 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeR3D3: Dense 3D Reconstruction of Dynamic Scenes from Multiple Cameras
Aug 28, 2023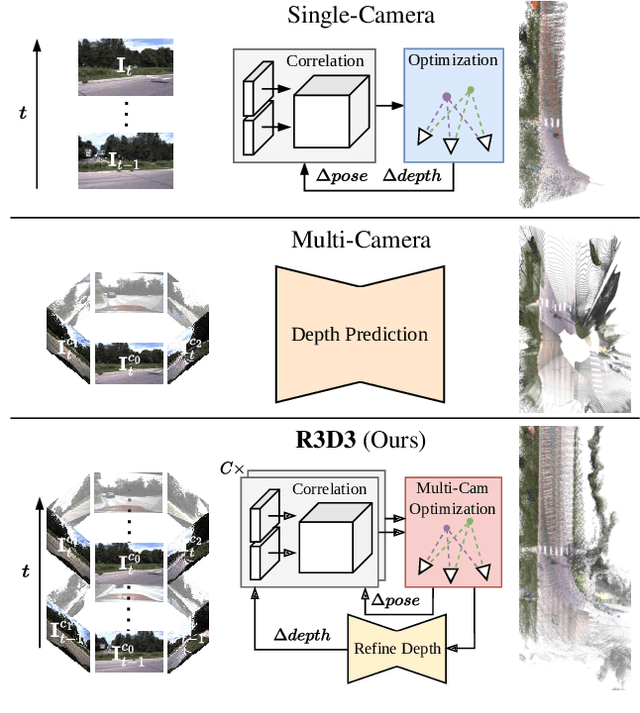

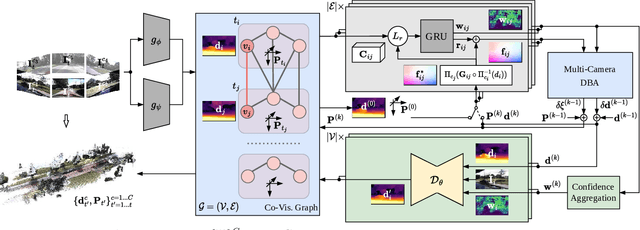
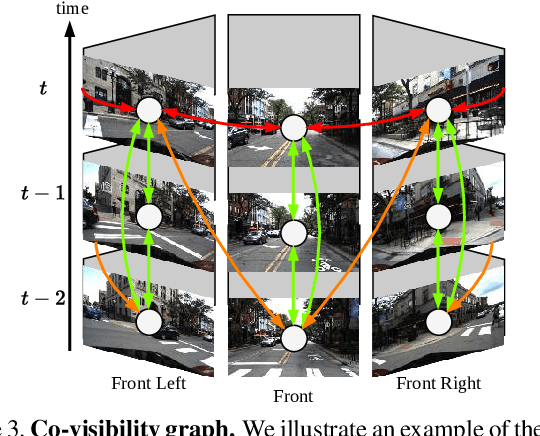
Dense 3D reconstruction and ego-motion estimation are key challenges in autonomous driving and robotics. Compared to the complex, multi-modal systems deployed today, multi-camera systems provide a simpler, low-cost alternative. However, camera-based 3D reconstruction of complex dynamic scenes has proven extremely difficult, as existing solutions often produce incomplete or incoherent results. We propose R3D3, a multi-camera system for dense 3D reconstruction and ego-motion estimation. Our approach iterates between geometric estimation that exploits spatial-temporal information from multiple cameras, and monocular depth refinement. We integrate multi-camera feature correlation and dense bundle adjustment operators that yield robust geometric depth and pose estimates. To improve reconstruction where geometric depth is unreliable, e.g. for moving objects or low-textured regions, we introduce learnable scene priors via a depth refinement network. We show that this design enables a dense, consistent 3D reconstruction of challenging, dynamic outdoor environments. Consequently, we achieve state-of-the-art dense depth prediction on the DDAD and NuScenes benchmarks.
MolGrapher: Graph-based Visual Recognition of Chemical Structures
Aug 23, 2023



