 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCC-3DT: Panoramic 3D Object Tracking via Cross-Camera Fusion
Dec 02, 2022



To track the 3D locations and trajectories of the other traffic participants at any given time, modern autonomous vehicles are equipped with multiple cameras that cover the vehicle's full surroundings. Yet, camera-based 3D object tracking methods prioritize optimizing the single-camera setup and resort to post-hoc fusion in a multi-camera setup. In this paper, we propose a method for panoramic 3D object tracking, called CC-3DT, that associates and models object trajectories both temporally and across views, and improves the overall tracking consistency. In particular, our method fuses 3D detections from multiple cameras before association, reducing identity switches significantly and improving motion modeling. Our experiments on large-scale driving datasets show that fusion before association leads to a large margin of improvement over post-hoc fusion. We set a new state-of-the-art with 12.6% improvement in average multi-object tracking accuracy (AMOTA) among all camera-based methods on the competitive NuScenes 3D tracking benchmark, outperforming previously published methods by 6.5% in AMOTA with the same 3D detector.
3D Point Positional Encoding for Multi-Camera 3D Object Detection Transformers
Nov 27, 2022



Multi-camera 3D object detection, a critical component for vision-only driving systems, has achieved impressive progress. Notably, transformer-based methods with 2D features augmented by 3D positional encodings (PE) have enjoyed great success. However, the mechanism and options of 3D PE have not been thoroughly explored. In this paper, we first explore, analyze and compare various 3D positional encodings. In particular, we devise 3D point PE and show its superior performance since more precise positioning may lead to superior 3D detection. In practice, we utilize monocular depth estimation to obtain the 3D point positions for multi-camera 3D object detection. The PE with estimated 3D point locations can bring significant improvements compared to the commonly used camera-ray PE. Among DETR-based strategies, our method achieves state-of-the-art 45.6 mAP and 55.1 NDS on the competitive nuScenes valuation set. It's the first time that the performance gap between the vision-only (DETR-based) and LiDAR-based methods is reduced within 5\% mAP and 6\% NDS.
Unifying Flow, Stereo and Depth Estimation
Nov 10, 2022



We present a unified formulation and model for three motion and 3D perception tasks: optical flow, rectified stereo matching and unrectified stereo depth estimation from posed images. Unlike previous specialized architectures for each specific task, we formulate all three tasks as a unified dense correspondence matching problem, which can be solved with a single model by directly comparing feature similarities. Such a formulation calls for discriminative feature representations, which we achieve using a Transformer, in particular the cross-attention mechanism. We demonstrate that cross-attention enables integration of knowledge from another image via cross-view interactions, which greatly improves the quality of the extracted features. Our unified model naturally enables cross-task transfer since the model architecture and parameters are shared across tasks. We outperform RAFT with our unified model on the challenging Sintel dataset, and our final model that uses a few additional task-specific refinement steps outperforms or compares favorably to recent state-of-the-art methods on 10 popular flow, stereo and depth datasets, while being simpler and more efficient in terms of model design and inference speed.
Normalization Perturbation: A Simple Domain Generalization Method for Real-World Domain Shifts
Nov 09, 2022



Improving model's generalizability against domain shifts is crucial, especially for safety-critical applications such as autonomous driving. Real-world domain styles can vary substantially due to environment changes and sensor noises, but deep models only know the training domain style. Such domain style gap impedes model generalization on diverse real-world domains. Our proposed Normalization Perturbation (NP) can effectively overcome this domain style overfitting problem. We observe that this problem is mainly caused by the biased distribution of low-level features learned in shallow CNN layers. Thus, we propose to perturb the channel statistics of source domain features to synthesize various latent styles, so that the trained deep model can perceive diverse potential domains and generalizes well even without observations of target domain data in training. We further explore the style-sensitive channels for effective style synthesis. Normalization Perturbation only relies on a single source domain and is surprisingly effective and extremely easy to implement. Extensive experiments verify the effectiveness of our method for generalizing models under real-world domain shifts.
