 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeROAD-Waymo: Action Awareness at Scale for Autonomous Driving
Nov 03, 2024



Autonomous Vehicle (AV) perception systems require more than simply seeing, via e.g., object detection or scene segmentation. They need a holistic understanding of what is happening within the scene for safe interaction with other road users. Few datasets exist for the purpose of developing and training algorithms to comprehend the actions of other road users. This paper presents ROAD-Waymo, an extensive dataset for the development and benchmarking of techniques for agent, action, location and event detection in road scenes, provided as a layer upon the (US) Waymo Open dataset. Considerably larger and more challenging than any existing dataset (and encompassing multiple cities), it comes with 198k annotated video frames, 54k agent tubes, 3.9M bounding boxes and a total of 12.4M labels. The integrity of the dataset has been confirmed and enhanced via a novel annotation pipeline designed for automatically identifying violations of requirements specifically designed for this dataset. As ROAD-Waymo is compatible with the original (UK) ROAD dataset, it provides the opportunity to tackle domain adaptation between real-world road scenarios in different countries within a novel benchmark: ROAD++.
Exploiting Instance-based Mixed Sampling via Auxiliary Source Domain Supervision for Domain-adaptive Action Detection
Oct 06, 2022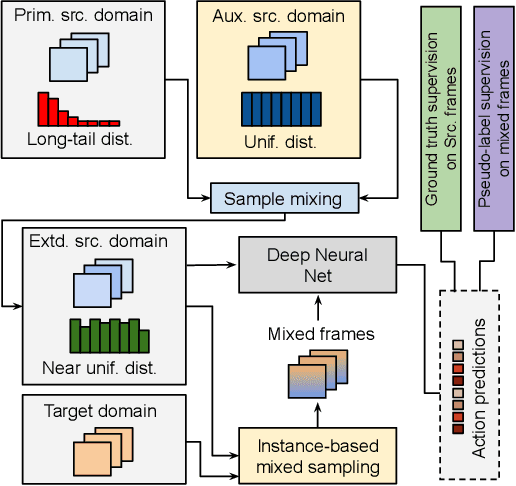
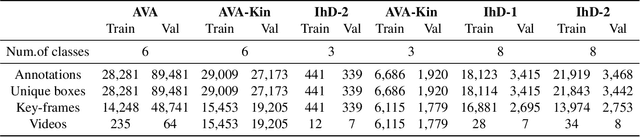
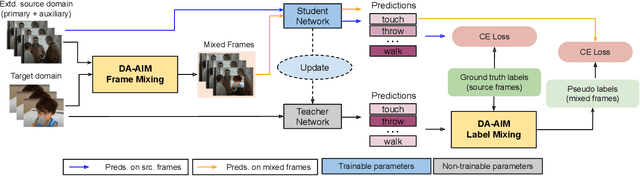
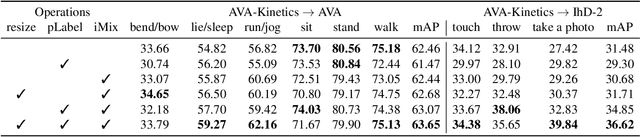
We propose a novel domain adaptive action detection approach and a new adaptation protocol that leverages the recent advancements in image-level unsupervised domain adaptation (UDA) techniques and handle vagaries of instance-level video data. Self-training combined with cross-domain mixed sampling has shown remarkable performance gain in semantic segmentation in UDA (unsupervised domain adaptation) context. Motivated by this fact, we propose an approach for human action detection in videos that transfers knowledge from the source domain (annotated dataset) to the target domain (unannotated dataset) using mixed sampling and pseudo-label-based selftraining. The existing UDA techniques follow a ClassMix algorithm for semantic segmentation. However, simply adopting ClassMix for action detection does not work, mainly because these are two entirely different problems, i.e., pixel-label classification vs. instance-label detection. To tackle this, we propose a novel action instance mixed sampling technique that combines information across domains based on action instances instead of action classes. Moreover, we propose a new UDA training protocol that addresses the long-tail sample distribution and domain shift problem by using supervision from an auxiliary source domain (ASD). For the ASD, we propose a new action detection dataset with dense frame-level annotations. We name our proposed framework as domain-adaptive action instance mixing (DA-AIM). We demonstrate that DA-AIM consistently outperforms prior works on challenging domain adaptation benchmarks. The source code is available at https://github.com/wwwfan628/DA-AIM.