The automatic analysis of chemical literature has immense potential to accelerate the discovery of new materials and drugs. Much of the critical information in patent documents and scientific articles is contained in figures, depicting the molecule structures. However, automatically parsing the exact chemical structure is a formidable challenge, due to the amount of detailed information, the diversity of drawing styles, and the need for training data. In this work, we introduce MolGrapher to recognize chemical structures visually. First, a deep keypoint detector detects the atoms. Second, we treat all candidate atoms and bonds as nodes and put them in a graph. This construct allows a natural graph representation of the molecule. Last, we classify atom and bond nodes in the graph with a Graph Neural Network. To address the lack of real training data, we propose a synthetic data generation pipeline producing diverse and realistic results. In addition, we introduce a large-scale benchmark of annotated real molecule images, USPTO-30K, to spur research on this critical topic. Extensive experiments on five datasets show that our approach significantly outperforms classical and learning-based methods in most settings. Code, models, and datasets are available.
Video OWL-ViT: Temporally-consistent open-world localization in video
Aug 22, 2023We present an architecture and a training recipe that adapts pre-trained open-world image models to localization in videos. Understanding the open visual world (without being constrained by fixed label spaces) is crucial for many real-world vision tasks. Contrastive pre-training on large image-text datasets has recently led to significant improvements for image-level tasks. For more structured tasks involving object localization applying pre-trained models is more challenging. This is particularly true for video tasks, where task-specific data is limited. We show successful transfer of open-world models by building on the OWL-ViT open-vocabulary detection model and adapting it to video by adding a transformer decoder. The decoder propagates object representations recurrently through time by using the output tokens for one frame as the object queries for the next. Our model is end-to-end trainable on video data and enjoys improved temporal consistency compared to tracking-by-detection baselines, while retaining the open-world capabilities of the backbone detector. We evaluate our model on the challenging TAO-OW benchmark and demonstrate that open-world capabilities, learned from large-scale image-text pre-training, can be transferred successfully to open-world localization across diverse videos.
Dual Aggregation Transformer for Image Super-Resolution
Aug 11, 2023



Transformer has recently gained considerable popularity in low-level vision tasks, including image super-resolution (SR). These networks utilize self-attention along different dimensions, spatial or channel, and achieve impressive performance. This inspires us to combine the two dimensions in Transformer for a more powerful representation capability. Based on the above idea, we propose a novel Transformer model, Dual Aggregation Transformer (DAT), for image SR. Our DAT aggregates features across spatial and channel dimensions, in the inter-block and intra-block dual manner. Specifically, we alternately apply spatial and channel self-attention in consecutive Transformer blocks. The alternate strategy enables DAT to capture the global context and realize inter-block feature aggregation. Furthermore, we propose the adaptive interaction module (AIM) and the spatial-gate feed-forward network (SGFN) to achieve intra-block feature aggregation. AIM complements two self-attention mechanisms from corresponding dimensions. Meanwhile, SGFN introduces additional non-linear spatial information in the feed-forward network. Extensive experiments show that our DAT surpasses current methods. Code and models are obtainable at https://github.com/zhengchen1999/DAT.
Strategic Preys Make Acute Predators: Enhancing Camouflaged Object Detectors by Generating Camouflaged Objects
Aug 06, 2023



Camouflaged object detection (COD) is the challenging task of identifying camouflaged objects visually blended into surroundings. Albeit achieving remarkable success, existing COD detectors still struggle to obtain precise results in some challenging cases. To handle this problem, we draw inspiration from the prey-vs-predator game that leads preys to develop better camouflage and predators to acquire more acute vision systems and develop algorithms from both the prey side and the predator side. On the prey side, we propose an adversarial training framework, Camouflageator, which introduces an auxiliary generator to generate more camouflaged objects that are harder for a COD method to detect. Camouflageator trains the generator and detector in an adversarial way such that the enhanced auxiliary generator helps produce a stronger detector. On the predator side, we introduce a novel COD method, called Internal Coherence and Edge Guidance (ICEG), which introduces a camouflaged feature coherence module to excavate the internal coherence of camouflaged objects, striving to obtain more complete segmentation results. Additionally, ICEG proposes a novel edge-guided separated calibration module to remove false predictions to avoid obtaining ambiguous boundaries. Extensive experiments show that ICEG outperforms existing COD detectors and Camouflageator is flexible to improve various COD detectors, including ICEG, which brings state-of-the-art COD performance.
Cascade-DETR: Delving into High-Quality Universal Object Detection
Jul 20, 2023Object localization in general environments is a fundamental part of vision systems. While dominating on the COCO benchmark, recent Transformer-based detection methods are not competitive in diverse domains. Moreover, these methods still struggle to very accurately estimate the object bounding boxes in complex environments. We introduce Cascade-DETR for high-quality universal object detection. We jointly tackle the generalization to diverse domains and localization accuracy by proposing the Cascade Attention layer, which explicitly integrates object-centric information into the detection decoder by limiting the attention to the previous box prediction. To further enhance accuracy, we also revisit the scoring of queries. Instead of relying on classification scores, we predict the expected IoU of the query, leading to substantially more well-calibrated confidences. Lastly, we introduce a universal object detection benchmark, UDB10, that contains 10 datasets from diverse domains. While also advancing the state-of-the-art on COCO, Cascade-DETR substantially improves DETR-based detectors on all datasets in UDB10, even by over 10 mAP in some cases. The improvements under stringent quality requirements are even more pronounced. Our code and models will be released at https://github.com/SysCV/cascade-detr.
Segment Anything Meets Point Tracking
Jul 03, 2023



