 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeedance 1.5 pro: A Native Audio-Visual Joint Generation Foundation Model
Dec 23, 2025Recent strides in video generation have paved the way for unified audio-visual generation. In this work, we present Seedance 1.5 pro, a foundational model engineered specifically for native, joint audio-video generation. Leveraging a dual-branch Diffusion Transformer architecture, the model integrates a cross-modal joint module with a specialized multi-stage data pipeline, achieving exceptional audio-visual synchronization and superior generation quality. To ensure practical utility, we implement meticulous post-training optimizations, including Supervised Fine-Tuning (SFT) on high-quality datasets and Reinforcement Learning from Human Feedback (RLHF) with multi-dimensional reward models. Furthermore, we introduce an acceleration framework that boosts inference speed by over 10X. Seedance 1.5 pro distinguishes itself through precise multilingual and dialect lip-syncing, dynamic cinematic camera control, and enhanced narrative coherence, positioning it as a robust engine for professional-grade content creation. Seedance 1.5 pro is now accessible on Volcano Engine at https://console.volcengine.com/ark/region:ark+cn-beijing/experience/vision?type=GenVideo.
VINCIE: Unlocking In-context Image Editing from Video
Jun 12, 2025In-context image editing aims to modify images based on a contextual sequence comprising text and previously generated images. Existing methods typically depend on task-specific pipelines and expert models (e.g., segmentation and inpainting) to curate training data. In this work, we explore whether an in-context image editing model can be learned directly from videos. We introduce a scalable approach to annotate videos as interleaved multimodal sequences. To effectively learn from this data, we design a block-causal diffusion transformer trained on three proxy tasks: next-image prediction, current segmentation prediction, and next-segmentation prediction. Additionally, we propose a novel multi-turn image editing benchmark to advance research in this area. Extensive experiments demonstrate that our model exhibits strong in-context image editing capabilities and achieves state-of-the-art results on two multi-turn image editing benchmarks. Despite being trained exclusively on videos, our model also shows promising abilities in multi-concept composition, story generation, and chain-of-editing applications.
Seaweed-7B: Cost-Effective Training of Video Generation Foundation Model
Apr 11, 2025



This technical report presents a cost-efficient strategy for training a video generation foundation model. We present a mid-sized research model with approximately 7 billion parameters (7B) called Seaweed-7B trained from scratch using 665,000 H100 GPU hours. Despite being trained with moderate computational resources, Seaweed-7B demonstrates highly competitive performance compared to contemporary video generation models of much larger size. Design choices are especially crucial in a resource-constrained setting. This technical report highlights the key design decisions that enhance the performance of the medium-sized diffusion model. Empirically, we make two observations: (1) Seaweed-7B achieves performance comparable to, or even surpasses, larger models trained on substantially greater GPU resources, and (2) our model, which exhibits strong generalization ability, can be effectively adapted across a wide range of downstream applications either by lightweight fine-tuning or continue training. See the project page at https://seaweed.video/
Synthetic Video Enhances Physical Fidelity in Video Synthesis
Mar 26, 2025We investigate how to enhance the physical fidelity of video generation models by leveraging synthetic videos derived from computer graphics pipelines. These rendered videos respect real-world physics, such as maintaining 3D consistency, and serve as a valuable resource that can potentially improve video generation models. To harness this potential, we propose a solution that curates and integrates synthetic data while introducing a method to transfer its physical realism to the model, significantly reducing unwanted artifacts. Through experiments on three representative tasks emphasizing physical consistency, we demonstrate its efficacy in enhancing physical fidelity. While our model still lacks a deep understanding of physics, our work offers one of the first empirical demonstrations that synthetic video enhances physical fidelity in video synthesis. Website: https://kevinz8866.github.io/simulation/
iMOVE: Instance-Motion-Aware Video Understanding
Feb 18, 2025



Enhancing the fine-grained instance spatiotemporal motion perception capabilities of Video Large Language Models is crucial for improving their temporal and general video understanding. However, current models struggle to perceive detailed and complex instance motions. To address these challenges, we have made improvements from both data and model perspectives. In terms of data, we have meticulously curated iMOVE-IT, the first large-scale instance-motion-aware video instruction-tuning dataset. This dataset is enriched with comprehensive instance motion annotations and spatiotemporal mutual-supervision tasks, providing extensive training for the model's instance-motion-awareness. Building on this foundation, we introduce iMOVE, an instance-motion-aware video foundation model that utilizes Event-aware Spatiotemporal Efficient Modeling to retain informative instance spatiotemporal motion details while maintaining computational efficiency. It also incorporates Relative Spatiotemporal Position Tokens to ensure awareness of instance spatiotemporal positions. Evaluations indicate that iMOVE excels not only in video temporal understanding and general video understanding but also demonstrates significant advantages in long-term video understanding.
VideoAuteur: Towards Long Narrative Video Generation
Jan 10, 2025