Spatio-Temporal Action Detection Under Large Motion
Sep 06, 2022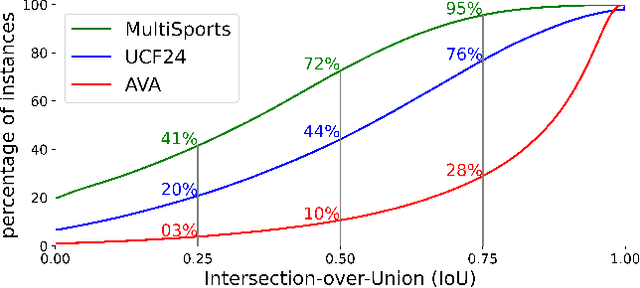
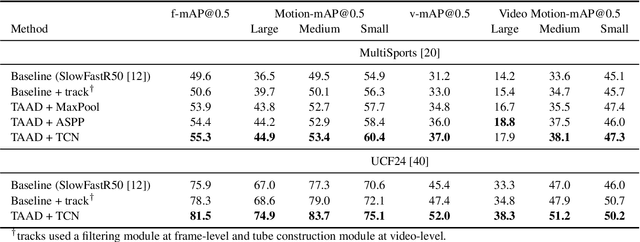

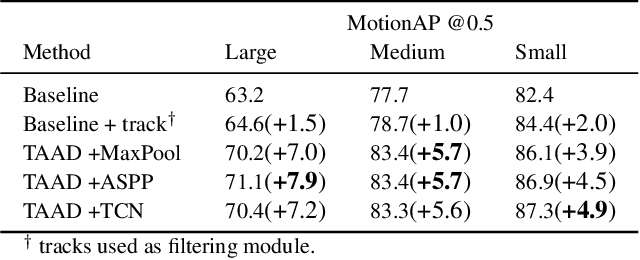
Current methods for spatiotemporal action tube detection often extend a bounding box proposal at a given keyframe into a 3D temporal cuboid and pool features from nearby frames. However, such pooling fails to accumulate meaningful spatiotemporal features if the position or shape of the actor shows large 2D motion and variability through the frames, due to large camera motion, large actor shape deformation, fast actor action and so on. In this work, we aim to study the performance of cuboid-aware feature aggregation in action detection under large action. Further, we propose to enhance actor feature representation under large motion by tracking actors and performing temporal feature aggregation along the respective tracks. We define the actor motion with intersection-over-union (IoU) between the boxes of action tubes/tracks at various fixed time scales. The action having a large motion would result in lower IoU over time, and slower actions would maintain higher IoU. We find that track-aware feature aggregation consistently achieves a large improvement in action detection performance, especially for actions under large motion compared to the cuboid-aware baseline. As a result, we also report state-of-the-art on the large-scale MultiSports dataset.
The SARAS Endoscopic Surgeon Action Detection (ESAD) dataset: Challenges and methods
Apr 07, 2021
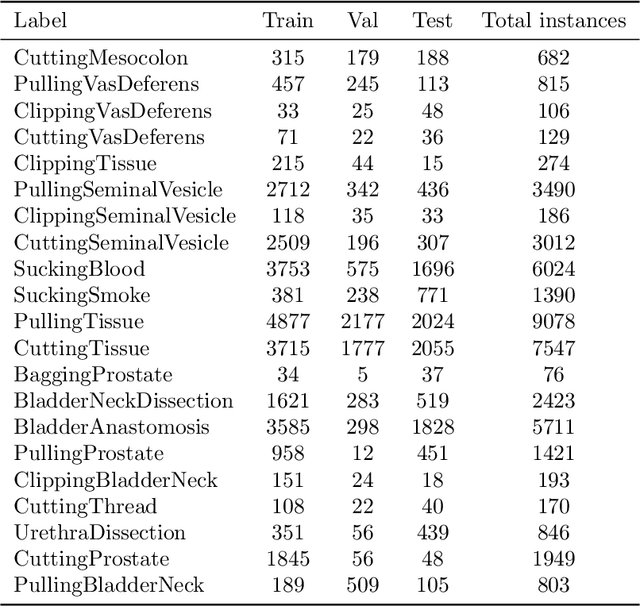
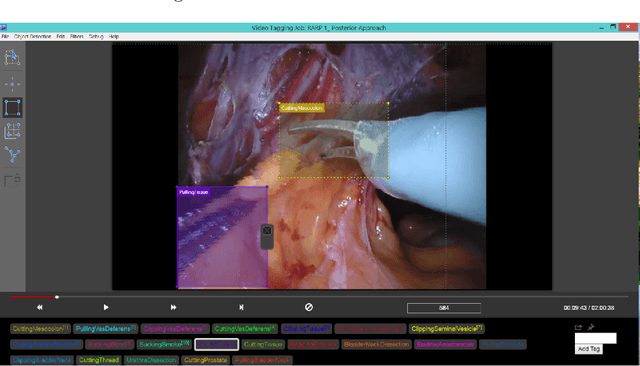
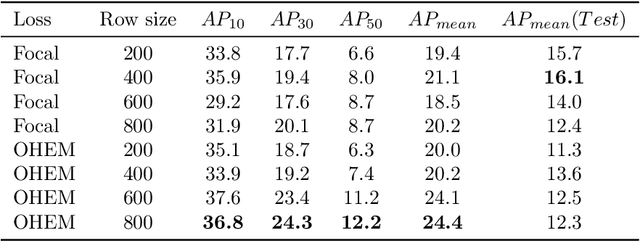
For an autonomous robotic system, monitoring surgeon actions and assisting the main surgeon during a procedure can be very challenging. The challenges come from the peculiar structure of the surgical scene, the greater similarity in appearance of actions performed via tools in a cavity compared to, say, human actions in unconstrained environments, as well as from the motion of the endoscopic camera. This paper presents ESAD, the first large-scale dataset designed to tackle the problem of surgeon action detection in endoscopic minimally invasive surgery. ESAD aims at contributing to increase the effectiveness and reliability of surgical assistant robots by realistically testing their awareness