Learning Deep Sensorimotor Policies for Vision-based Autonomous Drone Racing
Oct 26, 2022



Autonomous drones can operate in remote and unstructured environments, enabling various real-world applications. However, the lack of effective vision-based algorithms has been a stumbling block to achieving this goal. Existing systems often require hand-engineered components for state estimation, planning, and control. Such a sequential design involves laborious tuning, human heuristics, and compounding delays and errors. This paper tackles the vision-based autonomous-drone-racing problem by learning deep sensorimotor policies. We use contrastive learning to extract robust feature representations from the input images and leverage a two-stage learning-by-cheating framework for training a neural network policy. The resulting policy directly infers control commands with feature representations learned from raw images, forgoing the need for globally-consistent state estimation, trajectory planning, and handcrafted control design. Our experimental results indicate that our vision-based policy can achieve the same level of racing performance as the state-based policy while being robust against different visual disturbances and distractors. We believe this work serves as a stepping-stone toward developing intelligent vision-based autonomous systems that control the drone purely from image inputs, like human pilots.
Composite Learning for Robust and Effective Dense Predictions
Oct 13, 2022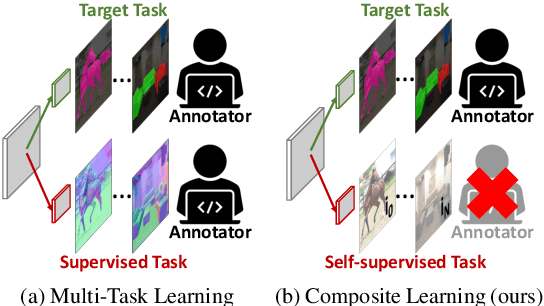
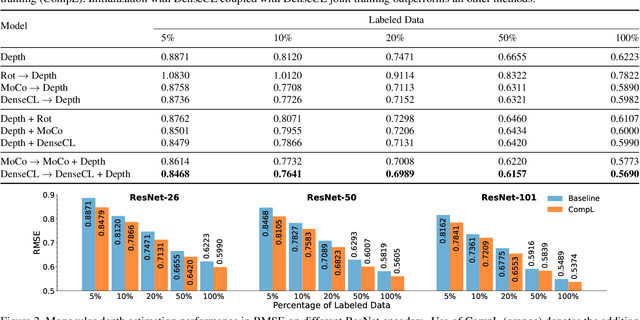
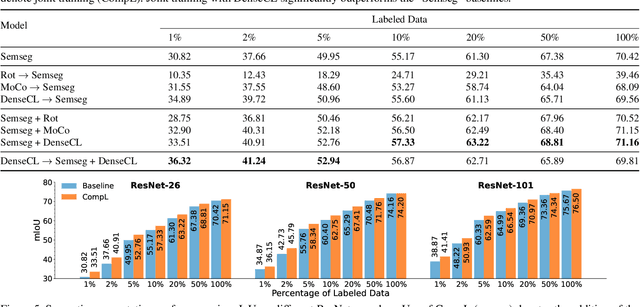
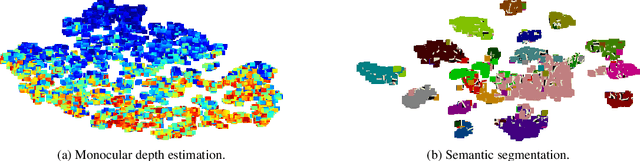
Multi-task learning promises better model generalization on a target task by jointly optimizing it with an auxiliary task. However, the current practice requires additional labeling efforts for the auxiliary task, while not guaranteeing better model performance. In this paper, we find that jointly training a dense prediction (target) task with a self-supervised (auxiliary) task can consistently improve the performance of the target task, while eliminating the need for labeling auxiliary tasks. We refer to this joint training as Composite Learning (CompL). Experiments of CompL on monocular depth estimation, semantic segmentation, and boundary detection show consistent performance improvements in fully and partially labeled datasets. Further analysis on depth estimation reveals that joint training with self-supervision outperforms most labeled auxiliary tasks. We also find that CompL can improve model robustness when the models are evaluated in new domains. These results demonstrate the benefits of self-supervision as an auxiliary task, and establish the design of novel task-specific self-supervised methods as a new axis of investigation for future multi-task learning research.
