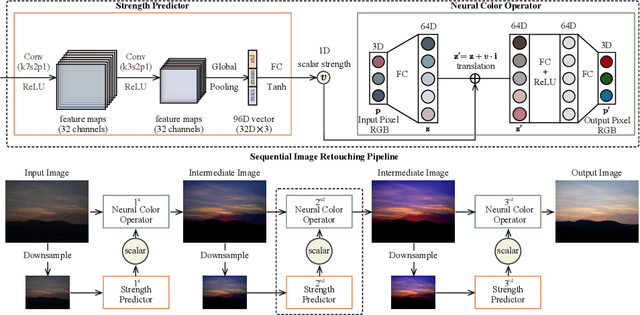
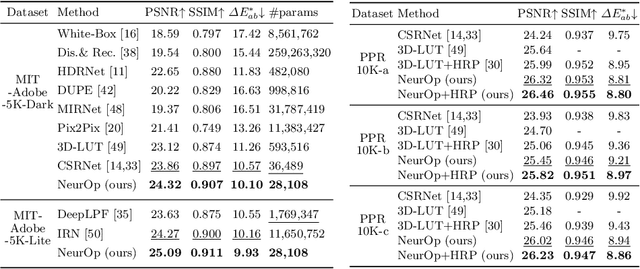


We propose a novel image retouching method by modeling the retouching process as performing a sequence of newly introduced trainable neural color operators. The neural color operator mimics the behavior of traditional color operators and learns pixelwise color transformation while its strength is controlled by a scalar. To reflect the homomorphism property of color operators, we employ equivariant mapping and adopt an encoder-decoder structure which maps the non-linear color transformation to a much simpler transformation (i.e., translation) in a high dimensional space. The scalar strength of each neural color operator is predicted using CNN based strength predictors by analyzing global image statistics. Overall, our method is rather lightweight and offers flexible controls. Experiments and user studies on public datasets show that our method consistently achieves the best results compared with SOTA methods in both quantitative measures and visual qualities. The code and data will be made publicly available.
OSOP: A Multi-Stage One Shot Object Pose Estimation Framework
Mar 30, 2022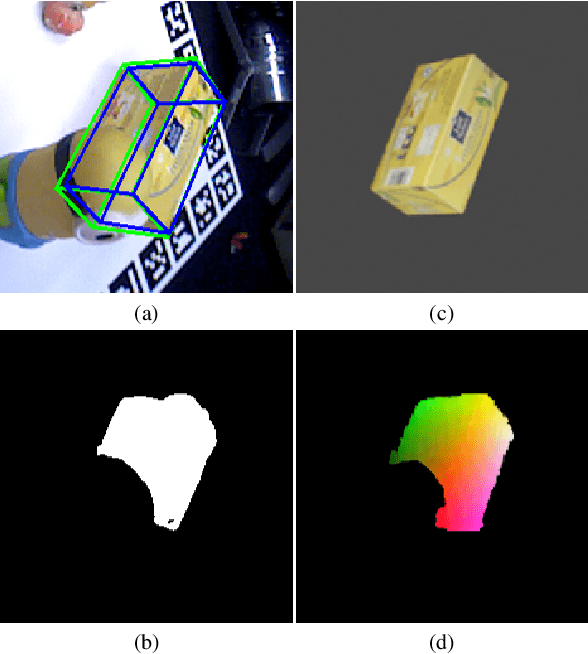
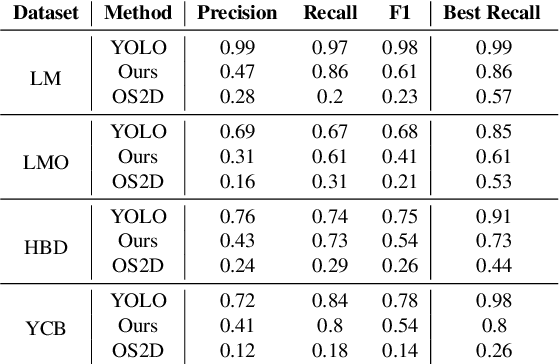
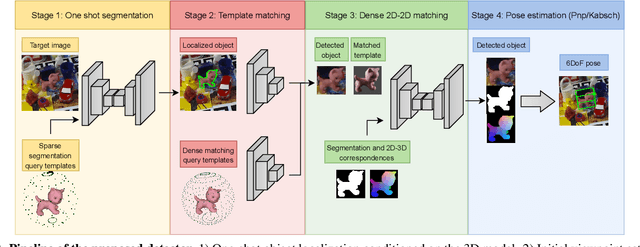
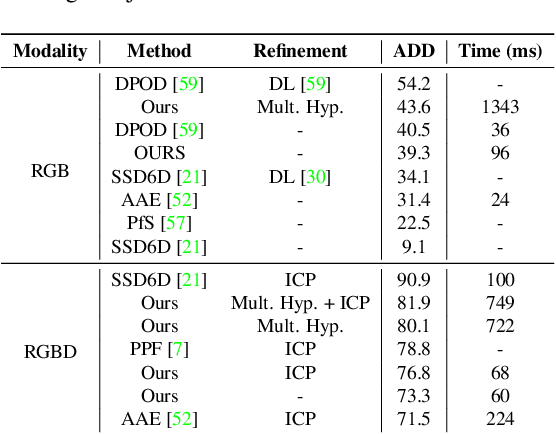
We present a novel one-shot method for object detection and 6 DoF pose estimation, that does not require training on target objects. At test time, it takes as input a target image and a textured 3D query model. The core idea is to represent a 3D model with a number of 2D templates rendered from different viewpoints. This enables CNN-based direct dense feature extraction and matching. The object is first localized in 2D, then its approximate viewpoint is estimated, followed by dense 2D-3D correspondence prediction. The final pose is computed with PnP. We evaluate the method on LineMOD, Occlusion, Homebrewed, YCB-V and TLESS datasets and report very competitive performance in comparison to the state-of-the-art methods trained on synthetic data, even though our method is not trained on the object models used for testing.