of the actions performed by a surgeon. The dataset provides bounding box annotation for 21 action classes on real endoscopic video frames captured during prostatectomy, and was used as the basis of a recent MIDL 2020 challenge. We also present an analysis of the dataset conducted using the baseline model which was released as part of the challenge, and a description of the top performing models submitted to the challenge together with the results they obtained. This study provides significant insight into what approaches can be effective and can be extended further. We believe that ESAD will serve in the future as a useful benchmark for all researchers active in surgeon action detection and assistive robotics at large.
ROAD: The ROad event Awareness Dataset for Autonomous Driving
Feb 25, 2021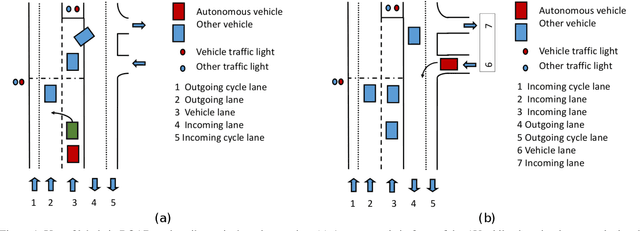

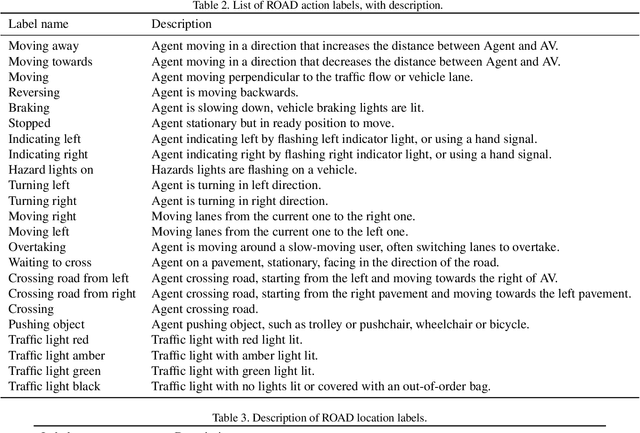

Humans approach driving in a holistic fashion which entails, in particular, understanding road events and their evolution. Injecting these capabilities in an autonomous vehicle has thus the potential to take situational awareness and decision making closer to human-level performance. To this purpose, we introduce the ROad event Awareness Dataset (ROAD) for Autonomous Driving, to our knowledge the first of its kind. ROAD is designed to test an autonomous vehicle's ability to detect road events, defined as triplets composed by a moving agent, the action(s) it performs and the corresponding scene locations. ROAD comprises 22 videos, originally from the Oxford RobotCar Dataset, annotated with bounding boxes showing the location in the image plane of each road event. We also provide as baseline a new incremental algorithm for online road event awareness, based on inflating RetinaNet along time, which achieves a mean average precision of 16.8% and 6.1% for frame-level and video-level event detection, respectively, at 50% overlap. Though promising, these figures highlight the challenges faced by situation awareness in autonomous driving. Finally, ROAD allows scholars to investigate exciting tasks such as complex (road) activity detection, future road event anticipation and the modelling of sentient road agents in terms of mental states. Dataset can be obtained from https://github.com/gurkirt/road-dataset and baseline code from https://github.com/gurkirt/3D-RetinaNet.