QDTrack: Quasi-Dense Similarity Learning for Appearance-Only Multiple Object Tracking
Oct 12, 2022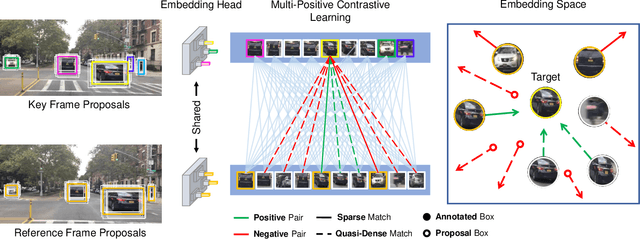
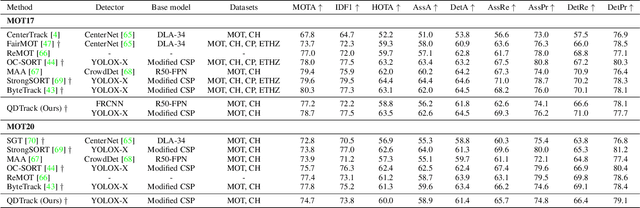
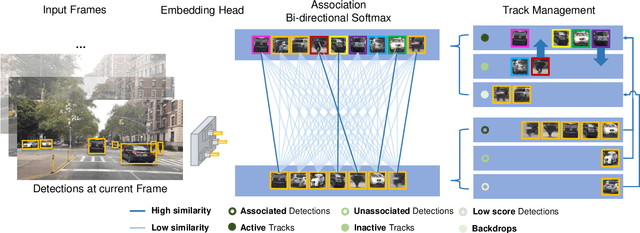
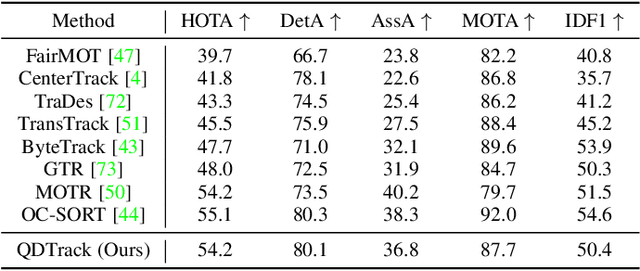
Similarity learning has been recognized as a crucial step for object tracking. However, existing multiple object tracking methods only use sparse ground truth matching as the training objective, while ignoring the majority of the informative regions in images. In this paper, we present Quasi-Dense Similarity Learning, which densely samples hundreds of object regions on a pair of images for contrastive learning. We combine this similarity learning with multiple existing object detectors to build Quasi-Dense Tracking (QDTrack), which does not require displacement regression or motion priors. We find that the resulting distinctive feature space admits a simple nearest neighbor search at inference time for object association. In addition, we show that our similarity learning scheme is not limited to video data, but can learn effective instance similarity even from static input, enabling a competitive tracking performance without training on videos or using tracking supervision. We conduct extensive experiments on a wide variety of popular MOT benchmarks. We find that, despite its simplicity, QDTrack rivals the performance of state-of-the-art tracking methods on all benchmarks and sets a new state-of-the-art on the large-scale BDD100K MOT benchmark, while introducing negligible computational overhead to the detector.
Fast Hierarchical Learning for Few-Shot Object Detection
Oct 10, 2022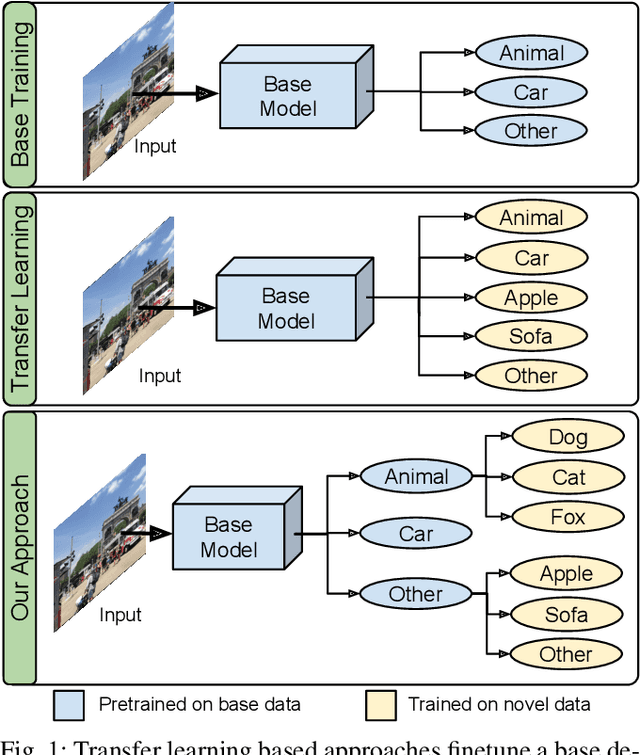
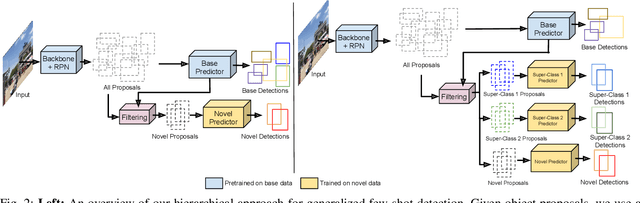
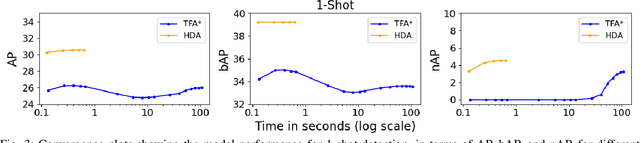