The Segment Anything Model (SAM) has established itself as a powerful zero-shot image segmentation model, employing interactive prompts such as points to generate masks. This paper presents SAM-PT, a method extending SAM's capability to tracking and segmenting anything in dynamic videos. SAM-PT leverages robust and sparse point selection and propagation techniques for mask generation, demonstrating that a SAM-based segmentation tracker can yield strong zero-shot performance across popular video object segmentation benchmarks, including DAVIS, YouTube-VOS, and MOSE. Compared to traditional object-centric mask propagation strategies, we uniquely use point propagation to exploit local structure information that is agnostic to object semantics. We highlight the merits of point-based tracking through direct evaluation on the zero-shot open-world Unidentified Video Objects (UVO) benchmark. To further enhance our approach, we utilize K-Medoids clustering for point initialization and track both positive and negative points to clearly distinguish the target object. We also employ multiple mask decoding passes for mask refinement and devise a point re-initialization strategy to improve tracking accuracy. Our code integrates different point trackers and video segmentation benchmarks and will be released at https://github.com/SysCV/sam-pt.
SSCBench: A Large-Scale 3D Semantic Scene Completion Benchmark for Autonomous Driving
Jun 15, 2023



Semantic scene completion (SSC) is crucial for holistic 3D scene understanding by jointly estimating semantics and geometry from sparse observations. However, progress in SSC, particularly in autonomous driving scenarios, is hindered by the scarcity of high-quality datasets. To overcome this challenge, we introduce SSCBench, a comprehensive benchmark that integrates scenes from widely-used automotive datasets (e.g., KITTI-360, nuScenes, and Waymo). SSCBench follows an established setup and format in the community, facilitating the easy exploration of the camera- and LiDAR-based SSC across various real-world scenarios. We present quantitative and qualitative evaluations of state-of-the-art algorithms on SSCBench and commit to continuously incorporating novel automotive datasets and SSC algorithms to drive further advancements in this field. Our resources are released on https://github.com/ai4ce/SSCBench.
Segment Anything in High Quality
Jun 02, 2023



The recent Segment Anything Model (SAM) represents a big leap in scaling up segmentation models, allowing for powerful zero-shot capabilities and flexible prompting. Despite being trained with 1.1 billion masks, SAM's mask prediction quality falls short in many cases, particularly when dealing with objects that have intricate structures. We propose HQ-SAM, equipping SAM with the ability to accurately segment any object, while maintaining SAM's original promptable design, efficiency, and zero-shot generalizability. Our careful design reuses and preserves the pre-trained model weights of SAM, while only introducing minimal additional parameters and computation. We design a learnable High-Quality Output Token, which is injected into SAM's mask decoder and is responsible for predicting the high-quality mask. Instead of only applying it on mask-decoder features, we first fuse them with early and final ViT features for improved mask details. To train our introduced learnable parameters, we compose a dataset of 44K fine-grained masks from several sources. HQ-SAM is only trained on the introduced detaset of 44k masks, which takes only 4 hours on 8 GPUs. We show the efficacy of HQ-SAM in a suite of 9 diverse segmentation datasets across different downstream tasks, where 7 out of them are evaluated in a zero-shot transfer protocol. Our code and models will be released at https://github.com/SysCV/SAM-HQ.
Condition-Invariant Semantic Segmentation
May 27, 2023



Adaptation of semantic segmentation networks to different visual conditions from those for which ground-truth annotations are available at training is vital for robust perception in autonomous cars and robots. However, previous work has shown that most feature-level adaptation methods, which employ adversarial training and are validated on synthetic-to-real adaptation, provide marginal gains in normal-to-adverse condition-level adaptation, being outperformed by simple pixel-level adaptation via stylization. Motivated by these findings, we propose to leverage stylization in performing feature-level adaptation by aligning the deep features extracted by the encoder of the network from the original and the stylized view of each input image with a novel feature invariance loss. In this way, we encourage the encoder to extract features that are invariant to the style of the input, allowing the decoder to focus on parsing these features and not on further abstracting from the specific style of the input. We implement our method, named Condition-Invariant Semantic Segmentation (CISS), on the top-performing domain adaptation architecture and demonstrate a significant improvement over previous state-of-the-art methods both on Cityscapes$\to$ACDC and Cityscapes$\to$Dark Zurich adaptation. In particular, CISS is ranked first among all published unsupervised domain adaptation methods on the public ACDC leaderboard. Our method is also shown to generalize well to domains unseen during training, outperforming competing domain adaptation approaches on BDD100K-night and Nighttime Driving. Code is publicly available at https://github.com/SysCV/CISS .