Online Spatiotemporal Action Detection and Prediction via Causal Representations
Aug 31, 2020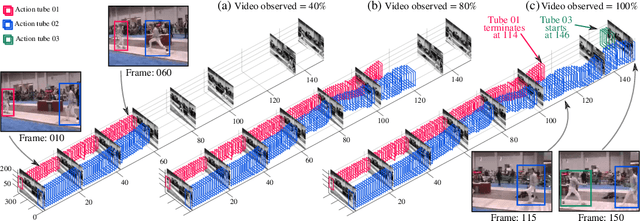
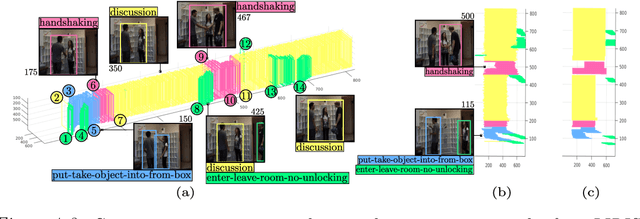
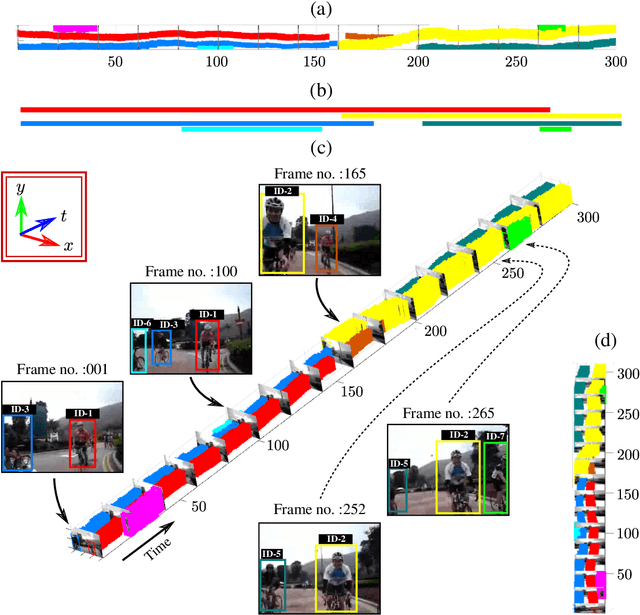

In this thesis, we focus on video action understanding problems from an online and real-time processing point of view. We start with the conversion of the traditional offline spatiotemporal action detection pipeline into an online spatiotemporal action tube detection system. An action tube is a set of bounding connected over time, which bounds an action instance in space and time. Next, we explore the future prediction capabilities of such detection methods by extending an existing action tube into the future by regression. Later, we seek to establish that online/causal representations can achieve similar performance to that of offline three dimensional (3D) convolutional neural networks (CNNs) on various tasks, including action recognition, temporal action segmentation and early prediction.