Transfer learning based approaches have recently achieved promising results on the few-shot detection task. These approaches however suffer from ``catastrophic forgetting'' issue due to finetuning of base detector, leading to sub-optimal performance on the base classes. Furthermore, the slow convergence rate of stochastic gradient descent (SGD) results in high latency and consequently restricts real-time applications. We tackle the aforementioned issues in this work. We pose few-shot detection as a hierarchical learning problem, where the novel classes are treated as the child classes of existing base classes and the background class. The detection heads for the novel classes are then trained using a specialized optimization strategy, leading to significantly lower training times compared to SGD. Our approach obtains competitive novel class performance on few-shot MS-COCO benchmark, while completely retaining the performance of the initial model on the base classes. We further demonstrate the application of our approach to a new class-refined few-shot detection task.
Uncertainty Guided Policy for Active Robotic 3D Reconstruction using Neural Radiance Fields
Sep 17, 2022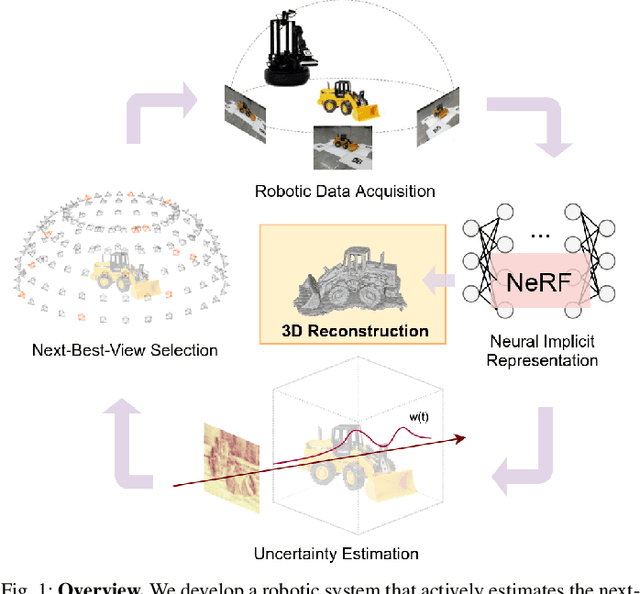
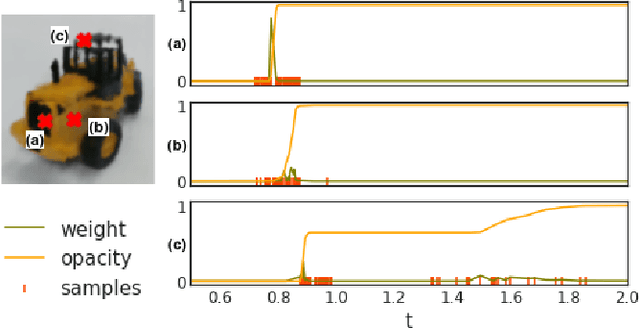

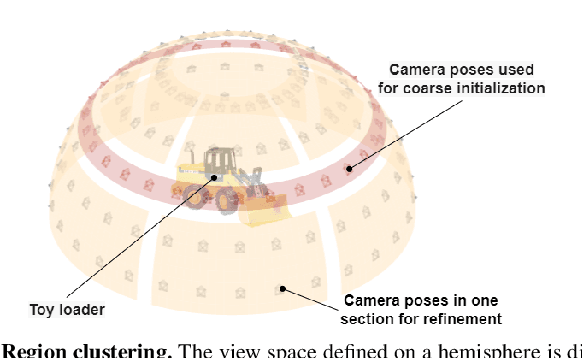
In this paper, we tackle the problem of active robotic 3D reconstruction of an object. In particular, we study how a mobile robot with an arm-held camera can select a favorable number of views to recover an object's 3D shape efficiently. Contrary to the existing solution to this problem, we leverage the popular neural radiance fields-based object representation, which has recently shown impressive results for various computer vision tasks. However, it is not straightforward to directly reason about an object's explicit 3D geometric details using such a representation, making the next-best-view selection problem for dense 3D reconstruction challenging. This paper introduces a ray-based volumetric uncertainty estimator, which computes the entropy of the weight distribution of the color samples along each ray of the object's implicit neural representation. We show that it is possible to infer the uncertainty of the underlying 