NeRF-Pose: A First-Reconstruct-Then-Regress Approach for Weakly-supervised 6D Object Pose Estimation
Mar 09, 2022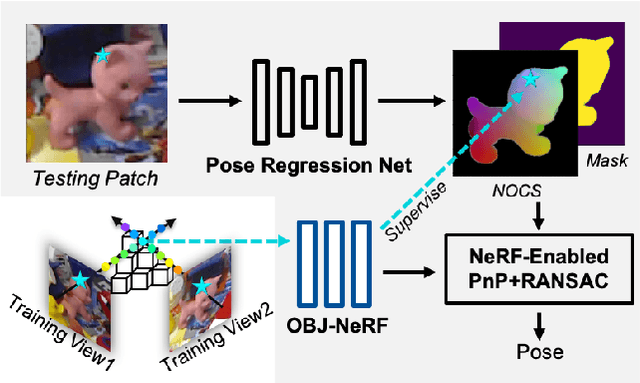
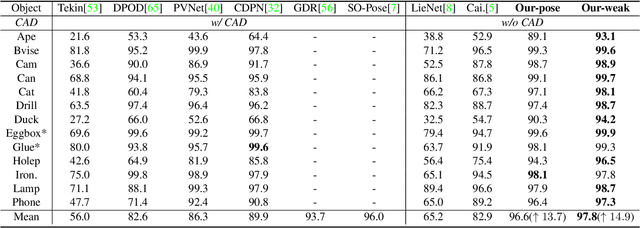
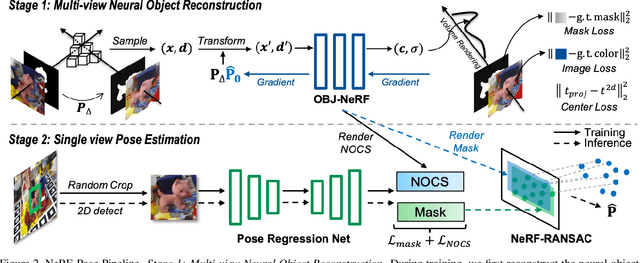
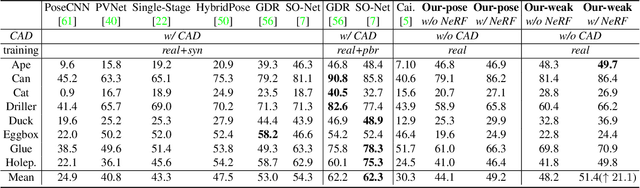
Pose estimation of 3D objects in monocular images is a fundamental and long-standing problem in computer vision. Existing deep learning approaches for 6D pose estimation typically rely on the assumption of availability of 3D object models and 6D pose annotations. However, precise annotation of 6D poses in real data is intricate, time-consuming and not scalable, while synthetic data scales well but lacks realism. To avoid these problems, we present a weakly-supervised reconstruction-based pipeline, named NeRF-Pose, which needs only 2D object segmentation and known relative camera poses during training. Following the first-reconstruct-then-regress idea, we first reconstruct the objects from multiple views in the form of an implicit neural representation. Then, we train a pose regression network to predict pixel-wise 2D-3D correspondences between images and the reconstructed model. At inference, the approach only needs a single image as input. A NeRF-enabled PnP+RANSAC algorithm is used to estimate stable and accurate pose from the predicted correspondences. Experiments on LineMod and LineMod-Occlusion show that the proposed method has state-of-the-art accuracy in comparison to the best 6D pose estimation methods in spite of being trained only with weak labels. Besides, we extend the Homebrewed DB dataset with more real training images to support the weakly supervised task and achieve compelling results on this dataset. The extended dataset and code will be released soon.