ESAD: Endoscopic Surgeon Action Detection Dataset
Jun 12, 2020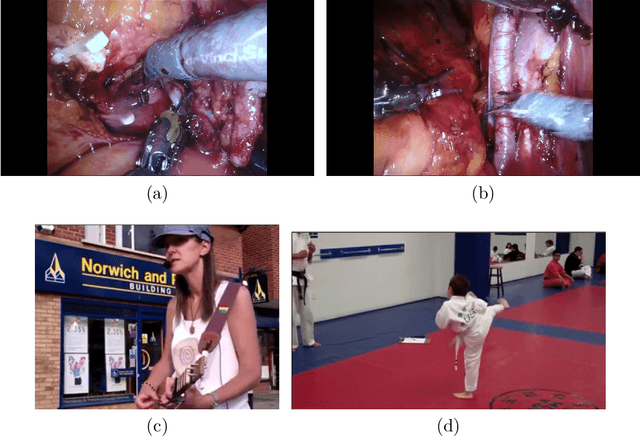
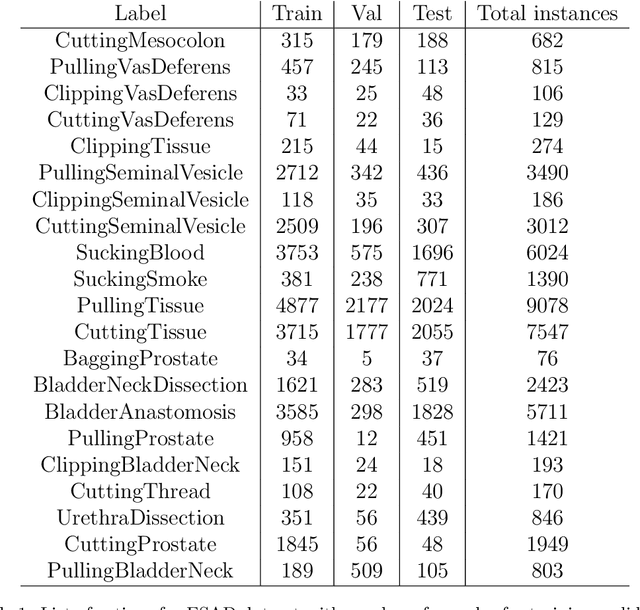
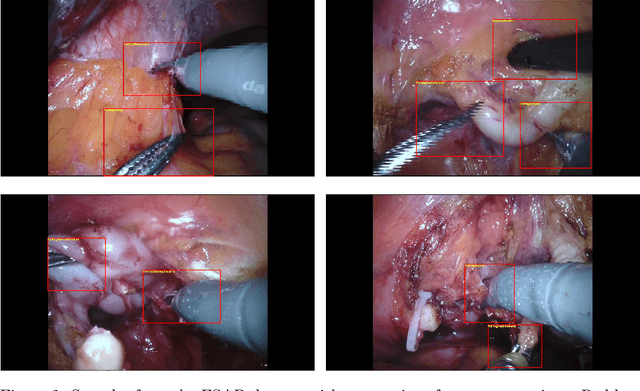
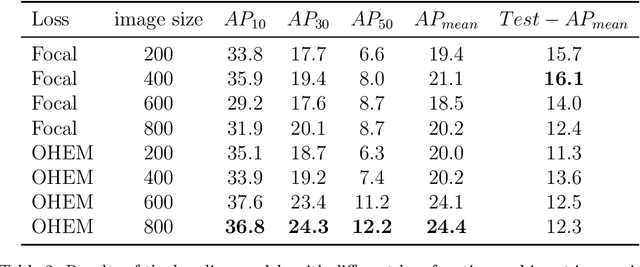
In this work, we take aim towards increasing the effectiveness of surgical assistant robots. We intended to make assistant robots safer by making them aware about the actions of surgeon, so it can take appropriate assisting actions. In other words, we aim to solve the problem of surgeon action detection in endoscopic videos. To this, we introduce a challenging dataset for surgeon action detection in real-world endoscopic videos. Action classes are picked based on the feedback of surgeons and annotated by medical professional. Given a video frame, we draw bounding box around surgical tool which is performing action and label it with action label. Finally, we presenta frame-level action detection baseline model based on recent advances in ob-ject detection. Results on our new dataset show that our presented dataset provides enough interesting challenges for future method and it can serveas strong benchmark corresponding research in surgeon action detection in endoscopic videos.