3D geometry given a novel view with the proposed estimator. We then present a next-best-view selection policy guided by the ray-based volumetric uncertainty in neural radiance fields-based representations. Encouraging experimental results on synthetic and real-world data suggest that the approach presented in this paper can enable a new research direction of using an implicit 3D object representation for the next-best-view problem in robot vision applications, distinguishing our approach from the existing approaches that rely on explicit 3D geometric modeling.
Spatio-Temporal Action Detection Under Large Motion
Sep 06, 2022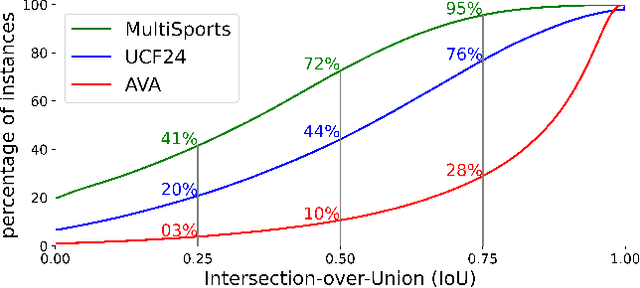
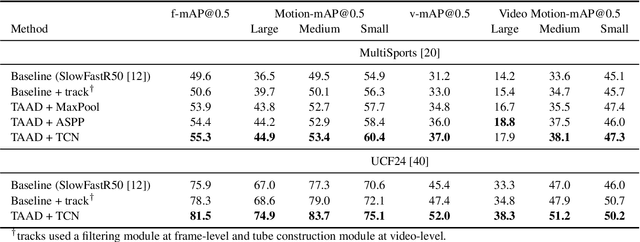

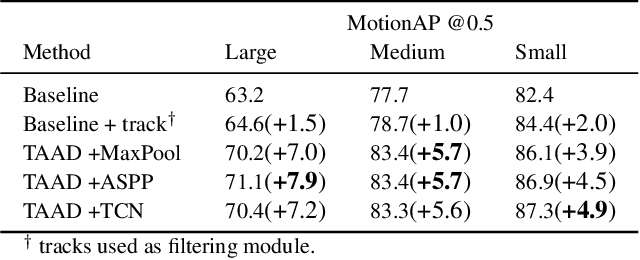
Current methods for spatiotemporal action tube detection often extend a bounding box proposal at a given keyframe into a 3D temporal cuboid and pool features from nearby frames. However, such pooling fails to accumulate meaningful spatiotemporal features if the position or shape of the actor shows large 2D motion and variability through the frames, due to large camera motion, large actor shape deformation, fast actor action and so on. In this work, we aim to study the performance of cuboid-aware feature aggregation in action detection under large action. Further, we propose to enhance actor feature representation under large motion by tracking actors and performing temporal feature aggregation along the respective tracks. We define the actor motion with intersection-over-union (IoU) between the boxes of action tubes/tracks at various fixed time scales. The action having a large motion would result in lower IoU over time, and slower actions would maintain higher IoU. We find that track-aware feature aggregation consistently achieves a large improvement in action detection performance, especially for actions under large motion compared to the cuboid-aware baseline. As a result, we also report state-of-the-art on the large-scale MultiSports dataset.