Recent video generation models have shown promising results in producing high-quality video clips lasting several seconds. However, these models face challenges in generating long sequences that convey clear and informative events, limiting their ability to support coherent narrations. In this paper, we present a large-scale cooking video dataset designed to advance long-form narrative generation in the cooking domain. We validate the quality of our proposed dataset in terms of visual fidelity and textual caption accuracy using state-of-the-art Vision-Language Models (VLMs) and video generation models, respectively. We further introduce a Long Narrative Video Director to enhance both visual and semantic coherence in generated videos and emphasize the role of aligning visual embeddings to achieve improved overall video quality. Our method demonstrates substantial improvements in generating visually detailed and semantically aligned keyframes, supported by finetuning techniques that integrate text and image embeddings within the video generation process. Project page: https://videoauteur.github.io/
TimeRefine: Temporal Grounding with Time Refining Video LLM
Dec 12, 2024



Video temporal grounding aims to localize relevant temporal boundaries in a video given a textual prompt. Recent work has focused on enabling Video LLMs to perform video temporal grounding via next-token prediction of temporal timestamps. However, accurately localizing timestamps in videos remains challenging for Video LLMs when relying solely on temporal token prediction. Our proposed TimeRefine addresses this challenge in two ways. First, instead of directly predicting the start and end timestamps, we reformulate the temporal grounding task as a temporal refining task: the model first makes rough predictions and then refines them by predicting offsets to the target segment. This refining process is repeated multiple times, through which the model progressively self-improves its temporal localization accuracy. Second, to enhance the model's temporal perception capabilities, we incorporate an auxiliary prediction head that penalizes the model more if a predicted segment deviates further from the ground truth, thus encouraging the model to make closer and more accurate predictions. Our plug-and-play method can be integrated into most LLM-based temporal grounding approaches. The experimental results demonstrate that TimeRefine achieves 3.6% and 5.0% mIoU improvements on the ActivityNet and Charades-STA datasets, respectively. Code and pretrained models will be released.
Towards Automated Model Design on Recommender Systems
Nov 12, 2024The increasing popularity of deep learning models has created new opportunities for developing AI-based recommender systems. Designing recommender systems using deep neural networks requires careful architecture design, and further optimization demands extensive co-design efforts on jointly optimizing model architecture and hardware. Design automation, such as Automated Machine Learning (AutoML), is necessary to fully exploit the potential of recommender model design, including model choices and model-hardware co-design strategies. We introduce a novel paradigm that utilizes weight sharing to explore abundant solution spaces. Our paradigm creates a large supernet to search for optimal architectures and co-design strategies to address the challenges of data multi-modality and heterogeneity in the recommendation domain. From a model perspective, the supernet includes a variety of operators, dense connectivity, and dimension search options. From a co-design perspective, it encompasses versatile Processing-In-Memory (PIM) configurations to produce hardware-efficient models. Our solution space's scale, heterogeneity, and complexity pose several challenges, which we address by proposing various techniques for training and evaluating the supernet. Our crafted models show promising results on three Click-Through Rates (CTR) prediction benchmarks, outperforming both manually designed and AutoML-crafted models with state-of-the-art performance when focusing solely on architecture search. From a co-design perspective, we achieve 2x FLOPs efficiency, 1.8x energy efficiency, and 1.5x performance improvements in recommender models.
* Accepted in ACM Transactions on Recommender Systems. arXiv admin note: substantial text overlap with arXiv:2207.07187
A Survey: Collaborative Hardware and Software Design in the Era of Large Language Models
Oct 08, 2024