Two-Stream AMTnet for Action Detection
Apr 03, 2020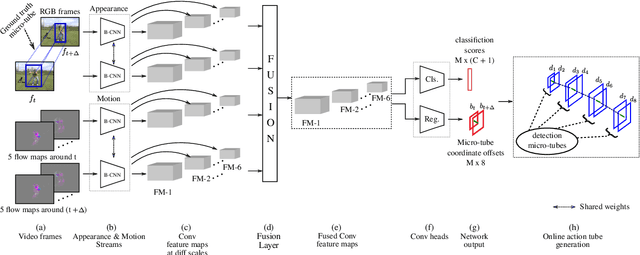
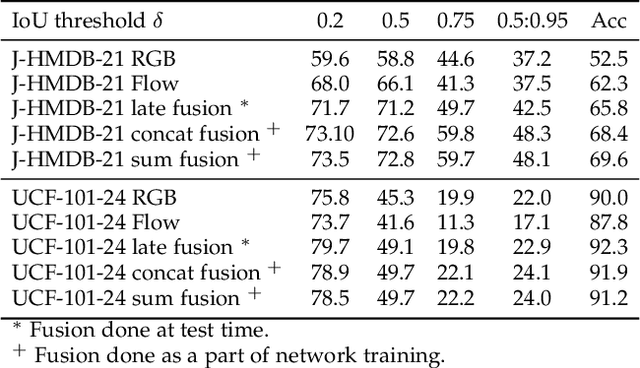
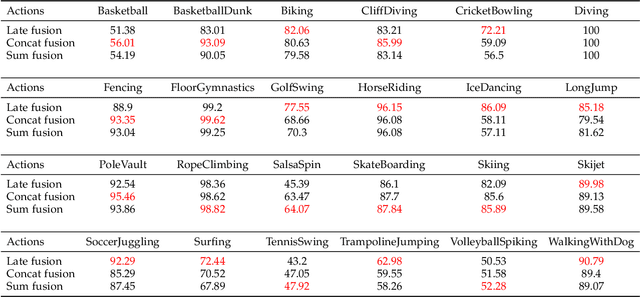
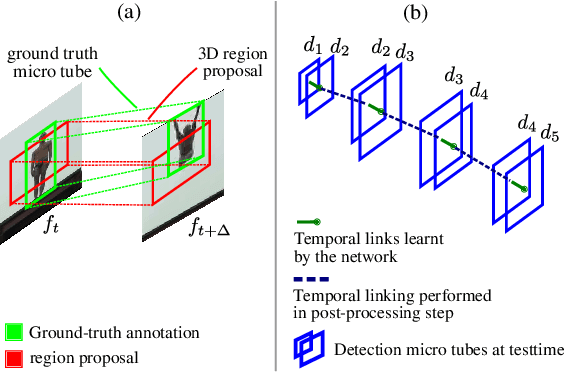
In this paper, we propose Two-Stream AMTnet, which leverages recent advances in video-based action representation[1] and incremental action tube generation[2]. Majority of the present action detectors follow a frame-based representation, a late-fusion followed by an offline action tube building steps. These are sub-optimal as: frame-based features barely encode the temporal relations; late-fusion restricts the network to learn robust spatiotemporal features; and finally, an offline action tube generation is not suitable for many real-world problems such as autonomous driving, human-robot interaction to name a few. The key contributions of this work are: (1) combining AMTnet's 3D proposal architecture with an online action tube generation technique which allows the model to learn stronger temporal features needed for accurate action detection and facilitates running inference online; (2) an efficient fusion technique allowing the deep network to learn strong spatiotemporal action representations. This is achieved by augmenting the previous Action Micro-Tube (AMTnet) action detection framework in three distinct ways: by adding a parallel motion stIn this paper, we propose a new deep neural network architecture for online action detection, termed ream to the original appearance one in AMTnet; (2) in opposition to state-of-the-art action detectors which train appearance and motion streams separately, and use a test time late fusion scheme to fuse RGB and flow cues, by jointly training both streams in an end-to-end fashion and merging RGB and optical flow features at training time; (3) by introducing an online action tube generation algorithm which works at video-level, and in real-time (when exploiting only appearance features). Two-Stream AMTnet exhibits superior action detection performance over state-of-the-art approaches on the standard action detection benchmarks.