Adversarial Dual-Student with Differentiable Spatial Warping for Semi-Supervised Semantic Segmentation
Mar 05, 2022
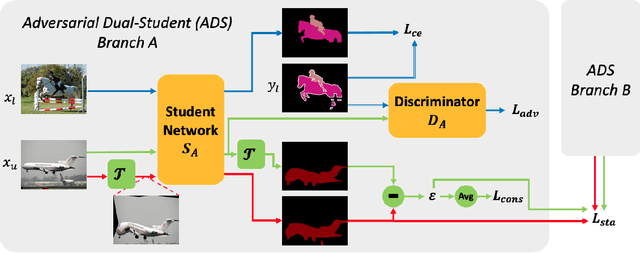
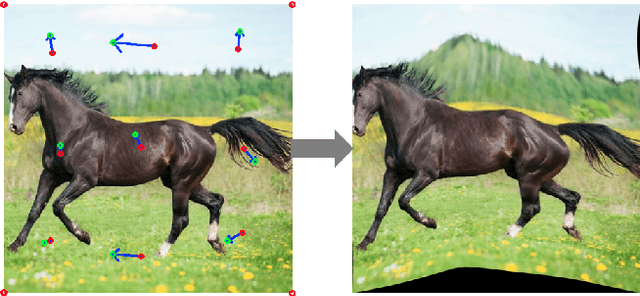

A common challenge posed to robust semantic segmentation is the expensive data annotation cost. Existing semi-supervised solutions show great potential toward solving this problem. Their key idea is constructing consistency regularization with unsupervised data augmentation from unlabeled data for model training. The perturbations for unlabeled data enable the consistency training loss, which benefits semi-supervised semantic segmentation. However, these perturbations destroy image context and introduce unnatural boundaries, which is harmful for semantic segmentation. Besides, the widely adopted semi-supervised learning framework, i.e. mean-teacher, suffers performance limitation since the student model finally converges to the teacher model. In this paper, first of all, we propose a context friendly differentiable geometric warping to conduct unsupervised data augmentation; secondly, a novel adversarial dual-student framework is proposed to improve the Mean-Teacher from the following two aspects: (1) dual student models are learnt independently except for a stabilization constraint to encourage exploiting model diversities; (2) adversarial training scheme is applied to both students and the discriminators are resorted to distinguish reliable pseudo-label of unlabeled data for self-training. Effectiveness is validated via extensive experiments on PASCAL VOC2012 and Citescapes. Our solution significantly improves the performance and state-of-the-art results are achieved on both datasets. Remarkably, compared with fully supervision, our solution achieves comparable mIoU of 73.4% using only 12.5% annotated data on PASCAL VOC2012.