The rapid development of large language models (LLMs) has significantly transformed the field of artificial intelligence, demonstrating remarkable capabilities in natural language processing and moving towards multi-modal functionality. These models are increasingly integrated into diverse applications, impacting both research and industry. However, their development and deployment present substantial challenges, including the need for extensive computational resources, high energy consumption, and complex software optimizations. Unlike traditional deep learning systems, LLMs require unique optimization strategies for training and inference, focusing on system-level efficiency. This paper surveys hardware and software co-design approaches specifically tailored to address the unique characteristics and constraints of large language models. This survey analyzes the challenges and impacts of LLMs on hardware and algorithm research, exploring algorithm optimization, hardware design, and system-level innovations. It aims to provide a comprehensive understanding of the trade-offs and considerations in LLM-centric computing systems, guiding future advancements in AI. Finally, we summarize the existing efforts in this space and outline future directions toward realizing production-grade co-design methodologies for the next generation of large language models and AI systems.
Latent Diffusion Model-Enabled Real-Time Semantic Communication Considering Semantic Ambiguities and Channel Noises
Jun 09, 2024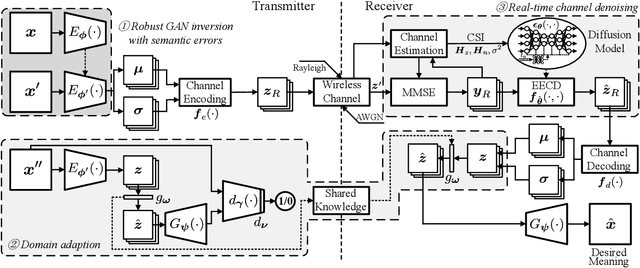
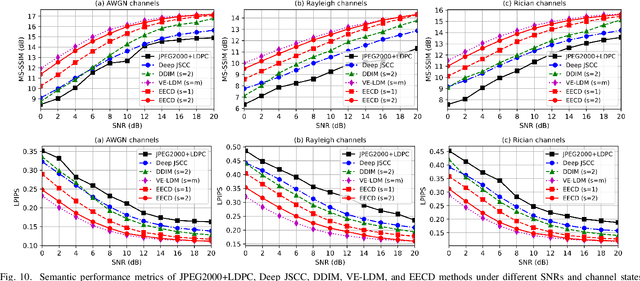
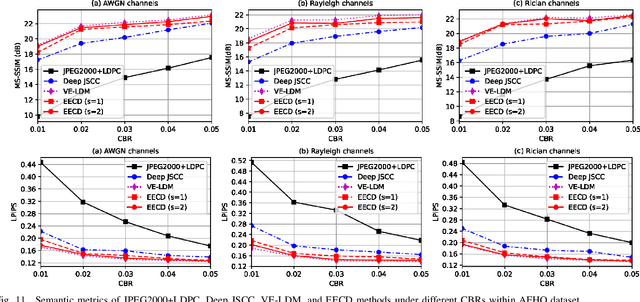
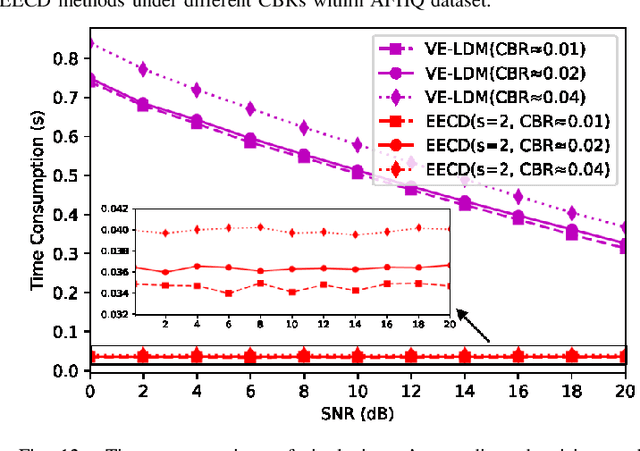
Semantic communication (SemCom) has emerged as a new paradigm for communication systems, with deep learning (DL) models being one of the key drives to shift from the accuracy of bit/symbol to the semantics and pragmatics of data. Nevertheless, DL-based SemCom systems often face performance bottlenecks due to overfitting, poor generalization, and sensitivity to outliers. Furthermore, the varying-fading gains and noises with uncertain signal-to-noise ratios (SNRs) commonly present in wireless channels usually restrict the accuracy of semantic information transmission. Consequently, to address the aforementioned issues, this paper constructs a SemCom system based on the latent diffusion model, and proposes three improvements compared to existing works: i) To handle potential outliers in the source data, semantic errors obtained by projected gradient descent based on the vulnerabilities of DL models, are utilized to update the parameters and obtain an outlier-robust encoder. ii) A lightweight single-layer latent space transformation adapter completes one-shot learning at transmitter and is placed before the decoder at receiver, enabling adaptation for out-of-distribution data or enhancing human-perceptual quality. iii) An end-to-end consistency distillation (EECD) strategy is used to distill the diffusion models trained in latent space, enabling deterministic single or few-step real-time denoising in various noisy channels while maintaining high semantic quality. Extensive numerical experiments across different datasets demonstrate the superiority of the proposed SemCom system, consistently proving its robustness to outliers, the capability to transmit data with unknown distributions, and the ability to perform real-time channel denoising tasks while preserving high human perceptual quality, outperforming the existing denoising approaches in semantic metrics such as MS-SSIM and LPIPS.