An End-to-End Baseline for Video Captioning
Apr 04, 2019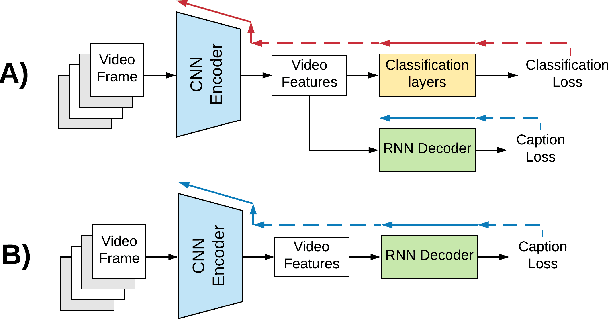
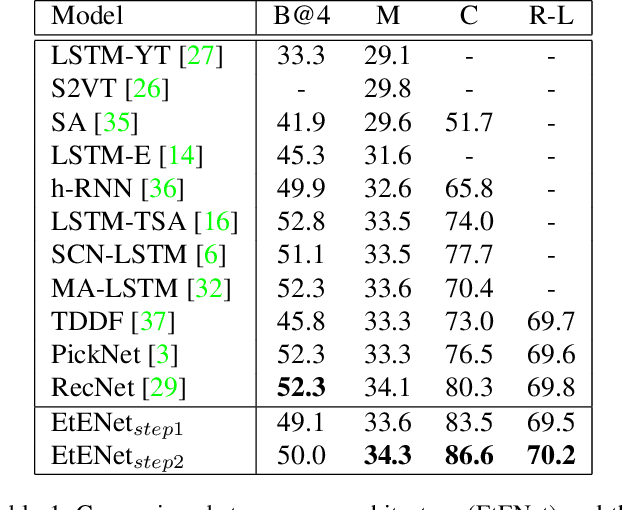
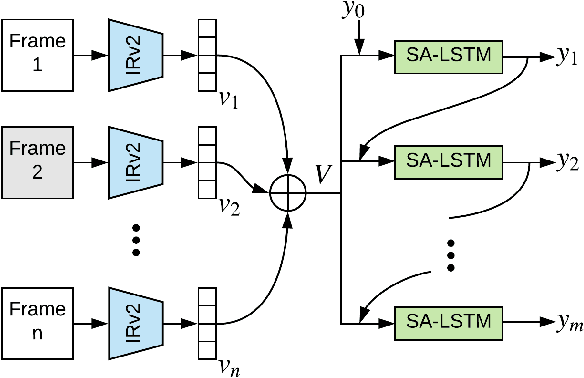
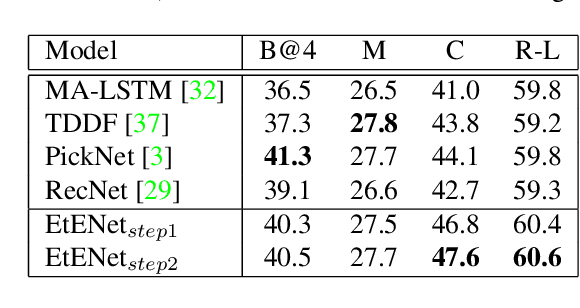
Building correspondences across different modalities, such as video and language, has recently become critical in many visual recognition applications, such as video captioning. Inspired by machine translation, recent models tackle this task using an encoder-decoder strategy. The (video) encoder is traditionally a Convolutional Neural Network (CNN), while the decoding (for language generation) is done using a Recurrent Neural Network (RNN). Current state-of-the-art methods, however, train encoder and decoder separately. CNNs are pretrained on object and/or action recognition tasks and used to encode video-level features. The decoder is then optimised on such static features to generate the video's description. This disjoint setup is arguably sub-optimal for input (video) to output (description) mapping. In this work, we propose to optimise both encoder and decoder simultaneously in an end-to-end fashion. In a two-stage training setting, we first initialise our architecture using pre-trained encoders and decoders -- then, the entire network is trained end-to-end in a fine-tuning stage to learn the most relevant features for video caption generation. In our experiments, we use GoogLeNet and Inception-ResNet-v2 as encoders and an original Soft-Attention (SA-) LSTM as a decoder. Analogously to gains observed in other computer vision problems, we show that end-to-end training significantly improves over the traditional, disjoint training process. We evaluate our End-to-End (EtENet) Networks on the Microsoft Research Video Description (MSVD) and the MSR Video to Text (MSR-VTT) benchmark datasets, showing how EtENet achieves state-of-the-art performance across the board.
Recurrence to the Rescue: Towards Causal Spatiotemporal Representations
Nov 17, 2018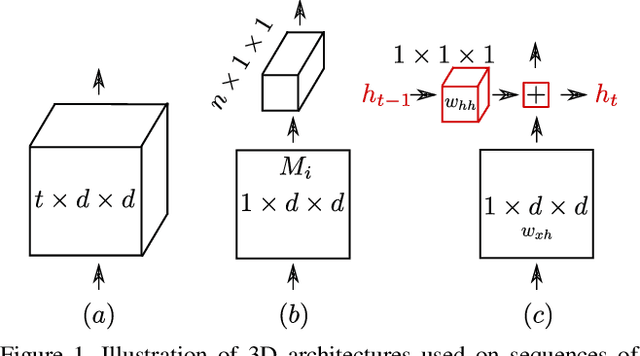
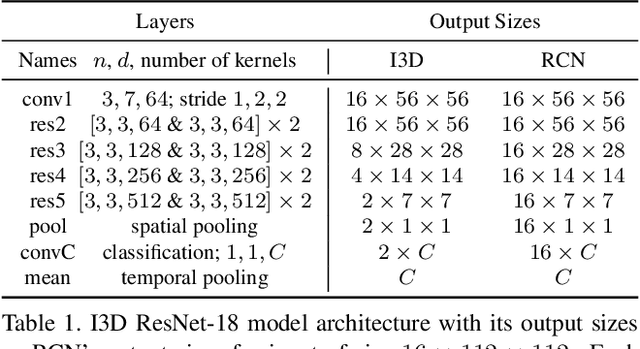
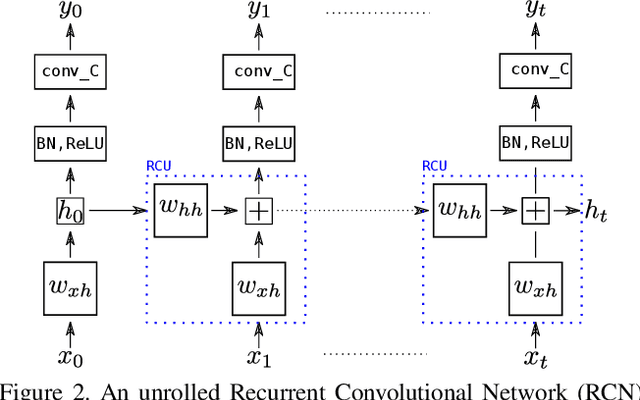
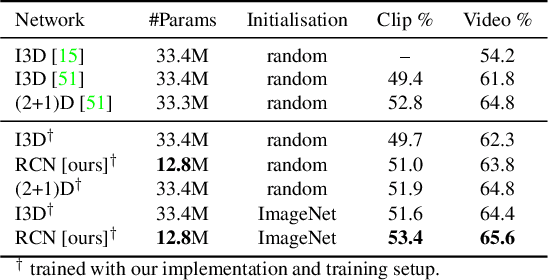
Recently, three dimensional (3D) convolutional neural networks (CNNs) have emerged as dominant methods to capture spatiotemporal representations, by adding to pre-existing 2D CNNs a third, temporal dimension. Such 3D CNNs, however, are anti-causal (i.e., they exploit information from both the past and the future to produce feature representations, thus preventing their use in online settings), constrain the temporal reasoning horizon to the size of the temporal convolution kernel, and are not temporal resolution-preserving for video sequence-to-sequence modelling, as, e.g., in spatiotemporal action detection. To address these serious limitations, we present a new architecture for the causal/online spatiotemporal representation of videos. Namely, we propose a recurrent convolutional network (RCN), which relies on recurrence to capture the temporal context across frames at every level of network depth. Our network decomposes 3D convolutions into (1) a 2D spatial convolution component, and (2) an additional hidden state $1\times 1$ convolution applied across time. The hidden state at any time $t$ is assumed to depend on the hidden state at $t-1$ and on the current output of the spatial convolution component. As a result, the proposed network: (i) provides flexible temporal reasoning, (ii) produces causal outputs, and (iii) preserves temporal resolution. Our experiments on the large-scale large "Kinetics" dataset show that the proposed method achieves superior performance compared to 3D CNNs, while being causal and using fewer parameters.